Chương 7: Các câu lệnh truy vấn phức tạp, triggers, views và sửa đổi lược đồ

Chương này mô tả các tính năng nâng cao hơn của ngôn ngữ SQL cho cơ sở dữ liệu quan hệ. Chúng ta bắt đầu ở Phần 7.1 bằng cách trình bày các tính năng phức tạp hơn của truy vấn truy xuất SQL, chẳng hạn như truy vấn lồng nhau, inner join, outer join, hàm tổng hợp, group by và câu lệnh CASE. Trong Phần 7.2, chúng tôi mô tả câu lệnh CREATE ASSERTION, cho phép đặc tả các ràng buộc tổng quát hơn trên cơ sở dữ liệu. Chúng tôi cũng giới thiệu khái niệm trigger và câu lệnh CREATE TRIGGER, sẽ được trình bày chi tiết hơn trong Phần 26.1 khi chúng tôi trình bày các nguyên tắc hoạt động của cơ sở dữ liệu. Sau đó, trong Phần 7.3, chúng tôi mô tả cơ sở SQL để xác định các views trên cơ sở dữ liệu. Các views còn được gọi là bảng ảo hoặc bảng dẫn xuất vì chúng hiển thị cho người dùng những gì có vẻ là bảng; tuy nhiên, thông tin trong các bảng đó được lấy từ các bảng đã xác định trước đó. Phần 7.4 giới thiệu câu lệnh SQL ALTER TABLE, được sử dụng để sửa đổi các bảng cơ sở dữ liệu và các ràng buộc. Sau cùng là tóm tắt chương
1. Câu lệnh truy vấn phức tạp
Trong Phần 6.3, chúng ta đã mô tả một số kiểu truy vấn truy xuất cơ bản trong SQL. Do tính tổng quát và khả năng diễn đạt của ngôn ngữ, nên có nhiều tính năng bổ sung cho phép người dùng chỉ định các truy xuất phức tạp hơn từ cơ sở dữ liệu. Chúng ta thảo luận về một số tính năng này trong phần này.
1.1 So sánh liên quan đến NULL và logic ba giá trị
SQL có nhiều quy tắc khác nhau để xử lý các giá trị NULL. Nhớ lại từ Mục 5.1.2 rằng NULL được sử dụng để biểu thị một giá trị bị thiếu, nhưng nó thường có một trong ba cách hiểu khác nhau—giá trị không xác định (giá trị tồn tại nhưng không được biết hoặc không biết giá trị có tồn tại hay không) , giá trị không khả dụng (giá trị tồn tại nhưng được giữ lại theo mục đích) hoặc giá trị không áp dụng (thuộc tính không áp dụng cho bộ này hoặc không được xác định cho bộ này). Xem xét các ví dụ sau để minh họa từng ý nghĩa của NULL
- Giá trị không xác định. Ngày sinh của một người không được biết, vì vậy nó được biểu thị bằng NULL trong cơ sở dữ liệu. Một ví dụ về trường hợp không xác định khác sẽ là NULL cho điện thoại nhà của một người vì không biết người đó có điện thoại nhà hay không
- Giá trị không có sẵn hoặc bị giữ lại. Một người có điện thoại nhà nhưng không muốn nó được liệt kê, vì vậy nó được giữ lại và biểu thị dưới dạng NULL trong cơ sở dữ liệu.
- Không áp dụng thuộc tính. Thuộc tính LastCollegeDegree sẽ là NULL cho một người không có bằng đại học vì nó không áp dụng cho người đó.
Thường không thể xác định ý nghĩa nào được dự định; ví dụ: NULL cho điện thoại nhà của một người có thể có bất kỳ nghĩa nào trong ba nghĩa. Do đó, SQL không phân biệt giữa các ý nghĩa khác nhau của NULL.
Nói chung, mỗi giá trị NULL riêng lẻ được coi là khác với mọi giá trị NULL khác trong các bản ghi cơ sở dữ liệu khác nhau. Khi một bản ghi có NULL ở một trong các thuộc tính của nó tham gia vào thao tác so sánh, kết quả được coi là UNKNOWN (có thể TRUE hoặc có thể FALSE). Do đó, SQL sử dụng logic ba giá trị với các giá trị TRUE, FALSE và UNKNOWN thay vì logic hai giá trị (Boolean) tiêu chuẩn với các giá trị TRUE hoặc FALSE. Do đó, cần phải xác định kết quả (hoặc giá trị chân lý) của các biểu thức logic có ba giá trị khi các liên từ logic AND, OR và NOT được sử dụng. Bảng 7.1 cho thấy các giá trị kết quả.
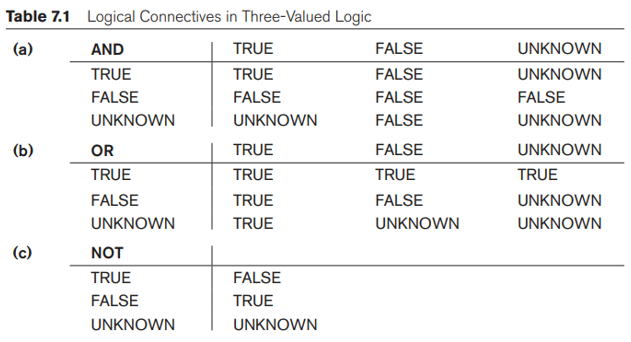
Trong Bảng 7.1(a) và 7.1(b), các hàng và cột biểu thị giá trị kết quả của các điều kiện so sánh, thường xuất hiện trong mệnh đề WHERE của truy vấn SQL. Mỗi kết quả biểu thức sẽ có giá trị TRUE, FALSE hoặc UNKNOWN. Kết quả của việc kết hợp hai giá trị bằng cách sử dụng liên kết logic AND được hiển thị bằng các mục trong Bảng 7.1(a). Bảng 7.1(b) cho thấy kết quả của việc sử dụng liên kết logic OR. Ví dụ: kết quả của (FALSE AND UNKNOWN) là FALSE, trong khi kết quả của (FALSE OR UNKNOWN) là UNKNOWN. Bảng 7.1(c) cho thấy kết quả của phép toán logic NOT. Lưu ý rằng trong logic Boolean tiêu chuẩn, chỉ cho phép các giá trị TRUE hoặc FALSE; không có giá trị UNKNOWN.
Trong truy vấn select-project-join, quy tắc chung là chỉ những tổ hợp bộ dữ liệu đánh giá biểu thức logic trong mệnh đề WHERE của truy vấn thành TRUE mới được chọn. Các kết hợp bộ đánh giá là FALSE hoặc UNKNOWN không được chọn. Tuy nhiên, có những ngoại lệ đối với quy tắc đó đối với một số thao tác nhất định, chẳng hạn như outer join, như chúng ta sẽ thấy trong phần dưới
SQL cho phép các truy vấn kiểm tra xem một giá trị thuộc tính có phải là NULL hay không. Thay vì sử dụng = hoặc <> để so sánh một giá trị thuộc tính với NULL, SQL sử dụng các toán tử so sánh IS hoặc IS NOT. Điều này là do SQL coi mỗi giá trị NULL là khác biệt với mọi giá trị NULL khác, vì vậy so sánh đẳng thức là không phù hợp. Theo đó, khi một điều kiện nối được chỉ định, các bộ có giá trị NULL cho các thuộc tính nối không được bao gồm trong kết quả (trừ khi đó là một OUTER JOIN). Truy vấn 18 minh họa so sánh NULL bằng cách truy xuất bất kỳ nhân viên nào không có người giám sát
Q18: SELECT Fname, Lname
FROM EMPLOYEE
WHERE Super_ssn IS NULL
1.2 Truy vấn lồng nhau, bộ dữ liệu và so sánh tập hợp/đa tập hợp
Một số truy vấn yêu cầu các giá trị hiện có trong cơ sở dữ liệu phải được tìm nạp và sau đó được sử dụng trong điều kiện so sánh. Các truy vấn như vậy có thể được xây dựng một cách thuận tiện bằng cách sử dụng các truy vấn lồng nhau, là các khối select-from-where hoàn chỉnh trong một truy vấn SQL khác. Truy vấn khác đó được gọi là truy vấn bên ngoài. Các truy vấn lồng nhau này cũng có thể xuất hiện trong mệnh đề WHERE hoặc mệnh đề FROM hoặc mệnh đề SELECT hoặc các mệnh đề SQL khác nếu cần. Truy vấn 4 được xây dựng trong Q4 mà không có truy vấn lồng nhau, nhưng nó có thể được viết lại để sử dụng các truy vấn lồng nhau như được trình bày trong Q4A. Q4A giới thiệu toán tử so sánh IN, so sánh một giá trị v với một tập hợp (hoặc nhiều tập hợp) giá trị V và đánh giá là TRUE nếu v là một trong các phần tử trong V.
Trong Q4A, truy vấn lồng nhau đầu tiên chọn số dự án của các dự án có nhân viên có họ 'Smith' tham gia với tư cách là người quản lý, trong khi truy vấn lồng nhau thứ hai chọn số dự án của các dự án có nhân viên có họ 'Smith' tham gia với tư cách là người quản lý công nhân. Trong truy vấn bên ngoài, chúng tôi sử dụng liên kết logic OR để truy xuất một bộ PROJECT nếu giá trị PNUMBER của bộ đó là kết quả của một trong hai truy vấn lồng nhau
Q4A: SELECT DISTINCT Pnumber
FROM PROJECT
WHERE Pnumber IN
( SELECT Pnumber
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE Dnum = Dnumber AND Mgr_ssn = Ssn AND Lname = ‘Smith’ )
OR Pnumber IN
( SELECT Pno
FROM WORKS_ON, EMPLOYEE
WHERE Essn = Ssn AND Lname = ‘Smith’ );
Nếu một truy vấn lồng nhau trả về một thuộc tính và một bộ đơn, thì kết quả truy vấn sẽ là một giá trị (vô hướng) đơn. Trong những trường hợp như vậy, được phép sử dụng = thay vì IN cho toán tử so sánh. Nói chung, truy vấn lồng nhau sẽ trả về một bảng (quan hệ), là một tập hợp hoặc nhiều bộ dữ liệu
SQL cho phép sử dụng các bộ giá trị để so sánh bằng cách đặt chúng trong dấu ngoặc đơn. Để minh họa điều này, hãy xem xét truy vấn sau:
SELECT DISTINCT Essn
FROM WORKS_ON
WHERE (Pno, Hours) IN ( SELECT Pno, Hours FROM WORKS_ON WHERE Essn = ‘123456789’ )
Truy vấn này sẽ chọn Bản chất của tất cả các nhân viên làm việc cùng một tổ hợp (Pno, Hours) trong một số dự án mà nhân viên 'John Smith' (có Ssn = '123456789') làm việc. Trong ví dụ này, toán tử IN so sánh bộ con của các giá trị trong dấu ngoặc đơn (Pno, Hours) trong mỗi bộ trong WORKS_ON với tập hợp các bộ tương thích kiểu do truy vấn lồng nhau tạo ra.
Ngoài toán tử IN, một số toán tử so sánh khác có thể được sử dụng để so sánh một giá trị đơn lẻ v (thường là tên thuộc tính) với một tập hợp hoặc nhiều tập hợp v (thường là một truy vấn lồng nhau). Toán tử = ANY (hoặc = SOME) trả về TRUE nếu giá trị v bằng một giá trị nào đó trong tập hợp V và do đó tương đương với IN. Hai từ khóa ANY và SOME có tác dụng giống nhau. Các toán tử khác có thể được kết hợp với ANY (hoặc SOME) nào bao gồm >, >=, <= và <>. Từ khóa ALL cũng có thể được kết hợp với từng toán tử này. Ví dụ: điều kiện so sánh (v > ALL V) trả về TRUE nếu giá trị v lớn hơn tất cả các giá trị trong tập hợp (hoặc nhiều tập hợp) V. Một ví dụ là truy vấn sau đây, trả về tên của nhân viên có mức lương lớn hơn hơn tiền lương của tất cả nhân viên trong bộ phận 5:
SELECT Lname, Fname
FROM EMPLOYEE
WHERE Salary > ALL ( SELECT Salary
FROM EMPLOYEE
WHERE Dno = 5 );
Lưu ý rằng truy vấn này cũng có thể được chỉ định bằng cách sử dụng hàm tổng hợp MAX giới thiệu ở phần tiếp theo sau
Nói chung, chúng ta có thể có một số mức truy vấn lồng nhau. Một lần nữa, chúng ta có thể phải đối mặt với vấn đề trùng lặp tên thuộc tính có thể xảy ra giữa các tên thuộc tính nếu các thuộc tính cùng tên tồn tại—một thuộc tính trong quan hệ trong mệnh đề FROM của truy vấn bên ngoài và một thuộc tính khác trong quan hệ trong mệnh đề FROM của truy vấn lồng nhau. Quy tắc là tham chiếu đến thuộc tính không đủ tiêu chuẩn tham chiếu đến mối quan hệ được khai báo trong truy vấn lồng nhau trong cùng. Ví dụ: trong mệnh đề SELECT và mệnh đề WHERE của truy vấn lồng nhau đầu tiên của Q4A, tham chiếu đến bất kỳ thuộc tính không đủ tiêu chuẩn nào của quan hệ PROJECT đề cập đến quan hệ PROJECT được chỉ định trong mệnh đề TỪ của truy vấn lồng nhau. Để tham chiếu đến một thuộc tính của quan hệ PROJECT được chỉ định trong truy vấn bên ngoài, chúng tôi chỉ định và tham chiếu đến một bí danh (biến bộ) cho quan hệ đó. Các quy tắc này tương tự như quy tắc đặt tên cho các biến chương trình trong hầu hết các ngôn ngữ lập trình cho phép các thủ tục và hàm lồng nhau. Để minh họa hãy xem xét Truy vấn 16.
Truy vấn 16: Truy xuất tên của từng nhân viên có người phụ thuộc có cùng tên và cùng giới tính với nhân viên.
Q16: SELECT E.Fname, E.Lname
FROM EMPLOYEE AS E
WHERE E.Ssn IN (
SELECT D.Essn
FROM DEPENDENT AS D
WHERE E.Fname = D.Dependent_name AND E.Sex = D.Sex );
Trong truy vấn lồng nhau của Q16, chúng ta phải định tính E.Sex vì nó đề cập đến thuộc tính Sex của EMPLOYEE từ truy vấn bên ngoài và DEPENDENT cũng có một thuộc tính gọi là Sex. Nếu có bất kỳ tham chiếu không đủ tiêu chuẩn nào đến Giới tính trong truy vấn lồng nhau, chúng sẽ tham chiếu đến thuộc tính Giới tính của DEPENDENT. Tuy nhiên, chúng ta sẽ không phải định tính các thuộc tính Fname và Ssn của EMPLOYEE nếu chúng xuất hiện trong truy vấn lồng nhau vì quan hệ DEPENDENT không có các thuộc tính được gọi là Fname và Ssn, do đó không có sự mơ hồ.
Thông thường nên tạo các biến bộ (bí danh) cho tất cả các bảng được tham chiếu trong truy vấn SQL để tránh các lỗi tiềm ẩn và sự mơ hồ, như được minh họa trong Q16
1.3 Truy vấn lồng nhau tương quan - correlated nested queries
Bất cứ khi nào một điều kiện trong mệnh đề WHERE của một truy vấn lồng nhau tham chiếu đến một số thuộc tính của một quan hệ được khai báo trong truy vấn bên ngoài, thì hai truy vấn đó được cho là tương quan với nhau. Chúng ta có thể hiểu truy vấn tương quan tốt hơn bằng cách xem xét rằng truy vấn lồng nhau được đánh giá một lần cho mỗi bộ (hoặc tổ hợp các bộ) trong truy vấn bên ngoài. Ví dụ: chúng ta có thể nghĩ về Q16 như sau: Đối với mỗi bộ EMPLOYEE, hãy đánh giá truy vấn lồng nhau, truy vấn này truy xuất các giá trị Essn cho tất cả các bộ DEPENDENT có cùng giới tính và đặt tên với bộ EMPLOYEE đó; nếu giá trị Ssn của bộ EMPLOYEE nằm trong kết quả của truy vấn lồng nhau, thì hãy chọn bộ EMPLOYEE đó.
Nói chung, một truy vấn được viết với các khối select-from-where lồng nhau và sử dụng toán tử so sánh = hoặc IN luôn có thể được biểu thị dưới dạng một truy vấn khối đơn. Ví dụ, Q16 có thể được viết như trong Q16A:
Q16A: SELECT E.Fname, E.Lname
FROM EMPLOYEE AS E, DEPENDENT AS D
WHERE E.Ssn = D.Essn AND E.Sex = D.Sex AND E.Fname = D.Dependent_name;
1.4 EXIST và UNIQUE trong SQL
EXISTS và UNIQUE là các hàm Boolean trả về TRUE hoặc FALSE; do đó, chúng có thể được sử dụng trong điều kiện mệnh đề WHERE. Hàm EXISTS trong SQL được sử dụng để kiểm tra xem kết quả của một truy vấn lồng nhau có rỗng (không chứa bộ dữ liệu nào) hay không. Kết quả của EXISTS là một giá trị Boolean TRUE nếu kết quả truy vấn lồng nhau chứa ít nhất một bộ hoặc FALSE nếu kết quả truy vấn lồng nhau không chứa bộ nào. Chúng tôi minh họa việc sử dụng EXISTS—và NOT EXISTS—với một số ví dụ. Đầu tiên, chúng tôi xây dựng Truy vấn 16 ở dạng thay thế sử dụng EXISTS như trong Q16B:
Q16B: SELECT E.Fname, E.Lname
FROM EMPLOYEE AS E
WHERE EXISTS (
SELECT *
FROM DEPENDENT AS D
WHERE E.Ssn = D.Essn AND E.Sex = D.Sex AND E.Fname = D.Dependent_name);
EXISTS và NOT EXISTS thường được sử dụng cùng với truy vấn lồng nhau tương quan. Trong Q16B, truy vấn lồng nhau tham chiếu đến các thuộc tính Ssn, Fname và Sex của quan hệ EMPLOYEE từ truy vấn bên ngoài. Chúng ta có thể nghĩ về Q16B như sau: Đối với mỗi bộ EMPLOYEE, hãy đánh giá truy vấn lồng nhau, truy vấn này truy xuất tất cả các bộ DEPENDENT có cùng Essn, Sex và Dependent_name như bộ EMPLOYEE; nếu ít nhất một bộ EXISTS trong kết quả của truy vấn lồng nhau, thì hãy chọn bộ EMPLOYEE đó. EXISTS(Q) trả về TRUE nếu có ít nhất một bộ trong kết quả của truy vấn lồng nhau Q và trả về FALSE nếu không. Mặt khác, NOT EXISTS(Q) trả về TRUE nếu không có bộ nào trong kết quả của truy vấn lồng Q và trả về FALSE nếu không. Tiếp theo, chúng tôi minh họa việc sử dụng NOT EXISTS.
Truy vấn 6: Lấy ra tên nhân viên không có người phụ thuộc
Q6: SELECT Fname, Lname
FROM EMPLOYEE
WHERE NOT EXISTS (
SELECT *
FROM DEPENDENT
WHERE Ssn = Essn );
Trong Q6, truy vấn lồng nhau tương quan truy xuất tất cả các bộ dữ liệu DEPENDENT liên quan đến một bộ dữ liệu EMPLOYEE cụ thể. Nếu không tồn tại, bộ EMPLOYEE được chọn vì điều kiện của mệnh đề WHERE sẽ đánh giá là TRUE trong trường hợp này. Chúng ta có thể giải thích Q6 như sau: Đối với mỗi bộ EMPLOYEE, truy vấn lồng nhau tương quan chọn tất cả các bộ DEPENDENT có giá trị Essn khớp với EMPLOYEE Ssn; nếu kết quả trống, không có người phụ thuộc nào liên quan đến nhân viên, vì vậy chúng tôi chọn bộ EMPLOYEE đó và truy xuất Fname và Lname của nó.
Q7: SELECT Fname, Lname
FROM EMPLOYEE
WHERE EXISTS (
SELECT *
FROM DEPENDENT
WHERE Ssn = Essn )
AND EXISTS (
SELECT *
FROM DEPARTMENT
WHERE Ssn = Mgr_ssn );
Một cách để viết truy vấn này được hiển thị trong Q7, trong đó chúng tôi chỉ định hai truy vấn tương quan lồng nhau; cái đầu tiên chọn tất cả các bộ DEPENDENT liên quan đến EMPLOYEE, và cái thứ hai chọn tất cả các bộ DEPARTMENT do EMPLOYEE quản lý. Nếu ít nhất một trong số thứ nhất và ít nhất một trong số thứ hai tồn tại, chúng tôi chọn bộ EMPLOYEE. Bạn có thể viết lại truy vấn này chỉ bằng một truy vấn lồng nhau hoặc không có truy vấn lồng nhau nào không?
Có một hàm SQL khác, UNIQUE(Q), trả về TRUE nếu không có bộ dữ liệu trùng lặp nào trong kết quả của truy vấn Q; ngược lại, nó trả về FALSE. Điều này có thể được sử dụng để kiểm tra xem kết quả của một truy vấn lồng nhau là một bộ (không trùng lặp) hay nhiều bộ (tồn tại trùng lặp)
1.5 Đặt lại tên
Chúng ta đã thấy một số truy vấn có truy vấn lồng nhau trong mệnh đề WHERE. Cũng có thể sử dụng một tập giá trị rõ ràng trong mệnh đề WHERE, thay vì truy vấn lồng nhau. Một tập hợp như vậy được đặt trong dấu ngoặc đơn trong SQL
Truy vấn 17. Truy xuất số An sinh xã hội của tất cả nhân viên làm việc trong dự án số 1, 2 hoặc 3
Q17: SELECT DISTINCT Essn
FROM WORKS_ON
WHERE Pno IN (1, 2, 3);
Trong SQL, có thể đổi tên bất kỳ thuộc tính nào xuất hiện trong kết quả của truy vấn bằng cách thêm từ hạn định AS theo sau là tên mới mong muốn. Do đó, cấu trúc AS có thể được sử dụng để đặt bí danh cho cả tên thuộc tính và tên quan hệ nói chung và nó có thể được sử dụng trong các phần thích hợp của truy vấn. Ví dụ: Q8A cho thấy cách truy vấn Q8 có thể được thay đổi một chút để truy xuất họ của từng nhân viên và người giám sát của họ trong khi đổi tên các tên thuộc tính kết quả thành Employee_name và Supervisor_name. Các tên mới sẽ xuất hiện dưới dạng tiêu đề cột cho kết quả truy vấn.
Q8A: SELECT E.Lname AS Employee_name, S.Lname AS Supervisor_name
FROM EMPLOYEE AS E, EMPLOYEE AS S
WHERE E.Super_ssn = S.Ssn;
1.6 INNER JOIN và OUTER JOIN
Khái niệm bảng joined (hoặc quan hệ joined) được tích hợp vào SQL để cho phép người dùng chỉ định một bảng do phép kết trong mệnh đề FROM của truy vấn. Cấu trúc này có thể dễ hiểu hơn là trộn tất cả các điều kiện chọn và nối trong mệnh đề WHERE lại với nhau. Ví dụ: xem xét truy vấn Q1, truy vấn này truy xuất tên và địa chỉ của mọi nhân viên làm việc cho bộ phận 'Research’. Có thể dễ dàng hơn khi chỉ định phép kết của quan hệ EMPLOYEE và DEPARTMENT trong mệnh đề WHERE, sau đó chọn các bộ và thuộc tính mong muốn. Điều này có thể được viết bằng SQL như trong Q1A:
Q1A: SELECT Fname, Lname, Address
FROM (EMPLOYEE JOIN DEPARTMENT ON Dno = Dnumber)
WHERE Dname = ‘Research’;
Mệnh đề FROM trong Q1A chứa một bảng joined. Các thuộc tính của một bảng như vậy là tất cả các thuộc tính của bảng đầu tiên, EMPLOYEE, theo sau là tất cả các thuộc tính của bảng thứ hai, DEPARTMENT. Khái niệm về một bảng joined cũng cho phép người dùng chỉ định các kiểu nối khác nhau, chẳng hạn như NATURAL JOIN và các kiểu của OUTER JOIN. Trong NATURAL JOIN trên hai quan hệ R và S, không có điều kiện nối nào được chỉ định; một điều kiện EQUIJOIN ngầm cho mỗi cặp thuộc tính có cùng tên từ R và S được tạo. Mỗi cặp thuộc tính như vậy chỉ được bao gồm một lần trong quan hệ kết quả
Nếu tên của các thuộc tính nối không giống nhau trong các quan hệ cơ sở, thì có thể đổi tên các thuộc tính sao cho chúng khớp với nhau, sau đó áp dụng NATURAL JOIN. Trong trường hợp này, cấu trúc AS có thể được sử dụng để đổi tên một quan hệ và tất cả các thuộc tính của nó trong mệnh đề TỪ. Điều này được minh họa trong Q1B, trong đó quan hệ DEPARTMENT được đổi tên thành DEPT và các thuộc tính của nó được đổi tên thành Dname, Dno (để khớp với tên của thuộc tính nối mong muốn Dno trong bảng EMPLOYEE), Mssn và Msdate. Điều kiện tham gia ngụ ý cho NATURAL JOIN này là EMPLOYEE.Dno = DEPT.Dno, vì đây là cặp thuộc tính duy nhất có cùng tên sau khi đổi tên:
Q1B: SELECT Fname, Lname, Address
FROM (EMPLOYEE NATURAL JOIN (DEPARTMENT AS DEPT (Dname, Dno, Mssn, Msdate))) WHERE Dname = ‘Research’;
Kiểu join mặc định trong một bảng joined được gọi là inner join, trong đó một bộ được bao gồm trong kết quả chỉ khi một bộ phù hợp tồn tại trong quan hệ khác. Ví dụ: trong truy vấn Q8A, chỉ những nhân viên có người giám sát mới được đưa vào kết quả; một bộ EMPLOYEE có giá trị cho Super_ssn là NULL bị loại trừ. Nếu người dùng yêu cầu bao gồm tất cả nhân viên, thì phải sử dụng một loại phép kết khác gọi là OUTER JOIN. Có một số biến thể của OUTER JOIN chúng ta sẽ tim hiểu bên dưới. Trong tiêu chuẩn SQL, điều này được xử lý bằng cách chỉ định rõ ràng từ khóa OUTER JOIN trong một bảng joined, như được minh họa trong Q8B:
Q8B: SELECT E.Lname AS Employee_name, S.Lname AS Supervisor_name
FROM (EMPLOYEE AS E LEFT OUTER JOIN EMPLOYEE AS S ON E.Super_ssn = S.Ssn);
Trong SQL, các tùy chọn có sẵn để chỉ định các bảng joined bao gồm INNER JOIN (chỉ các cặp bộ khớp với điều kiện nối mới được truy xuất, giống như JOIN), LEFT OUTER JOIN (mọi bộ trong bảng bên trái phải xuất hiện trong kết quả; nếu có không có bộ phù hợp, nó được đệm bằng các giá trị NULL cho các thuộc tính của bảng bên phải), RIGHT OUTER JOIN (mọi bộ trong bảng bên phải phải xuất hiện trong kết quả; nếu nó không có bộ phù hợp, nó sẽ được đệm bằng các giá trị NULL cho các thuộc tính của bảng bên trái) và FULL OUTER JOIN. Trong ba tùy chọn sau, từ khóa OUTER có thể được bỏ qua. Nếu các thuộc tính nối có cùng tên, người ta cũng có thể chỉ định biến thể phép kết tự nhiên của outer join bằng cách sử dụng từ khóa NATURAL trước thao tác (ví dụ: NATURAL LEFT OUTER JOIN). Từ khóa CROSS JOIN được sử dụng để chỉ định hoạt động CARTESIAN PRODUCT (trình bày ở chương tiếp theo), mặc dù điều này chỉ nên được sử dụng hết sức cẩn thận vì nó tạo ra tất cả các kết hợp bộ có thể có.
Cũng có thể lồng các bảng joined với nhau; nghĩa là, một trong các bảng trong một phép kết có thể chính là một bảng joined. Điều này cho phép bạn sử dụng phép kết của ba hoặc nhiều bảng dưới dạng một bảng joined duy nhất, được gọi là phép kết nhiều. Ví dụ: Q2A là một cách khác để chỉ định truy vấn Q2 từ bài trước bằng cách sử dụng khái niệm bảng đã joined:
Q2A: SELECT Pnumber, Dnum, Lname, Address, Bdate
FROM ((PROJECT JOIN DEPARTMENT ON Dnum = Dnumber)
JOIN EMPLOYEE ON Mgr_ssn = Ssn)
WHERE Plocation = ‘Stafford’;
Không phải tất cả các triển khai SQL đã triển khai cú pháp mới của các bảng joined. Trong một số hệ thống, một cú pháp khác đã được sử dụng để chỉ định phép kết ngoài bằng cách sử dụng các toán tử so sánh + =, = + và + = + tương ứng cho left, right, và full outer join khi chỉ định điều kiện kết. Ví dụ, cú pháp này có sẵn trong Oracle. Để chỉ định left outer join trong Q8B bằng cú pháp này, chúng ta có thể viết truy vấn Q8C như sau:
Q8C: SELECT E.Lname, S.Lname
FROM EMPLOYEE E, EMPLOYEE S
WHERE E.Super_ssn + = S.Ssn;
1.7 Hàm tổng hợp (thống kê) trong SQL
Các hàm tổng hợp được sử dụng để tóm tắt thông tin từ nhiều bộ thành một bản tóm tắt một bộ. GROUP được sử dụng để tạo các nhóm con của bộ dữ liệu trước khi tóm tắt. GROUP và tổng hợp được yêu cầu trong nhiều ứng dụng cơ sở dữ liệu và chúng tôi sẽ giới thiệu việc sử dụng chúng trong SQL thông qua các ví dụ. Một số hàm tổng hợp tích hợp tồn tại: COUNT, SUM, MAX, MIN và AVG. 2 Hàm COUNT trả về số bộ hoặc giá trị như đã chỉ định trong truy vấn. Các hàm SUM, MAX, MIN và AVG có thể được áp dụng cho một tập hợp hoặc nhiều tập hợp các giá trị số và trả về tương ứng tổng, giá trị lớn nhất, giá trị nhỏ nhất và trung bình của các giá trị đó. Các hàm này có thể được sử dụng trong mệnh đề SELECT hoặc trong mệnh đề HAVING (chúng tôi sẽ giới thiệu sau). Các hàm MAX và MIN cũng có thể được sử dụng với các thuộc tính có miền không phải là số nếu các giá trị miền có thứ tự tổng cộng với nhau. Chúng tôi minh họa việc sử dụng các hàm này bằng một số truy vấn
Truy vấn 19: Tìm tổng tiền lương của tất cả nhân viên, mức lương tối đa, mức lương tối thiểu và mức lương trung bình
Q19: SELECT SUM (Salary), MAX (Salary), MIN (Salary), AVG (Salary)
FROM EMPLOYEE;
Truy vấn này trả về một bản tóm tắt một hàng của tất cả các hàng trong bảng NHÂN VIÊN. Chúng ta có thể sử dụng AS để đổi tên các tên cột trong bảng một hàng kết quả; ví dụ, như trong Q19A.
Q19A: SELECT SUM (Salary) AS Total_Sal,
MAX (Salary) AS Highest_Sal,
MIN (Salary) AS Lowest_Sal,
AVG (Salary) AS Average_Sal
FROM EMPLOYEE;
Nếu chúng ta muốn lấy các giá trị hàm tổng hợp trước cho các nhân viên của một bộ phận cụ thể—chẳng hạn, bộ phận 'Research’, chúng ta có thể viết Truy vấn 20, trong đó các bộ dữ liệu EMPLOYEE bị hạn chế bởi mệnh đề WHERE đối với những nhân viên làm việc cho bộ phận ’Research'.
Truy vấn 20: Tìm tổng lương của tất cả nhân viên của bộ phận ’Research', cũng như mức lương tối đa, mức lương tối thiểu và mức lương trung bình trong bộ phận này.
Q20: SELECT SUM (Salary),
MAX (Salary),
MIN (Salary),
AVG (Salary)
FROM (EMPLOYEE JOIN DEPARTMENT ON Dno = Dnumber)
WHERE Dname = ‘Research’;
Truy vấn 21 và 22: Lấy tổng số nhân viên trong công ty (Q21) và số nhân viên trong bộ phận ‘Research’ (Q22).
Q21: SELECT COUNT (*)
FROM EMPLOYEE;
Q22: SELECT COUNT (*)
FROM EMPLOYEE, DEPARTMENT
WHERE DNO = DNUMBER AND DNAME = ‘Research’;
Ở đây, dấu hoa thị (*) đề cập đến các hàng (bộ dữ liệu), vì vậy COUNT (*) trả về số hàng trong kết quả của truy vấn. Chúng ta cũng có thể sử dụng hàm COUNT để đếm các giá trị trong một cột thay vì các bộ, như trong ví dụ tiếp theo..
Truy vấn 23: Đếm số lượng giá trị lương riêng biệt trong cơ sở dữ liệu
Q23: SELECT COUNT (DISTINCT Salary)
FROM EMPLOYEE;
Nếu chúng ta viết COUNT(SALARY) thay vì COUNT(SALARY DISTINCT) trong Q23, thì các giá trị trùng lặp sẽ không bị loại bỏ. Tuy nhiên, bất kỳ bộ dữ liệu nào có NULL cho SALARY sẽ không được tính. Nói chung, các giá trị NULL bị loại bỏ khi các hàm tổng hợp được áp dụng cho một cột (thuộc tính) cụ thể; ngoại lệ duy nhất dành cho COUNT(*) vì các bộ thay vì các giá trị được tính. Trong các ví dụ trước, bất kỳ giá trị Lương nào là NULL đều không được bao gồm trong phép tính hàm tổng hợp. Quy tắc chung như sau: khi một hàm tổng hợp được áp dụng cho một tập hợp các giá trị, NULL sẽ bị xóa khỏi tập hợp trước khi tính toán; nếu tập hợp trở nên trống vì tất cả các giá trị đều là NULL, thì hàm tổng hợp sẽ trả về NULL (ngoại trừ trường hợp COUNT, trong đó nó sẽ trả về 0 cho tập hợp giá trị trống).
Các ví dụ trước tóm tắt toàn bộ quan hệ (Q19, Q21, Q23) hoặc một tập hợp con được chọn của các bộ (Q20, Q22), và do đó tất cả tạo ra một bảng có một hàng hoặc một giá trị. Chúng minh họa cách các hàm được áp dụng để truy xuất một giá trị tóm tắt hoặc bộ dữ liệu tóm tắt từ một bảng. Các chức năng này cũng có thể được sử dụng trong các điều kiện lựa chọn liên quan đến các truy vấn lồng nhau. Chúng ta có thể chỉ định một truy vấn lồng nhau tương quan với một hàm tổng hợp, sau đó sử dụng truy vấn lồng nhau trong mệnh đề WHERE của một truy vấn bên ngoài. Ví dụ: để truy xuất tên của tất cả nhân viên có từ hai người phụ thuộc trở lên (Truy vấn 5), chúng ta có thể viết như sau:
Q5: SELECT Lname, Fname
FROM EMPLOYEE
WHERE (
SELECT COUNT (*)
FROM DEPENDENT
WHERE Ssn = Essn ) > = 2;
Truy vấn lồng nhau tương quan đếm số lượng người phụ thuộc mà mỗi nhân viên có; nếu giá trị này lớn hơn hoặc bằng hai, thì bộ dữ liệu nhân viên được chọn.
SQL cũng có các hàm tổng hợp SOME và ALL có thể được áp dụng cho tập hợp các giá trị Boolean; SOME trả về TRUE nếu ít nhất một phần tử trong bộ sưu tập là TRUE, trong khi ALL trả về TRUE nếu tất cả các phần tử trong bộ sưu tập là TRUE.
1.8 Mệnh đề GROUP BY và HAVING
Trong nhiều trường hợp, chúng ta muốn áp dụng các hàm tổng hợp cho các nhóm con của các bộ trong một quan hệ, trong đó các nhóm con dựa trên một số giá trị thuộc tính. Ví dụ: chúng ta có thể muốn tìm mức lương trung bình của nhân viên trong từng bộ phận hoặc số lượng nhân viên làm việc trong từng dự án. Trong những trường hợp này, chúng ta cần phân vùng quan hệ thành các tập con (hoặc nhóm) không chồng lấp của các bộ. Mỗi nhóm (phân vùng) sẽ bao gồm các bộ có cùng giá trị của (các) thuộc tính, được gọi là (các) thuộc tính nhóm. Sau đó, chúng ta có thể áp dụng hàm này cho từng nhóm như vậy một cách độc lập để tạo ra thông tin tóm tắt về từng nhóm. SQL có mệnh đề GROUP BY cho mục đích này. Mệnh đề GROUP BY chỉ định các thuộc tính nhóm, thuộc tính này cũng sẽ xuất hiện trong mệnh đề SELECT để giá trị có được từ việc áp dụng từng hàm tổng hợp cho một nhóm các bộ xuất hiện cùng với giá trị của (các) thuộc tính nhóm.
Truy vấn 24: Đối với mỗi bộ phận, hãy truy xuất số bộ phận, số lượng nhân viên trong bộ phận và mức lương trung bình của họ.
Q24: SELECT Dno, COUNT (*), AVG (Salary)
FROM EMPLOYEE
GROUP BY Dno;
Trong Q24, các bộ EMPLOYEE được phân vùng thành các nhóm—mỗi nhóm có cùng giá trị cho thuộc tính GROUP BY Dno. Do đó, mỗi nhóm bao gồm các nhân viên làm việc trong cùng một bộ phận. Các hàm COUNT và AVG được áp dụng cho từng nhóm bộ dữ liệu như vậy. Lưu ý rằng mệnh đề SELECT chỉ bao gồm thuộc tính nhóm và các hàm tổng hợp được áp dụng cho từng nhóm bộ. Hình 7.1(a) minh họa cách nhóm hoạt động và hiển thị kết quả của Q24U
Nếu NULL tồn tại trong thuộc tính nhóm, thì một nhóm riêng được tạo cho tất cả các bộ có giá trị NULL trong thuộc tính nhóm. Ví dụ: nếu bảng EMPLOYEE có một số bộ có NULL cho thuộc tính nhóm Dno, thì sẽ có một nhóm riêng cho các bộ đó trong kết quả của Q24
Truy vấn 25: Đối với mỗi dự án, hãy truy xuất số dự án, tên dự án và số lượng nhân viên làm việc trong dự án đó.
Q25: SELECT Pnumber, Pname, COUNT (*)
FROM PROJECT, WORKS_ON
WHERE Pnumber = Pno GROUP BY Pnumber, Pname;
Q25 cho thấy cách chúng ta có thể sử dụng điều kiện nối kết hợp với GROUP BY. Trong trường hợp này, nhóm và hàm được áp dụng sau khi nối hai quan hệ trong mệnh đề WHERE.
Đôi khi chúng ta chỉ muốn truy xuất các giá trị của các hàm này cho các nhóm thỏa mãn các điều kiện nhất định. Ví dụ: giả sử rằng chúng tôi muốn sửa đổi Truy vấn 25 để chỉ các dự án có nhiều hơn hai nhân viên xuất hiện trong kết quả. SQL cung cấp mệnh đề HAVING, mệnh đề này có thể xuất hiện cùng với mệnh đề GROUP BY, cho mục đích này. HAVING cung cấp một điều kiện về thông tin tóm tắt liên quan đến nhóm các bộ được liên kết với từng giá trị của các thuộc tính nhóm. Chỉ những nhóm thỏa mãn điều kiện mới được truy xuất trong kết quả của truy vấn. Điều này được minh họa bởi Truy vấn 26
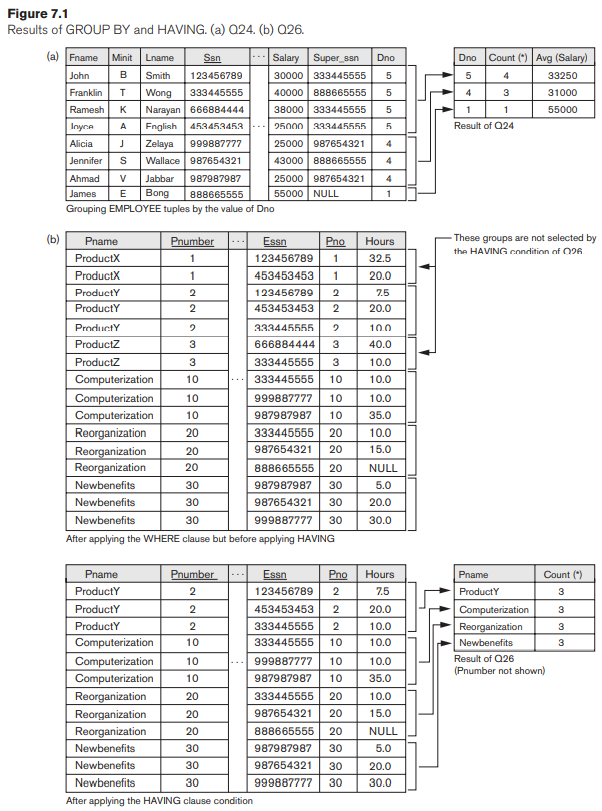
Truy vấn 26. Đối với mỗi dự án có nhiều hơn hai nhân viên làm việc, hãy truy xuất số dự án, tên dự án và số lượng nhân viên làm việc trong dự án.
Q26: SELECT Pnumber, Pname, COUNT (*)
FROM PROJECT, WORKS_ON WHERE Pnumber = Pno
GROUP BY Pnumber, Pname
HAVING COUNT (*) > 2;
Lưu ý rằng mặc dù các điều kiện lựa chọn trong mệnh đề WHERE giới hạn các bộ mà hàm được áp dụng, nhưng mệnh đề HAVING dùng để chọn cả nhóm. Hình 7.1(b) minh họa việc sử dụng HAVING và hiển thị kết quả của Q26.
Truy vấn 27: Đối với mỗi dự án, lấy số dự án, tên dự án và số lượng nhân viên từ bộ phận 5 làm việc trong dự án
Q27: SELECT Pnumber, Pname, COUNT (*)
FROM PROJECT, WORKS_ON, EMPLOYEE
WHERE Pnumber = Pno AND Ssn = Essn AND Dno = 5
GROUP BY Pnumber, Pname;
Trong Q27, chúng ta hạn chế các bộ trong quan hệ (và do đó các bộ trong mỗi nhóm) ở những bộ thỏa mãn điều kiện được chỉ định trong mệnh đề WHERE—cụ thể là chúng hoạt động trong bộ phận số 5. Lưu ý rằng chúng ta phải hết sức cẩn thận khi hai các điều kiện khác nhau được áp dụng (một cho hàm tổng hợp trong mệnh đề SELECT và một cho hàm trong mệnh đề HAVING). Ví dụ: giả sử rằng chúng tôi muốn đếm tổng số nhân viên có mức lương vượt quá 40.000 đô la trong mỗi bộ phận, nhưng chỉ đối với các bộ phận có hơn năm nhân viên làm việc. Ở đây, điều kiện (SALARY > 40000) chỉ áp dụng cho hàm COUNT trong mệnh đề SELECT. Giả sử rằng chúng tôi viết truy vấn không chính xác sau đây:
SELECT Dno, COUNT (*)
FROM EMPLOYEE
WHERE Salary>40000
GROUP BY Dno
HAVING COUNT (*) > 5;
Điều này không chính xác vì nó sẽ chỉ chọn các bộ phận có hơn năm nhân viên, mỗi người kiếm được hơn 40.000 đô la. Quy tắc là mệnh đề WHERE được thực thi trước, để chọn các bộ dữ liệu riêng lẻ hoặc các bộ dữ liệu đã tham gia; mệnh đề HAVING được áp dụng sau, để chọn các nhóm bộ dữ liệu riêng lẻ. Trong truy vấn không chính xác, các bộ dữ liệu đã bị hạn chế đối với những nhân viên kiếm được hơn 40.000 đô la trước khi hàm trong mệnh đề HAVING được áp dụng. Một cách để viết truy vấn này một cách chính xác là sử dụng truy vấn lồng nhau, như được hiển thị trong Truy vấn 28.
Truy vấn 28: Đối với mỗi bộ phận có nhiều hơn năm nhân viên, hãy truy xuất số bộ phận và số nhân viên của bộ phận đó đang kiếm được hơn 40.000 đô la
Q28: SELECT Dno, COUNT (*)
FROM EMPLOYEE
WHERE Salary>40000 AND Dno IN (
SELECT Dno
FROM EMPLOYEE
GROUP BY Dno
HAVING COUNT (*) > 5)
GROUP BY Dno;
1.9 Cấu trúc CASE WHEN
Trong phần này, chúng tôi minh họa hai cấu trúc SQL bổ sung. Mệnh đề VỚI cho phép người dùng xác định một bảng sẽ chỉ được sử dụng trong một truy vấn cụ thể; nó hơi giống với việc tạo một dạng xem (xem Phần 7.3) sẽ chỉ được sử dụng trong một truy vấn và sau đó bị loại bỏ. Cấu trúc này được giới thiệu như là một tiện ích trong SQL:99 và có thể không có sẵn trong tất cả các DBMS dựa trên SQL. Các truy vấn sử dụng VỚI thường có thể được viết bằng các cấu trúc SQL khác. Ví dụ: chúng ta có thể viết lại Q28 thành Q28′:
Q28′: WITH BIGDEPTS (Dno) AS
(
SELECT Dno
FROM EMPLOYEE
GROUP BY Dno
HAVING COUNT (*) > 5
) SELECT Dno, COUNT (*)
FROM EMPLOYEE
WHERE Salary>40000 AND Dno IN BIGDEPTS
GROUP BY Dno;
Trong Q28′, chúng ta đã xác định trong mệnh đề WITH một bảng tạm thời BIG_DEPTS có kết quả chứa Dno của các bộ phận có hơn năm nhân viên, sau đó sử dụng bảng này trong truy vấn tiếp theo. Khi truy vấn này được thực thi, bảng tạm thời BIGDEPTS sẽ bị loại bỏ.
SQL cũng có cấu trúc CASE, có thể được sử dụng khi một giá trị có thể khác dựa trên các điều kiện nhất định. Điều này có thể được sử dụng trong bất kỳ phần nào của truy vấn SQL nơi giá trị được mong đợi, kể cả khi truy vấn, chèn hoặc cập nhật bộ dữ liệu. Chúng tôi minh họa điều này với một ví dụ. Giả sử chúng ta muốn tăng lương cho nhân viên tùy thuộc vào bộ phận họ làm việc; ví dụ, nhân viên ở bộ phận 5 được tăng lương $2.000, nhân viên ở bộ phận 4 nhận được $1.500 và nhân viên ở bộ phận 1 nhận được $3.000 (xem Hình 5.6 về các bộ nhân viên). Sau đó, chúng ta có thể viết lại thao tác cập nhật U6 từ dưới dạng U6′:
U6′: UPDATE EMPLOYEE
SET Salary =
CASE WHEN Dno = 5 THEN Salary + 2000
WHEN Dno = 4 THEN Salary + 1500
WHEN Dno = 1 THEN Salary + 3000
ELSE Salary + 0 ;
In U6′, the salary raise value is determined through the CASE construct based on the department number for which each employee works. The CASE construct can also be used when inserting tuples that can have different attributes being NULL depending on the type of record being inserted into a table, as when a specialization (see Chapter 4) is mapped into a single table (see Chapter 9) or when a union type is mapped into relations.
Trong U6′, giá trị tăng lương được xác định thông qua cấu trúc CASE dựa trên số bộ phận mà mỗi nhân viên làm việc. Cấu trúc CASE cũng có thể được sử dụng khi chèn các bộ có thể có các thuộc tính khác nhau là NULL tùy thuộc vào loại bản ghi được chèn vào một bảng, như khi một chuyên môn hóa (xem Chương 4) được ánh xạ vào một bảng duy nhất (trình bày sau) hoặc khi một kiểu kết hợp được ánh xạ vào các quan hệ.
1.10 Truy vấn đệ quy
Trong phần này, chúng tôi minh họa cách viết một truy vấn đệ quy trong SQL. Cú pháp này đã được thêm vào trong SQL:99 để cho phép người dùng có khả năng chỉ định truy vấn đệ quy theo cách khai báo. Một ví dụ về mối quan hệ đệ quy giữa các bộ cùng loại là mối quan hệ giữa nhân viên và người giám sát. Mối quan hệ này được mô tả bởi khóa ngoại Super_ssn của quan hệ EMPLOYEE trong Hình 5.5 và 5.6, và nó liên kết mỗi bộ nhân viên (trong vai trò người giám sát) với bộ nhân viên khác (trong vai trò người giám sát). Một ví dụ về thao tác đệ quy là truy xuất tất cả những người được giám sát của một nhân viên giám sát e ở tất cả các cấp—nghĩa là tất cả nhân viên e′ được giám sát trực tiếp bởi e, tất cả nhân viên e′ được giám sát trực tiếp bởi mỗi nhân viên e′, tất cả nhân viên e″′ trực tiếp được giám sát bởi từng nhân viên e″, v.v. Trong SQL:99, truy vấn này có thể được viết như sau:
Q29: WITH RECURSIVE SUP_EMP (SupSsn, EmpSsn) AS
( SELECT SupervisorSsn, Ssn
FROM EMPLOYEE
UNION
SELECT E.Ssn, S.SupSsn
FROM EMPLOYEE AS E, SUP_EMP AS S
WHERE E.SupervisorSsn = S.EmpSsn)
SELECT* FROM SUP_EMP;
Trong Q29, chúng ta đang tạo một View SUP_EMP sẽ giữ kết quả của truy vấn đệ quy. View đầu trống. Lần đầu tiên nó được tải với các kết hợp Ssn cấp độ đầu tiên (người giám sát, người được giám sát) thông qua phần đầu tiên (SELECT SupervisorSss, Ssn FROM EMPLOYEE), được gọi là truy vấn cơ sở. Điều này sẽ được kết hợp thông qua UNION với từng cấp độ giám sát kế tiếp thông qua phần thứ hai, trong đó nội dung của View được kết hợp lại với các giá trị cơ sở để có được các kết hợp cấp độ thứ hai, được UNION với cấp độ đầu tiên. Điều này được lặp lại với các mức liên tiếp cho đến khi đạt đến một điểm cố định, tại đó không có bộ dữ liệu nào được thêm vào View. Tại thời điểm này, kết quả của truy vấn đệ quy nằm trong khung nhìn SUP_EMP.
1.11 Thảo luận tóm tắt về truy vấn SQL
Một truy vấn truy xuất trong SQL có thể bao gồm tối đa sáu mệnh đề, nhưng chỉ hai mệnh đề đầu tiên— SELECT và FROM—là bắt buộc. Truy vấn có thể kéo dài nhiều dòng và được kết thúc bằng dấu chấm phẩy. Các thuật ngữ truy vấn được phân tách bằng dấu cách và dấu ngoặc đơn có thể được sử dụng để nhóm các phần có liên quan của truy vấn theo cách tiêu chuẩn. Các mệnh đề được chỉ định theo thứ tự sau, với các mệnh đề nằm giữa dấu ngoặc vuông [ … ] là tùy chọn:
SELECT <attribute and function list>
FROM <table list>
[ WHERE <condition> ]
[ GROUP BY <grouping attribute(s)> ]
[ HAVING <group condition> ]
[ ORDER BY <attribute list> ];
Mệnh đề SELECT liệt kê các thuộc tính hoặc hàm cần truy xuất. Mệnh đề FROM chỉ định tất cả các quan hệ (bảng) cần thiết trong truy vấn, bao gồm các quan hệ đã nối, nhưng không chỉ định các quan hệ trong truy vấn lồng nhau. Mệnh đề WHERE chỉ định các điều kiện để chọn các bộ từ các quan hệ này, bao gồm các điều kiện nối nếu cần. GROUP BY chỉ định các thuộc tính nhóm, trong khi HAVING chỉ định một điều kiện đối với các nhóm được chọn thay vì trên các bộ dữ liệu riêng lẻ. Các hàm tổng hợp tích hợp sẵn COUNT, SUM, MIN, MAX và AVG được sử dụng cùng với việc nhóm nhưng chúng cũng có thể được áp dụng cho tất cả các bộ đã chọn trong một truy vấn mà không cần mệnh đề GROUP BY. Cuối cùng, ORDER BY chỉ định thứ tự hiển thị kết quả của truy vấn
Để xây dựng các truy vấn một cách chính xác, sẽ rất hữu ích khi xem xét các bước xác định ý nghĩa hoặc ngữ nghĩa của từng truy vấn. Một truy vấn được đánh giá về mặt khái niệm bằng cách trước tiên áp dụng mệnh đề FROM (để xác định tất cả các bảng liên quan đến truy vấn hoặc bảng joined), tiếp theo là mệnh đề WHERE để chọn và nối các bộ, sau đó là GROUP BY và HAVING. Về mặt khái niệm, ORDER BY được áp dụng ở cuối để sắp xếp kết quả truy vấn. Nếu không có mệnh đề nào trong ba mệnh đề cuối cùng (GROUP BY, HAVING và ORDER BY) được chỉ định, thì về mặt khái niệm, chúng ta có thể nghĩ về một truy vấn đang được thực thi như sau: Đối với mỗi tổ hợp các bộ dữ liệu—một từ mỗi quan hệ được chỉ định trong mệnh đề FROM —đánh giá mệnh đề WHERE; nếu nó đánh giá là TRUE, hãy đặt các giá trị của các thuộc tính được chỉ định trong mệnh đề SELECT từ tổ hợp bộ dữ liệu này vào kết quả của truy vấn. Tất nhiên, đây không phải là cách hiệu quả để triển khai truy vấn trong một hệ thống thực và mỗi DBMS có các thủ tục tối ưu hóa truy vấn đặc biệt để quyết định kế hoạch thực hiện hiệu quả để thực hiện. Chúng ta sẽ thảo luận về vấn đề xử lý và tối ưu hóa câu truy vấn ở phần sau
Nói chung, có nhiều cách để chỉ định cùng một truy vấn trong SQL. Tính linh hoạt này trong việc chỉ định các truy vấn có những ưu điểm và nhược điểm. Ưu điểm chính là người dùng có thể chọn kỹ thuật mà họ cảm thấy thoải mái nhất khi chỉ định truy vấn. Ví dụ: nhiều truy vấn có thể được chỉ định với các điều kiện nối trong mệnh đề WHERE hoặc bằng cách sử dụng các quan hệ nối trong mệnh đề FROM hoặc với một số dạng truy vấn lồng nhau và toán tử so sánh IN. Một số người dùng có thể cảm thấy thoải mái hơn với cách này, trong khi những người khác có thể cảm thấy thoải mái hơn với cách tiếp cận khác. Từ quan điểm của người lập trình và của hệ thống về tối ưu hóa truy vấn, nói chung nên viết một truy vấn với càng ít thứ tự lồng nhau thì càng tốt.
Nhược điểm của việc có nhiều cách xác định cùng một truy vấn là điều này có thể gây nhầm lẫn cho người dùng, những người có thể không biết nên sử dụng kỹ thuật nào để chỉ định các loại truy vấn cụ thể. Một vấn đề khác là việc thực thi một truy vấn được chỉ định theo một cách có thể hiệu quả hơn so với cùng một truy vấn được chỉ định theo một cách khác. Lý tưởng nhất là không nên xảy ra trường hợp này: DBMS nên xử lý cùng một truy vấn theo cùng một cách bất kể truy vấn được chỉ định như thế nào. Nhưng điều này khá khó khăn trong thực tế vì mỗi DBMS có các phương pháp khác nhau để xử lý các truy vấn được chỉ định theo các cách khác nhau. Do đó, một gánh nặng bổ sung đối với người dùng là xác định thông số kỹ thuật thay thế nào là hiệu quả nhất để thực thi. Lý tưởng nhất là người dùng chỉ nên lo lắng về việc xác định chính xác truy vấn, trong khi DBMS sẽ xác định cách thực hiện truy vấn một cách hiệu quả. Tuy nhiên, trong thực tế, sẽ hữu ích nếu người dùng biết loại cấu trúc nào trong truy vấn xử lý tốn hiệu quả hơn so với các loại khác.
2. Chỉ định các ràng buộc chung trong SQL và Trigger
Trong phần này, chúng tôi giới thiệu hai tính năng bổ sung của SQL: câu lệnh CREATE ASSERTION và câu lệnh CREATE TRIGGER. Phần 2.1 thảo luận về CREATE ASSERTION, có thể được sử dụng để chỉ định các loại ràng buộc bổ sung nằm ngoài phạm vi của các ràng buộc mô hình quan hệ tích hợp (khóa chính và khóa duy nhất, tính toàn vẹn của thực thể và tính toàn vẹn của tham chiếu) mà chúng tôi đã trình bày trong Phần 5.2 . Các ràng buộc dựng sẵn này có thể được chỉ định trong câu lệnh CREATE TABLE của SQL
Trong Phần 2.2, chúng tôi giới thiệu CREATE TRIGGER, có thể được sử dụng để chỉ định các hành động tự động mà hệ thống cơ sở dữ liệu sẽ thực hiện khi các sự kiện và điều kiện nhất định xảy ra. Chúng tôi chỉ giới thiệu những điều cơ bản về trigger trong chương này và trình bày một cuộc thảo luận đầy đủ hơn trong chương sau
2.1 Chỉ định các ràng buộc bằng Assertion
Trong SQL, người dùng có thể chỉ định các ràng buộc chung—những ràng buộc không thuộc bất kỳ danh mục nào được mô tả trong phần trước ở chương 6 — thông qua các xác nhận khai báo, sử dụng câu lệnh CREATE ASSERTION. Mỗi xác nhận được đặt tên ràng buộc và được chỉ định thông qua một điều kiện tương tự như mệnh đề WHERE của truy vấn SQL. Ví dụ, để chỉ định ràng buộc rằng lương của một nhân viên không được lớn hơn lương của người quản lý bộ phận mà nhân viên đó làm việc trong SQL, chúng ta có thể viết như sau:
CREATE ASSERTION SALARY_CONSTRAINT
CHECK ( NOT EXISTS ( SELECT *
FROM EMPLOYEE E, EMPLOYEE M, DEPARTMENT D
WHERE E.Salary>M.Salary AND E.Dno = D.Dnumber AND D.Mgr_ssn = M.Ssn ) );
Tên ràng buộc SALARY_CONSTRAINT được theo sau bởi từ khóa CHECK, theo sau là một điều kiện trong ngoặc đơn phải đúng trên mọi trạng thái cơ sở dữ liệu để xác nhận được thỏa mãn. Tên ràng buộc có thể được sử dụng sau này để vô hiệu hóa ràng buộc hoặc sửa đổi hoặc loại bỏ nó. DBMS chịu trách nhiệm đảm bảo rằng điều kiện không bị vi phạm. Bất kỳ điều kiện mệnh đề WHERE nào cũng có thể được sử dụng, nhưng nhiều ràng buộc có thể được chỉ định bằng cách sử dụng kiểu điều kiện SQL EXISTS và NOT EXISTS. Bất cứ khi nào một số bộ dữ liệu trong cơ sở dữ liệu khiến điều kiện của câu lệnh ASSERTION được đánh giá là FALSE, ràng buộc đó sẽ bị vi phạm. Trạng thái cơ sở dữ liệu thỏa mãn ràng buộc nếu không có sự kết hợp nào của các bộ trong trạng thái cơ sở dữ liệu đó vi phạm ràng buộc.
Kỹ thuật cơ bản để viết các assertion như vậy là chỉ định một truy vấn chọn bất kỳ bộ nào vi phạm điều kiện mong muốn. Bằng cách chèn truy vấn này bên trong mệnh đề NOT EXISTS, xác nhận sẽ chỉ định rằng kết quả của truy vấn này phải trống để điều kiện sẽ luôn là TRUE. Do đó, assertion bị vi phạm nếu kết quả của truy vấn không trống. Trong ví dụ trước, truy vấn chọn tất cả nhân viên có lương cao hơn lương của người quản lý bộ phận của họ. Nếu kết quả của truy vấn không trống, assertion bị coi là vi phạm.
Lưu ý rằng mệnh đề CHECK và điều kiện ràng buộc cũng có thể được sử dụng để chỉ định các ràng buộc đối với các thuộc tính và miền riêng lẻ và trên các bộ riêng lẻ. Một điểm khác biệt chính giữa CREATE ASSERTION và các ràng buộc miền riêng lẻ và ràng buộc bộ dữ liệu là các mệnh đề CHECK trên các thuộc tính, miền và bộ dữ liệu riêng lẻ chỉ được kiểm tra trong SQL khi các bộ dữ liệu được chèn hoặc cập nhật trong một bảng cụ thể. Do đó, việc kiểm tra ràng buộc có thể được thực hiện hiệu quả hơn bởi DBMS trong những trường hợp này. Người thiết kế lược đồ chỉ nên sử dụng CHECK trên các thuộc tính, miền và bộ dữ liệu khi họ chắc chắn rằng ràng buộc chỉ có thể bị vi phạm bằng cách chèn hoặc cập nhật bộ dữ liệu. Mặt khác, người thiết kế lược đồ chỉ nên sử dụng CREATE ASSERTION trong trường hợp không thể sử dụng CHECK trên các thuộc tính, miền hoặc bộ dữ liệu, để các kiểm tra đơn giản được DBMS triển khai hiệu quả hơn
2.2 Giới thiệu về Trigger
Một câu lệnh quan trọng khác trong SQL là CREATE TRIGGER. Trong nhiều trường hợp, việc xác định loại hành động sẽ được thực hiện khi các sự kiện nhất định xảy ra và khi các điều kiện nhất định được thỏa mãn là điều thuận tiện. Ví dụ: có thể hữu ích khi chỉ định một điều kiện mà nếu vi phạm sẽ khiến một số người dùng được thông báo về vi phạm. Người quản lý có thể muốn được thông báo nếu chi phí đi lại của nhân viên vượt quá giới hạn nhất định bằng cách nhận tin nhắn bất cứ khi nào điều này xảy ra. Hành động mà DBMS phải thực hiện trong trường hợp này là gửi một thông báo thích hợp tới người dùng đó. Do đó, điều kiện được sử dụng để giám sát cơ sở dữ liệu. Các hành động khác có thể được chỉ định, chẳng hạn như thực thi một thủ tục được lưu trữ cụ thể hoặc kích hoạt các bản cập nhật khác. Câu lệnh CREATE TRIGGER được sử dụng để thực hiện các hành động như vậy trong SQL. Chúng ta sẽ thảo luận phần này chi tiết ở bài viết khác. Ở đây chúng tôi chỉ đưa ra một ví dụ đơn giản về cách sử dụng trigger
R5: CREATE TRIGGER SALARY_VIOLATION
BEFORE INSERT OR UPDATE OF SALARY, SUPERVISOR_SSN ON EMPLOYEE
FOR EACH ROW WHEN ( NEW.SALARY > ( SELECT SALARY FROM EMPLOYEE
WHERE SSN = NEW.SUPERVISOR_SSN ) ) INFORM_SUPERVISOR(NEW.Supervisor_ssn, NEW.Ssn );
Trigger được đặt tên là SALARY_VIOLATION, có thể được sử dụng để xóa hoặc hủy kích hoạt trình kích hoạt sau này. Một trigger điển hình được coi là một quy tắc ECA (Event - Sự kiện, Condition - Điều kiện, Action - Hành động) có ba thành phần:
- (Các) sự kiện: Đây thường là các hoạt động cập nhật cơ sở dữ liệu được áp dụng rõ ràng cho cơ sở dữ liệu. Trong ví dụ này, các sự kiện là: chèn bản ghi nhân viên mới, thay đổi lương của nhân viên hoặc thay đổi người giám sát của nhân viên. Người viết trigger phải đảm bảo rằng tất cả các sự kiện có thể xảy ra đều được tính đến. Trong một số trường hợp, có thể cần phải viết nhiều trình kích hoạt để bao gồm tất cả các trường hợp có thể xảy ra. Các sự kiện này được chỉ định sau từ khóa BEFORE trong ví dụ của chúng tôi, điều đó có nghĩa là trigger phải được thực thi trước khi thao tác được thực thi. Một cách khác là sử dụng từ khóa AFTER, chỉ định rằng trigger sẽ được thực thi sau khi hoàn thành thao tác được chỉ định trong sự kiện
- Điều kiện xác định liệu hành động có nên được thực thi hay không: Sau khi sự kiện kích hoạt đã xảy ra, một điều kiện tùy chọn có thể được đánh giá. Nếu không có điều kiện nào được chỉ định, hành động sẽ được thực hiện khi sự kiện xảy ra. Nếu một điều kiện được chỉ định, nó sẽ được đánh giá trước tiên và chỉ khi nó đánh giá là true thì hành động mới được thực thi. Điều kiện được chỉ định trong mệnh đề WHEN của trigger
- Hành động được thực hiện: Hành động thường là một chuỗi các câu lệnh SQL, nhưng nó cũng có thể là một giao dịch cơ sở dữ liệu hoặc một chương trình bên ngoài sẽ được thực thi tự động. Trong ví dụ này, hành động là thực thi thủ tục được lưu trữ INFORM_SUPERVISOR.
Trigger có thể được sử dụng trong các ứng dụng khác nhau, chẳng hạn như duy trì tính nhất quán của cơ sở dữ liệu, theo dõi cập nhật cơ sở dữ liệu và cập nhật dữ liệu dẫn xuất tự động. Chúng ta sẽ nói kỹ hơn về trigger trong phần sau
3. View trong SQL
Trong phần này, chúng ta tìm hiểu khái niệm về view trong SQL. Chúng tôi chỉ ra các để khai báo view, và sau đó chúng ta thảo luận về vấn đề cập nhật các view và cách DBMS có thể triển khai các view
3.1 Khái niệm View trong SQL
Một view trong SQL là một bảng duy nhất được dẫn xuất từ các bảng khác. Các bảng khác này có thể là các bảng cơ sở hoặc các view đã được định nghĩa trước đó. Một view không nhất thiết phải tồn tại dưới dạng lưu trữ vật lý; nó được coi là một bảng ảo, trái ngược với các bảng cơ sở, các bộ dữ liệu của chúng luôn được lưu trữ vật lý trong cơ sở dữ liệu. Điều này giới hạn các thao tác cập nhật có thể áp dụng cho view, nhưng nó không cung cấp bất kỳ hạn chế nào đối với việc truy vấn view
Chúng ta có thể nghĩ về một view như một cách chỉ định một bảng mà chúng ta cần tham chiếu thường xuyên, mặc dù nó có thể không được lưu trữ vật lý. Ví dụ, tham khảo cơ sở dữ liệu COMPANY trong Hình 5.5, chúng ta có thể thường xuyên đưa ra các truy vấn lấy tên nhân viên và tên dự án mà nhân viên đó làm việc. Thay vì phải chỉ định phép nối của ba bảng EMPLOYEE, WORKS_ON và PROJECT mỗi khi đưa ra truy vấn này, chúng ta có thể xác định một view được chỉ định là kết quả của những phép nối này. Sau đó, chúng ta có thể đưa ra các truy vấn trên view, các truy vấn này được chỉ định dưới dạng truy xuất một bảng thay vì truy xuất liên quan đến hai phép nối trên ba bảng. Chúng tôi gọi các bảng EMPLOYEE, WORKS_ON và PROJECT là các bảng xác định của view.
3.2 Khai báo View trong SQL
Trong SQL, lệnh để khai báo View là CREATE VIEW. View được cung cấp một tên bảng (ảo) (hoặc tên view), một danh sách các tên thuộc tính và một truy vấn để chỉ định nội dung của view. Đối với các thuộc tính là kết quả của việc áp dụng các hàm hoặc phép tính số học, thì chúng ta phải chỉ định tên thuộc tính mới view, các thuộc tính còn lại sẽ giống với tên của các thuộc tính của bảng xác định trong trường hợp mặc định. Các view trong V1 và V2 tạo các bảng ảo có lược đồ được minh họa trong Hình 7.2 khi được áp dụng cho lược đồ cơ sở dữ liệu của Hình 5.5.
V1: CREATE VIEW WORKS_ON1
AS SELECT Fname, Lname, Pname, Hours
FROM EMPLOYEE, PROJECT, WORKS_ON
WHERE Ssn = Essn AND Pno = Pnumber;
V2: CREATE VIEW DEPT_INFO(Dept_name, No_of_emps, Total_sal)
AS SELECT Dname, COUNT (*), SUM (Salary)
FROM DEPARTMENT, EMPLOYEE
WHERE Dnumber = Dno GROUP BY Dname;

Trong V1, chúng tôi đã không chỉ định bất kỳ tên thuộc tính mới nào cho chế độ xem WORKS_ON1 (mặc dù chúng ta hoàn toàn có thể đặt lại tên); trong trường hợp này, WORKS_ON1 kế thừa tên của các thuộc tính từ các bảng xác định EMPLOYEE, PROJECT và WORKS_ON. Chế độ xem V2 chỉ định rõ ràng các tên thuộc tính mới cho view DEPT_INFO, sử dụng tương ứng một-một giữa các thuộc tính được chỉ định trong mệnh đề CREATE VIEW và các thuộc tính được chỉ định trong mệnh đề SELECT của truy vấn xác định view.
Giờ đây, chúng ta có thể chỉ định các truy vấn SQL trên một view—hoặc bảng ảo—theo cách tương tự, chúng ta chỉ định các truy vấn liên quan đến các bảng cơ sở. Ví dụ: để truy xuất họ và tên của tất cả nhân viên làm việc trong dự án ‘ProductX’, chúng ta có thể sử dụng view WORKS_ON1 và chỉ định truy vấn như trong QV1:
QV1: SELECT Fname, Lname
FROM WORKS_ON1
WHERE Pname = ‘ProductX’;
Cùng một truy vấn sẽ yêu cầu đặc tả của hai phép nối nếu được chỉ định trực tiếp trên các quan hệ cơ sở; một trong những ưu điểm chính của view là đơn giản hóa các truy vấn nhất định. Viewcũng được sử dụng làm cơ chế bảo mật và phân quyền
View luôn luôn được cập nhật; nếu chúng ta sửa đổi các bộ dữ liệu trong các bảng cơ sở mà ivewđược xác định, thì view sẽ tự động phản ánh những thay đổi này. Do đó, view không nhất thiết phải được nhận ra hoặc cụ thể hóa tại thời điểm định nghĩa chế độ xem mà tại thời điểm chúng tôi chỉ định một truy vấn trên chế độ xem. Trách nhiệm của DBMS chứ không phải người dùng là đảm bảo rằng view được cập nhật. Chúng tôi sẽ thảo luận về nhiều cách khác nhau mà DBMS có thể sử dụng để giữ cho view được cập nhật trong phần tiếp theo.
Nếu chúng ta không cần view nữa, chúng ta có thể sử dụng lệnh DROP VIEW để loại bỏ nó. Ví dụ, để xóa view V1, chúng ta có thể sử dụng câu lệnh SQL trong V1A:
V1A: DROP VIEW WORKS_ON1;
3.3 Thực thi và cập nhật View, In-line View
Vấn đề làm thế nào một DBMS có thể triển khai một cách hiệu quả một view để truy vấn hiệu quả là một vấn đề phức tạp. Hai cách tiếp cận chính đã được đề xuất. Một chiến lược, được gọi là sửa đổi truy vấn, liên quan đến việc sửa đổi hoặc chuyển đổi truy vấn dạng view (do người dùng gửi) thành một truy vấn trên các bảng cơ sở bên dưới. Ví dụ: truy vấn QV1 sẽ được DBMS tự động sửa đổi thành truy vấn sau:
SELECT Fname, Lname
FROM EMPLOYEE, PROJECT, WORKS_ON
WHERE Ssn = Essn AND Pno = Pnumber AND Pname = ‘ProductX’;
Nhược điểm của phương pháp này là nó không hiệu quả đối với các view được xác định thông qua các truy vấn phức tạp tốn nhiều thời gian để thực hiện, đặc biệt nếu nhiều truy vấn view sẽ được áp dụng cho cùng một view trong một khoảng thời gian ngắn. Chiến lược thứ hai, được gọi là cụ thể hóa view, liên quan đến việc tạo một bảng view tạm thời hoặc vĩnh viễn khi view được truy vấn hoặc tạo lần đầu tiên và giữ bảng đó với giả định rằng các truy vấn khác trên chế độ xem sẽ tuân theo. Trong trường hợp này, một chiến lược hiệu quả để tự động cập nhật bảng view khi các bảng cơ sở được cập nhật phải được phát triển để giữ cho view được cập nhật. Các kỹ thuật sử dụng khái niệm cập nhật đã được phát triển cho mục đích này, trong đó DBMS có thể xác định bộ dữ liệu mới nào phải được chèn, xóa hoặc sửa đổi trong bảng dạng view cụ thể hóa khi cập nhật cơ sở dữ liệu được áp dụng cho một trong các bảng cơ sở xác định. View thường được giữ dưới dạng bảng cụ thể hóa (được lưu trữ vật lý) miễn là nó đang được truy vấn. Nếu view không được truy vấn trong một khoảng thời gian nhất định, thì hệ thống có thể tự động xóa bảng vật lý và tính toán lại từ đầu khi các truy vấn trong tương lai tham chiếu đến view.
Có thể có các chiến lược khác nhau khi cập nhật view cụ thể hóa. Chiến lược cập nhật ngay lập tức cập nhật view ngay khi các bảng cơ sở được thay đổi; chiến lược cập nhật chậm cập nhật view khi cần bằng truy vấn đến view; và chiến lược cập nhật định kỳ cập nhật view theo định kỳ (trong chiến lược sau, truy vấn view có thể nhận được kết quả không cập nhật).
Người dùng luôn có thể đưa ra truy vấn truy xuất đối với bất kỳ view nào. Tuy nhiên, trong nhiều trường hợp, việc đưa ra lệnh INSERT, DELETE hoặc UPDATE trên view là không thể. Nói chung, một bản cập nhật trên một view được xác định trên một bảng mà không có bất kỳ hàm tổng hợp nào có thể được ánh xạ tới một bản cập nhật trên bảng cơ sở bên dưới trong một số điều kiện nhất định. Đối với view liên quan đến phép kết (join), thao tác cập nhật có thể được ánh xạ tới thao tác cập nhật trên các quan hệ cơ sở bên dưới theo nhiều cách. Do đó, DBMS thường không thể xác định được bản cập nhật nào. Để minh họa các sự cố tiềm ẩn khi cập nhật view được xác định trên nhiều bảng, hãy xem xét view WORKS_ON1 và giả sử rằng chúng tôi đưa ra lệnh cập nhật thuộc tính PNAME của 'John Smith' từ 'ProductX' thành 'ProductY'. Bản cập nhật view này được hiển thị trong UV1:
UV1: UPDATE WORKS_ON1
SET Pname = ‘ProductY’
WHERE Lname = ‘Smith’ AND Fname = ‘John’ AND Pname = ‘ProductX’;
Truy vấn này có thể được ánh xạ thành một số cập nhật trên các quan hệ cơ sở để mang lại hiệu ứng cập nhật mong muốn trên view. Ngoài ra, một số cập nhật này sẽ tạo ra các tác dụng phụ bổ sung ảnh hưởng đến kết quả của các truy vấn khác. Ví dụ, đây là hai cập nhật có thể có, (a) và (b), trên các quan hệ cơ sở tương ứng với thao tác cập nhật view trong UV1:
(a): UPDATE WORKS_ON
SET Pno = (
SELECT Pnumber
FROM PROJECT
WHERE Pname = ‘ProductY’ )
WHERE Essn IN (
SELECT Ssn
FROM EMPLOYEE
WHERE Lname = ‘Smith’ AND Fname = ‘John’ )
AND Pno = (
SELECT Pnumber
FROM PROJECT
WHERE Pname = ‘ProductX’ );
(b): UPDATE PROJECT
SET Pname = ‘ProductY’
WHERE Pname = ‘ProductX’;
'ProductX' và là bản cập nhật có nhiều khả năng được mong muốn nhất. Tuy nhiên, (b) cũng sẽ cung cấp hiệu ứng cập nhật mong muốn trên view, nhưng nó thực hiện điều này bằng cách thay đổi tên của bộ 'ProductX' trong quan hệ DỰ ÁN thành 'ProductY'. Rất khó có khả năng người dùng đã chỉ định cập nhật view UV1 muốn bản cập nhật được diễn giải như trong (b), vì nó cũng có tác dụng phụ là thay đổi tất cả các bộ dữ liệu view với Pname = 'ProductX'.
Một số cập nhật về view có thể không có nhiều ý nghĩa; ví dụ: sửa đổi thuộc tính Total_sal của view DEPT_INFO không có ý nghĩa gì vì Total_sal được xác định là tổng tiền lương của từng nhân viên. Yêu cầu không chính xác này được hiển thị dưới dạng UV2:
UV2: UPDATE DEPT_INFO
SET Total_sal = 100000
WHERE Dname = ‘Research’;
Nói chung, một bản cập nhật view khả thi khi chỉ một bản cập nhật có thể có trên các quan hệ cơ sở có thể thực hiện thao tác cập nhật mong muốn trên view. Bất cứ khi nào một bản cập nhật trên viewcó thể được ánh xạ tới nhiều hơn một bản cập nhật trên các quan hệ cơ sở bên dưới, nó thường không được phép. Một số nhà nghiên cứu đã gợi ý rằng DBMS có một quy trình nhất định để chọn một trong các bản cập nhật có thể là bản cập nhật có khả năng nhất. Một số nhà nghiên cứu đã phát triển các phương pháp để chọn bản cập nhật có khả năng nhất, trong khi các nhà nghiên cứu khác muốn người dùng chọn bản đồ cập nhật mong muốn trong khi khai báo view. Nhưng các tùy chọn này thường không có sẵn trong hầu hết các DBMS thương mại.
Tóm lại, chúng ta có thể đưa ra những nhận xét sau:
- Một view với một bảng xác định duy nhất có thể cập nhật được nếu các thuộc tính view chứa khóa chính của quan hệ cơ sở, cũng như tất cả các thuộc tính có ràng buộc NOT NULL không có giá trị mặc định được chỉ định.
- View được xác định trên nhiều bảng bằng cách sử dụng phép nối thường không thể cập nhật được
- Các view được xác định bằng cách sử dụng các hàm tổng hợp không thể cập nhật được.
Trong SQL, mệnh đề WITH CHECK OPTIONnên được thêm vào cuối định nghĩa dạng xem nếu dạng xem được cập nhật bằng các câu lệnh INSERT, DELETE hoặc UPDATE. Điều này cho phép hệ thống từ chối các hoạt động vi phạm quy tắc SQL để xem các bản cập nhật. Bộ quy tắc SQL đầy đủ khi người dùng có thể sửa đổi view phức tạp hơn các quy tắc đã nêu trước đó.
Cũng có thể xác định view trong mệnh đề FROM của truy vấn SQL. Đây được gọi là in-line view. Trong trường hợp này, view được xác định trong chính truy vấn đó.
3.4 Phân quyền thông qua View
Chúng tôi mô tả chi tiết các câu lệnh phân quyền truy vấn SQL (GRANT và REVOKE) trong bài sau, khi chúng tôi trình bày các cơ chế phân quyền và bảo mật cơ sở dữ liệu. Ở đây, chúng tôi sẽ chỉ đưa ra một vài ví dụ đơn giản để minh họa cách các view có thể được sử dụng để ẩn các thuộc tính hoặc bộ dữ liệu nhất định khỏi những người dùng không được phép. Giả sử một người dùng nào đó chỉ được phép xem thông tin nhân viên đối với nhân viên làm việc cho bộ phận 5; thì chúng ta có thể tạo view sau DEPT5EMP và cấp cho người dùng đặc quyền để truy vấn chế view chứ không phải bảng cơ sở EMPLOYEE. Người dùng này sẽ chỉ có thể truy xuất thông tin nhân viên cho các bộ dữ liệu nhân viên có Dno = 5 và sẽ không thể xem các bộ dữ liệu nhân viên khác khi view được truy vấn.
CREATE VIEW DEPT5EMP AS
SELECT *
FROM EMPLOYEE
WHERE Dno = 5;
Theo cách tương tự, view có thể hạn chế người dùng chỉ xem các cột nhất định; ví dụ: chỉ tên, họ và địa chỉ của nhân viên mới có thể hiển thị như sau:
CREATE VIEW BASIC_EMP_DATA AS
SELECT Fname, Lname, Address
FROM EMPLOYEE;
Do đó, bằng cách tạo một view phù hợp và cấp cho một số người dùng quyền truy cập view chứ không phải các bảng cơ sở, họ sẽ bị hạn chế chỉ truy xuất dữ liệu được chỉ định trong view. Chương 30 thảo luận chi tiết về bảo mật và ủy quyền, bao gồm các câu lệnh GRANT và REVOKE của SQL.
4. Câu lệnh thay đổi lược đồ trong SQL
Trong phần này, chúng tôi cung cấp tổng quan về các lệnh thay đổi lược đồ có sẵn trong SQL, lệnh này có thể được sử dụng để thay đổi lược đồ bằng cách thêm hoặc loại bỏ các bảng, thuộc tính, ràng buộc và các thành phần lược đồ khác. Điều này có thể được thực hiện trong khi cơ sở dữ liệu đang hoạt động và không yêu cầu biên dịch lại lược đồ cơ sở dữ liệu. DBMS phải thực hiện một số kiểm tra nhất định để đảm bảo rằng những thay đổi không ảnh hưởng đến phần còn lại của cơ sở dữ liệu và làm cho nó không nhất quán.
4.1 Câu lệnh DROP
Lệnh DROP có thể được sử dụng để loại bỏ các phần tử lược đồ đã đặt tên, chẳng hạn như bảng, miền, loại hoặc ràng buộc. Người ta cũng có thể loại bỏ toàn bộ lược đồ nếu nó không còn cần thiết nữa bằng cách sử dụng lệnh DROP SCHEMA. Có hai tùy chọn hành vi thả: CASCADE và RESTRICT. Ví dụ: để xóa lược đồ cơ sở dữ liệu COMPANY và tất cả các bảng, miền và các thành phần khác của nó, tùy chọn CASCADE được sử dụng như sau:
DROP SCHEMA COMPANY CASCADE;
Nếu tùy chọn RESTRICT được chọn thay cho CASCADE, lược đồ chỉ bị loại bỏ nếu nó không có phần tử nào trong đó; nếu không, lệnh DROP sẽ không được thực hiện. Để sử dụng tùy chọn RESTRICT, trước tiên người dùng phải drop từng phần tử trong lược đồ, sau đó drop chính lược đồ đó.
Nếu một quan hệ cơ sở trong một lược đồ không còn cần thiết nữa, quan hệ đó và định nghĩa của nó có thể bị xóa bằng cách sử dụng lệnh DROP TABLE. Ví dụ: nếu chúng ta không còn muốn theo dõi những người phụ thuộc của nhân viên trong cơ sở dữ liệu COMPANY của Hình 6.1, chúng ta có thể loại bỏ quan hệ DEPENDENT bằng cách đưa ra lệnh sau
DROP TABLE DEPENDENT CASCADE;
Nếu tùy chọn RESTRICT được chọn thay vì CASCADE, một bảng chỉ bị loại bỏ nếu nó không được tham chiếu trong bất kỳ ràng buộc nào (ví dụ: bởi định nghĩa khóa ngoại trong quan hệ khác) hoặc dạng xem (xem Phần 7.3) hoặc bởi bất kỳ thành phần nào khác. Với tùy chọn CASCADE, tất cả các ràng buộc, view và các thành phần khác tham chiếu đến bảng bị loại bỏ cũng sẽ tự động bị loại bỏ khỏi lược đồ, cùng với chính bảng đó.
Lưu ý rằng lệnh DROP TABLE không chỉ xóa tất cả các bản ghi trong bảng nếu thành công mà còn xóa định nghĩa bảng khỏi danh mục. Nếu chỉ muốn xóa các bản ghi nhưng để lại định nghĩa bảng để sử dụng trong tương lai, thì nên sử dụng lệnh DELETE (xem Phần 6.4.2) thay vì DROP TABLE.
Lệnh DROP cũng có thể được sử dụng để loại bỏ các loại phần tử lược đồ được đặt tên khác, chẳng hạn như các ràng buộc hoặc miền.
4.2 Câu lệnh ALTER
Có thể thay đổi định nghĩa của một bảng cơ sở hoặc của các phần tử lược đồ được đặt tên khác bằng cách sử dụng lệnh ALTER. Đối với các bảng cơ sở, các hành động thay đổi bảng có thể có bao gồm thêm hoặc loại bỏ một cột (thuộc tính), thay đổi định nghĩa cột và thêm hoặc loại bỏ các ràng buộc của bảng. Ví dụ, để thêm thuộc tính theo dõi công việc của nhân viên vào quan hệ cơ sở EMPLOYEE trong lược đồ COMPANY (xem Hình 6.1), chúng ta có thể sử dụng lệnh
ALTER TABLE COMPANY.EMPLOYEE ADD COLUMN Job VARCHAR(12);
Chúng ta vẫn phải nhập một giá trị cho thuộc tính mới Job cho từng bộ EMPLOYEE riêng lẻ. Điều này có thể được thực hiện bằng cách chỉ định một mệnh đề mặc định hoặc bằng cách sử dụng lệnh UPDATE riêng lẻ trên mỗi bộ dữ liệu (xem Phần 6.4.3). Nếu không có mệnh đề mặc định nào được chỉ định, thuộc tính mới sẽ có giá trị NULL trong tất cả các bộ của mối quan hệ ngay sau khi lệnh được thực thi; do đó, ràng buộc NOT NULL không được phép trong trường hợp này.
Để xoát một cột, chúng ta phải chọn CASCADE hoặc RESTRICT cho hành vi drop. Nếu CASCADE được chọn, tất cả các ràng buộc và dạng xem tham chiếu đến cột sẽ tự động bị loại bỏ khỏi lược đồ, cùng với cột. Nếu RESTRICT được chọn, lệnh chỉ thành công nếu không có dạng xem hoặc ràng buộc nào (hoặc các phần tử lược đồ khác) tham chiếu đến cột. Ví dụ: lệnh sau xóa thuộc tính Địa chỉ khỏi bảng cơ sở EMPLOYEE:
ALTER TABLE COMPANY.EMPLOYEE DROP COLUMN Address CASCADE;
Cũng có thể thay đổi định nghĩa cột bằng cách loại bỏ mệnh đề mặc định hiện có hoặc bằng cách xác định mệnh đề mặc định mới. Các ví dụ sau đây minh họa mệnh đề này:
ALTER TABLE COMPANY.DEPARTMENT ALTER COLUMN Mgr_ssn DROP DEFAULT;
ALTER TABLE COMPANY.DEPARTMENT ALTER COLUMN Mgr_ssn SET DEFAULT ‘333445555’;
Người ta cũng có thể thay đổi các ràng buộc được chỉ định trên một bảng bằng cách thêm hoặc bỏ một ràng buộc đã đặt tên. Để được loại bỏ, một ràng buộc phải được đặt tên khi nó được chỉ định. Ví dụ, để loại bỏ ràng buộc có tên EMPSUPERFK trong Hình 6.2 khỏi quan hệ EMPLOYEE, chúng ta viết:
ALTER TABLE COMPANY.EMPLOYEE DROP CONSTRAINT EMPSUPERFK CASCADE;
Khi điều này được thực hiện, chúng ta có thể xác định lại một ràng buộc thay thế bằng cách thêm một ràng buộc mới vào quan hệ, nếu cần. Điều này được xác định bằng cách sử dụng từ khóa ADD CONSTRAINT trong câu lệnh ALTER TABLE theo sau là ràng buộc mới, ràng buộc này có thể được đặt tên hoặc đặt tên và có thể thuộc bất kỳ loại ràng buộc bảng nào được thảo luận.
Các tiểu mục trước đã đưa ra một cái nhìn tổng quan về các lệnh phát triển lược đồ của SQL. Cũng có thể tạo các bảng và dạng xem mới trong lược đồ cơ sở dữ liệu bằng cách sử dụng các lệnh thích hợp. Có nhiều chi tiết và tùy chọn khác;
5. Tóm tắt
Trong phần này chúng ta đã tìm hiểu thêm các truy vấn tương đối phức tạp hơn bài trước, các khái niệm về Trigger và View sẽ được trình bày ở các chương cụ thể hơn. Ngoài ra chúng, chương này cũng trình các câu lệnh DROP và ALTER
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Cơ sở dữ liệu và hệ quản trị cơ sở dữ liệu là một thành phần thiết yếu của cuộc sống trong xã hội hiện đại: hầu hết chúng ta đều gặp các hoạt động liên quan đến hoạt động với cơ sở dữ liệu trong cuộc sống hằng ngày. Trong bài viết này chúng ta sẽ tìm hiểu khái niệm đầu tiên về hệ quản trị cơ sở dữ liệu và nhóm người dùng
Kiến trúc của các gói DBMS đã phát triển từ các hệ thống nguyên khối ban đầu, trong đó toàn bộ gói phần mềm DBMS là một hệ thống tích hợp chặt chẽ, đến các gói DBMS hiện đại được thiết kế theo dạng mô-đun, với kiến trúc client / server trong bài hôm nay mình cùng tìm hiểu về khái niệm và kiến trúc hệ quản trị cơ sở dữ liệu
Mô hình hóa khái niệm là một giai đoạn rất quan trọng trong việc thiết kế một ứng dụng cơ sở dữ liệu thành công. Thông thường, thuật ngữ ứng dụng cơ sở dữ liệu đề cập đến một cơ sở dữ liệu cụ thể và các chương trình liên quan thực hiện các truy vấn và cập nhật cơ sở dữ liệu. Trong bài này chúng ta sẽ tìm hiểu mô hình hóa dữ liệu với sơ đồ ER
Các khái niệm mô hình ER được thảo luận trong Chương 3 là đủ để biểu diễn nhiều lược đồ cơ sở dữ liệu cho các ứng dụng cơ sở dữ liệu truyền thống, bao gồm nhiều ứng dụng xử lý dữ liệu trong kinh doanh và công nghiệp. Tuy nhiên, kể từ cuối những năm 1970, các nhà thiết kế ứng dụng cơ sở dữ liệu đã cố gắng thiết kế các lược đồ cơ sở dữ liệu chính xác hơn phản ánh các thuộc tính và ràng buộc dữ liệu một cách chính xác hơn từ đó chúng ta có mô hình thực thể mối quan hệ mở rộng - EER
Mô hình dữ liệu quan hệ lần đầu tiên được giới thiệu bởi Ted Codd của IBM Research vào năm 1970 trong một bài báo kinh điển (Codd, 1970), và nó đã thu hút sự chú ý ngay lập tức do tính đơn giản và nền tảng toán học của nó. Mô hình sử dụng khái niệm quan hệ toán học - trông giống như một bảng giá trị - làm khối xây dựng cơ bản của nó và có cơ sở lý thuyết trong lý thuyết tập hợp và logic vị từ bậc nhất.
Ngôn ngữ SQL có thể được coi là một trong những lý do chính cho sự thành công thương mại của cơ sở dữ liệu. Bởi vì nó đã trở thành một tiêu chuẩn cho cơ sở dữ liệu quan hệ, người dùng ít quan tâm hơn đến việc di chuyển các ứng dụng cơ sở dữ liệu của họ từ các loại hệ thống cơ sở dữ liệu khác — ví dụ, từ mô hình mạng hoặc hệ thống phân cấp — sang hệ thống quan hệ
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên