Chương 1: Hệ quản trị cơ sở dữ liệu và người dùng

Nội dung bài viết
Cơ sở dữ liệu và hệ quản trị cơ sở dữ liệu là một thành phần thiết yếu của cuộc sống trong xã hội hiện đại: hầu hết chúng ta đều gặp các hoạt động liên quan đến hoạt động với cơ sở dữ liệu trong cuộc sống hằng ngày. Ví dụ: khi bạn đến ngân hàng để gửi hoặc rút tiền, khi bạn đặt phòng khách sạn hoặc máy bay, khi bạn truy cập vào dữ liệu của một thư viện được số hóa để tìm kiếm một thư mục về sách hoặc nếu chúng ta mua một thứ gì đó trực tuyến — chẳng hạn như sách, đồ chơi, hoặc máy tính —tất cả các hoạt động đó sẽ liên quan đến một người nào đó hoặc một số phần mềm truy cập vào cơ sở dữ liệu. Ngay cả khi mua hàng tại siêu thị thường thì cũng liên quan đến việc truy cập vào hệ quản trị cơ sở dữ liệu để lấy thông tin giá hàng hóa, hoặc thao tác tự động cập nhật tồn kho hàng hóa
Những tương tác trên là ví dụ về những gì chúng ta có thể gọi là các ứng dụng cơ sở dữ liệu truyền thống, trong đó hầu hết thông tin được lưu trữ và truy cập là dạng văn bản hoặc dạng số. Trong vài năm trở lại đây, những tiến bộ trong công nghệ đã dẫn đến những ứng dụng mới thú vị của hệ thống cơ sở dữ liệu. Sự gia tăng của các trang web mạng xã hội, chẳng hạn như Facebook, Twitter và Flickr, cùng với nhiều trang khác, đã đòi hỏi sự sáng tạo của các cơ sở dữ liệu lớn lưu trữ dữ liệu phi truyền thống, chẳng hạn như bài đăng, đoạn âm thanh, hình ảnh và video clip. Các loại hệ thống cơ sở dữ liệu mới, thường được gọi là hệ thống lưu trữ dữ liệu lớn (big data), hoặc NOSQL, chúng được tạo ra để quản lý dữ liệu cho các ứng dụng liên quan truyền thông xã hội. Các loại hệ thống cơ sở dữ liệu như này cũng được sử dụng bởi các công ty như Google, Amazon và Yahoo, để quản lý dữ liệu cần thiết trong các công cụ tìm kiếm trên web của họ, cũng như để cung cấp lưu trữ đám mây, nhờ đó người dùng được cung cấp các các dịch vụ lưu trữ theo yêu cầu của trang web dành cho quản lý tất cả các loại dữ liệu bao gồm tài liệu, chương trình, hình ảnh, video và email.
Bây giờ chúng ta đề cập đến một số ứng dụng khác của cơ sở dữ liệu. Việc phổ biến rộng rãi của công nghệ hình ảnh và video trên điện thoại di động và các thiết bị khác dẫn đến yêu cầu cơ sở dữ liệu có thể lưu trữ hình ảnh, đoạn âm thanh và video. Các loại tệp này đang trở thành một thành phần quan trọng của cơ sở dữ liệu đa phương tiện. Hệ thống thông tin địa lý (GIS) có thể lưu trữ và phân tích bản đồ, dữ liệu thời tiết và hình ảnh vệ tinh. Kho dữ liệu và hệ thống xử lý phân tích trực tuyến (OLAP) được sử dụng trong nhiều công ty để trích xuất và phân tích thông tin kinh doanh hữu ích từ cơ sở dữ liệu rất lớn để hỗ trợ việc ra quyết định. Hoạt động của công nghệ cơ sở dữ liệu trong thời gian thực được sử dụng để kiểm soát các quy trình sản xuất trong công nghiệp. Và các giải thuật tìm kiếm trong cơ sở dữ liệu đang được áp dụng cho các hệ thống web để cải thiện việc tìm kiếm thông tin cần thiết cho người dùng
1. Giới Thiệu
Cơ sở dữ liệu và công nghệ về cơ sở dữ liệu đã có tác động lớn đến việc phát triển về sử dụng máy tính ngày. Công bằng mà nói, cơ sở dữ liệu đóng một vai trò quan trọng trong hầu hết các lĩnh vực mà máy tính được sử dụng, bao gồm kinh doanh, thương mại điện tử, truyền thông xã hội, tiếng Anh, y học, di truyền học, luật, giáo dục và thư viện. Cơ sở dữ liệu từ được sử dụng phổ biến đến mức chúng ta phải bắt đầu bằng cách xác định cơ sở dữ liệu là gì. Định nghĩa ban đầu của chúng là khá chung chung.
Cơ sở dữ liệu là một tập hợp các dữ liệu liên quan. Đối với dữ liệu, chúng tôi muốn nói đến các sự kiện đã biết có thể được ghi lại và có ý nghĩa ngầm định. Ví dụ, hãy xem xét tên, số điện thoại và địa chỉ của những người bạn biết. Ngày nay, dữ liệu này thường được lưu trữ trong điện thoại di động có phần mềm cơ sở dữ liệu đơn giản của riêng chúng. Dữ liệu này cũng có thể được ghi vào sổ địa chỉ đã được lập chỉ mục hoặc được lưu trữ trên ổ cứng, sử dụng máy tính cá nhân và phần mềm như Microsoft Access hoặc Excel. Bộ sưu tập dữ liệu liên quan với ý nghĩa ngầm định này là một cơ sở dữ liệu.
Định nghĩa trước đây về cơ sở dữ liệu là khá chung chung; ví dụ, chúng ta có thể coi tập hợp các từ tạo nên trang văn bản này là dữ liệu liên quan và do đó tạo thành cơ sở dữ liệu. Tuy nhiên, việc sử dụng phổ biến thuật ngữ cơ sở dữ liệu thường bị hạn chế hơn. Cơ sở dữ liệu có các thuộc tính ngầm định sau:
-
Cơ sở dữ liệu đại diện cho một số khía cạnh của thế giới thực, đôi khi được gọi là thế giới nhỏ. Những thay đổi đối với thế giới nhỏ được phản ánh trong cơ sở dữ liệu
-
Cơ sở dữ liệu là một tập hợp dữ liệu mạch lạc về mặt logic với một số ý nghĩa vốn có. Một loại dữ liệu ngẫu nhiên không thể được coi là cơ sở dữ liệu một cách chính xác
-
Cơ sở dữ liệu được thiết kế, xây dựng và cung cấp dữ liệu cho một mục đích cụ thể. Nó có một nhóm người dùng dự định và một số ứng dụng mà những người dùng này quan tâm.
Nói cách khác, cơ sở dữ liệu có một số nguồn mà dữ liệu được lấy từ đó, một mức độ tương tác nào đó với các sự kiện trong thế giới thực và một đối tượng tích cực tìm kiếm nội dung của nó. Người dùng cuối của cơ sở dữ liệu có thể thực hiện các giao dịch kinh doanh (ví dụ: khách hàng mua máy ảnh) hoặc các sự kiện có thể xảy ra (ví dụ: một nhân viên có con nhỏ) khiến thông tin trong cơ sở dữ liệu thay đổi. Để cơ sở dữ liệu luôn chính xác và đáng tin cậy, nó phải phản ánh trung thực thế giới nhỏ mà nó đại diện; do đó, các thay đổi phải được phản ánh trong cơ sở dữ liệu càng sớm càng tốt
Cơ sở dữ liệu có thể có kích thước và độ phức tạp bất kỳ. Ví dụ, danh sách tên và địa chỉ được đề cập trước đó có thể chỉ gồm vài trăm bản ghi, mỗi bản ghi có cấu trúc đơn giản. Mặt khác, danh mục máy tính của một thư viện lớn có thể chứa nửa triệu mục nhập được sắp xếp theo các danh mục khác nhau — theo họ của tác giả chính, theo chủ đề, theo tên sách — với mỗi danh mục được sắp xếp theo thứ tự bảng chữ cái. Một cơ sở dữ liệu có kích thước và độ phức tạp lớn hơn nữa sẽ được duy trì bởi một công ty truyền thông xã hội như Facebook, công ty có hơn một tỷ người dùng. Cơ sở dữ liệu phải duy trì thông tin mà người dùng có quan hệ với nhau như bạn bè, bài đăng của mỗi người dùng, người dùng được phép xem mỗi bài đăng và một lượng lớn các loại thông tin khác cần thiết cho hoạt động chính xác của trang web của họ . Đối với những trang web như vậy, cần có một số lượng lớn cơ sở dữ liệu để theo dõi những thông tin liên tục thay đổi theo yêu cầu của trang web mạng xã hội.
Một ví dụ về cơ sở dữ liệu thương mại lớn là Amazon.com. Nó chứa dữ liệu của hơn 60 triệu người dùng đang hoạt động và hàng triệu cuốn sách, CD, video, DVD, trò chơi, thiết bị điện tử, quần áo và các mặt hàng khác. Cơ sở dữ liệu chiếm hơn 42 terabyte (một terabyte là dung lượng lưu trữ 1012 byte) và được lưu trữ trên hàng trăm máy tính (được gọi là máy chủ). Hàng triệu khách truy cập Amazon.com mỗi ngày và sử dụng cơ sở dữ liệu để mua hàng. Cơ sở dữ liệu được cập nhật liên tục khi sách mới và các mặt hàng khác được thêm vào kho và số lượng hàng trong kho được cập nhật khi phát sinh giao dịch mua hàng.
Cơ sở dữ liệu có thể được tạo và duy trì theo cách thủ công hoặc nó có thể được tự động hóa. Ví dụ, danh mục thẻ thư viện là một cơ sở dữ liệu có thể được tạo và duy trì theo cách thủ công. Cơ sở dữ liệu máy tính có thể được tạo và duy trì bởi một nhóm các chương trình ứng dụng được viết riêng cho nhiệm vụ đó hoặc bởi một hệ quản trị cơ sở dữ liệu. Tất nhiên, chúng ta chỉ quan tâm đến cơ sở dữ liệu máy tính.
Hệ quản trị cơ sở dữ liệu (DBMS) là một hệ thống cho phép người dùng tạo và duy trì cơ sở dữ liệu. DBMS là một hệ thống phần mềm có mục đích chung tạo điều kiện thuận lợi cho các quá trình xác định, xây dựng, thao tác và chia sẻ cơ sở dữ liệu giữa những người dùng và ứng dụng khác nhau. Việc xác định cơ sở dữ liệu bao gồm việc xác định các kiểu dữ liệu, cấu trúc và các ràng buộc của dữ liệu sẽ được lưu trữ trong cơ sở dữ liệu. Định nghĩa cơ sở dữ liệu hoặc thông tin mô tả cũng được DBMS lưu trữ dưới dạng danh mục cơ sở dữ liệu hoặc từ điển; nó được gọi là metadata. Xây dựng cơ sở dữ liệu là quá trình lưu trữ dữ liệu trên một số phương tiện lưu trữ được điều khiển bởi DBMS. Thao tác với cơ sở dữ liệu bao gồm các chức năng như truy vấn cơ sở dữ liệu để truy xuất dữ liệu cụ thể, cập nhật cơ sở dữ liệu để phản ánh những thay đổi trong thực tế và tạo báo cáo từ dữ liệu. Chia sẻ cơ sở dữ liệu cho phép nhiều người dùng và chương trình truy cập cơ sở dữ liệu đồng thời.
Một chương trình ứng dụng truy cập cơ sở dữ liệu bằng cách gửi các truy vấn hoặc yêu cầu dữ liệu tới DBMS. Một câu truy vấn thường khiến một số dữ liệu được truy xuất; một giao dịch có thể khiến một số dữ liệu được đọc và một số dữ liệu được ghi vào cơ sở dữ liệu.
Các chức năng quan trọng khác được cung cấp bởi DBMS bao gồm bảo vệ cơ sở dữ liệu và duy trì nó trong một thời gian dài. Bảo vệ bao gồm bảo vệ hệ thống chống lại sự cố phần cứng hoặc phần mềm (hoặc sự cố) và bảo vệ an ninh chống lại truy cập trái phép hoặc độc hại. Một cơ sở dữ liệu lớn điển hình có thể có vòng đời kéo dài nhiều năm, vì vậy DBMS phải có khả năng duy trì hệ thống cơ sở dữ liệu bằng cách cho phép hệ thống phát triển khi các yêu cầu thay đổi theo thời gian.
Không nhất thiết phải sử dụng phần mềm DBMS có mục đích chung để triển khai cơ sở dữ liệu được số hóa. Có thể viết một bộ chương trình tùy chỉnh để tạo và duy trì cơ sở dữ liệu, thực sự tạo ra một phần mềm DBMS có mục đích đặc biệt cho một ứng dụng cụ thể, chẳng hạn như ứng dụng đặt chỗ của các hãng hàng không. Trong cả hai trường hợp — cho dù chúng ta sử dụng DBMS có mục đích chung hay không — một lượng đáng kể phần mềm phức tạp được triển khai. Trên thực tế, hầu hết các DBMS là các hệ thống phần mềm rất phức tạp.
2. Đặc điểm của phương pháp tiếp cận cơ sở dữ liệu
Một số đặc điểm phân biệt cách tiếp cận cơ sở dữ liệu với cách tiếp cận cũ hơn nhiều là viết các chương trình giao tiếp file để truy cập dữ liệu được lưu trữ trong tệp. Trong xử lý tệp truyền thống, mỗi người dùng xác định và triển khai các tệp cần thiết cho một ứng dụng phần mềm cụ thể như một phần của lập trình ứng dụng. Ví dụ: nhóm người dùng quản lý điểm số học sinh có thể giữ các tệp về học sinh và điểm của họ. Các tính năn in bảng điểm và nhập điểm vào được triển khai như một phần của ứng dụng. Người dùng thứ hai thuộc văn phòng kế toán, có thể theo dõi các khoản phí của sinh viên và các khoản thanh toán của họ. Mặc dù cả hai người dùng đều quan tâm đến dữ liệu về sinh viên nhưng mỗi người dùng duy trì các tệp riêng biệt — và các chương trình để thao tác với các tệp này — vì mỗi người yêu cầu một số dữ liệu không có sẵn từ tệp của người dùng khác. Sự dư thừa này trong việc xác định và lưu trữ dữ liệu dẫn đến việc lãng phí không gian lưu trữ và các thao tác dư thừa trong cập nhật những phần dữ liệu chung này
Trong cách tiếp cận cơ sở dữ liệu, một kho lưu trữ duy trì dữ liệu được xác định một lần và sau đó được nhiều người dùng khác nhau truy cập lặp đi lặp lại thông qua các truy vấn, giao dịch và chương trình ứng dụng. Các đặc điểm chính của cách tiếp cận cơ sở dữ liệu so với cách tiếp cận xử lý tệp là:
-
Tự mô tả bản chất của một hệ thống cơ sở dữ liệu
-
Cách ly giữa các chương trình và dữ liệu, và trừu tượng hóa dữ liệu
-
Hỗ trợ nhiều chế độ xem dữ liệu (chia sẻ dữ liệu)
-
Chia sẻ dữ liệu và xử lý giao dịch đa người dùng
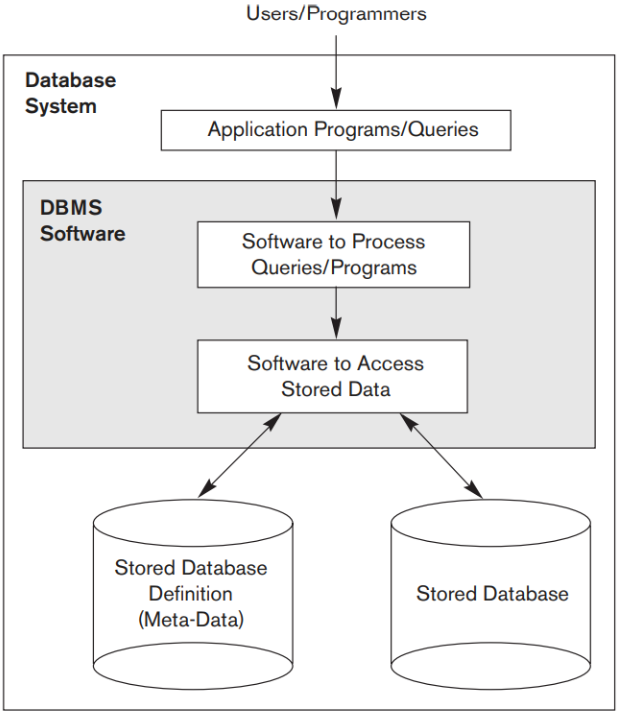
2.1 Tự mô tả bản chất của một hệ thống cơ sở dữ liệu
Một đặc điểm cơ bản của cách tiếp cận cơ sở dữ liệu là hệ thống cơ sở dữ liệu không chỉ chứa bản thân cơ sở dữ liệu mà còn chứa một định nghĩa hoặc mô tả đầy đủ về cấu trúc cơ sở dữ liệu và các ràng buộc. Định nghĩa này được lưu trữ trong catalog DBMS, chứa thông tin như cấu trúc của từng tệp, kiểu và định dạng của từng mục dữ liệu và các ràng buộc khác nhau đối với dữ liệu. Thông tin được lưu trữ trong danh mục được gọi là metadata và nó mô tả cấu trúc của cơ sở dữ liệu cơ sở. Điều quan trọng cần lưu ý là một số loại hệ thống cơ sở dữ liệu mới hơn, được gọi là NOSQL, không yêu cầu metadata. Thay vào đó, dữ liệu được lưu trữ dưới dạng dữ liệu tự mô tả bao gồm tên mục dữ liệu và giá trị dữ liệu cùng nhau trong một cấu trúc
Danh mục là thông tin được sử dụng bởi phần mềm DBMS và cả những người sử dụng cơ sở dữ liệu, những người cần thông tin về cấu trúc cơ sở dữ liệu. Gói phần mềm DBMS có mục đích chung không được viết cho một ứng dụng cơ sở dữ liệu cụ thể. Do đó, nó phải tham khảo danh mục để biết cấu trúc của các tệp trong một cơ sở dữ liệu cụ thể, chẳng hạn như loại và định dạng dữ liệu mà nó sẽ truy cập. Phần mềm DBMS phải hoạt động tốt như nhau với bất kỳ số lượng ứng dụng cơ sở dữ liệu nào — ví dụ, cơ sở dữ liệu trường đại học, cơ sở dữ liệu ngân hàng hoặc cơ sở dữ liệu công ty — miễn là định nghĩa cơ sở dữ liệu được lưu trữ trong danh mục.
Trong xử lý tệp truyền thống, định nghĩa dữ liệu thường là một phần của bản thân các chương trình ứng dụng. Do đó, các chương trình này bị ràng buộc chỉ hoạt động với một cơ sở dữ liệu cụ thể, có cấu trúc được khai báo trong các chương trình ứng dụng. Ví dụ, một chương trình ứng dụng được viết bằng C ++ có thể là struct hoặc là định nghĩa 1 class. Trong khi phần mềm xử lý tệp chỉ có thể truy cập các cơ sở dữ liệu cụ thể, thì DBMS có thể truy cập các cơ sở dữ liệu đa dạng bằng cách trích xuất các định nghĩa cơ sở dữ liệu từ danh mục và sử dụng các định nghĩa này.
Trong ví dụ dưới đây bạn có thể hiểu rõ hơn về bản chất mô tả và định nghĩa cấu trúc dữ liệu
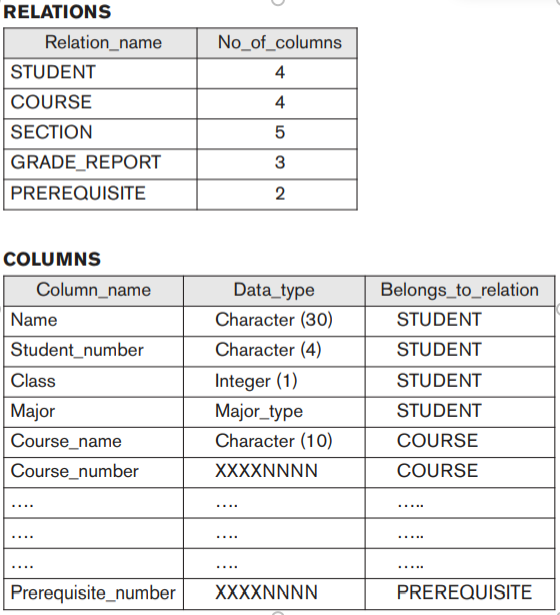
2.2 Cách ly giữa chương trình và dữ liệu, và trừu tượng hóa dữ liệu
Trong xử lý tệp truyền thống, cấu trúc của tệp dữ liệu được nhúng trong các chương trình ứng dụng, vì vậy bất kỳ thay đổi nào đối với cấu trúc của tệp có thể yêu cầu thay đổi tất cả các chương trình truy cập tệp đó. Ngược lại, các chương trình truy cập DBMS không yêu cầu những thay đổi như vậy trong hầu hết các trường hợp. Cấu trúc của tệp dữ liệu được lưu trữ trong danh mục DBMS riêng biệt với các chương trình truy cập. Chúng tôi gọi đây là thuộc tính độc lập dữ liệu và chương trình.
Trong một số loại hệ thống cơ sở dữ liệu, chẳng hạn như hệ thống hướng đối tượng và quan hệ đối tượng, người dùng có thể định nghĩa các hoạt động trên dữ liệu như một phần của định nghĩa cơ sở dữ liệu. Một hoạt động (còn được gọi là một hàm hoặc phương thức) được chỉ định thành hai phần. Giao diện của một hoạt động bao gồm tên hoạt động và các kiểu dữ liệu của các đối số (hoặc tham số) của nó. Việc thực thi được chỉ định riêng và có thể thay đổi mà không ảnh hưởng đến các thành phần liên quan. Các chương trình ứng dụng của người dùng có thể hoạt động trên dữ liệu bằng cách gọi các hàm này thông qua tên và đối số của chúng, bất kể hoạt động được thực hiện như thế nào. Điều này có thể được gọi là độc lập hoạt động chương trình
Trong cách tiếp cận cơ sở dữ liệu, cấu trúc và tổ chức chi tiết của mỗi tệp được lưu trữ trong danh mục. Người dùng cơ sở dữ liệu và các chương trình ứng dụng đề cập đến việc biểu diễn tập hợp các tệp và DBMS trích xuất các chi tiết về lưu trữ tệp từ danh mục khi các mô-đun truy cập tệp DBMS cần các chi tiết này. Nhiều mô hình dữ liệu có thể được sử dụng để cung cấp sự trừu tượng hóa dữ liệu này cho người dùng cơ sở dữ liệu. Một phần chính của đoạn này được dành để trình bày các mô hình dữ liệu khác nhau và các khái niệm mà chúng sử dụng để trừu tượng hóa việc biểu diễn dữ liệu.
Trong cơ sở dữ liệu hướng đối tượng và cơ sở dữ liệu quan hệ đối tượng, quá trình trừu tượng hóa không chỉ bao gồm cấu trúc dữ liệu mà còn bao gồm các hoạt động trên dữ liệu. Các hoạt động này cung cấp một bản tóm tắt về các hoạt động của miniworld mà người dùng thường hiểu. Ví dụ, một phép toán CALCULATE_GPA có thể được áp dụng cho đối tượng STUDENT để tính điểm trung bình. Các hoạt động như vậy có thể được gọi bởi các truy vấn của người dùng hoặc các chương trình ứng dụng mà không cần phải biết chi tiết về cách các hoạt động được thực hiện
2.3 Hỗ trợ nhiều chế độ xem dữ liệu
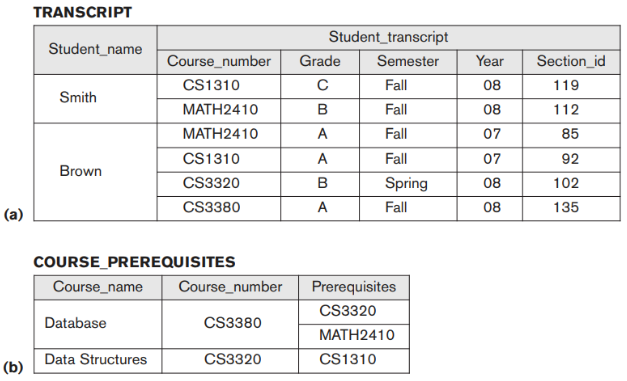
Một cơ sở dữ liệu thường có nhiều kiểu người dùng, mỗi người trong số họ có thể yêu cầu một kiểu xem dữ liệu khác nhau trên cùng một cơ sở dữ liệu. Một kiểu xem (view) có thể là một tập hợp con của cơ sở dữ liệu hoặc nó có thể chứa dữ liệu ảo có nguồn gốc từ cơ sở dữ liệu nhưng không được lưu trữ rõ ràng (giá trị dẫn xuất - ví dụ: thuộc tính thành tiền được tính đơn giá nhân với số lượng trong một trường hợp hợp). Một số người dùng có thể không cần biết liệu dữ liệu mà họ đề cập đến có được lưu trữ hay có nguồn gốc hay không. Một DBMS nhiều người dùng mà người dùng có nhiều ứng dụng riêng biệt khác nhau phải cung cấp các phương tiện để xác định nhiều dạng xem. Ví dụ, một người sử dụng cơ sở dữ liệu có thể chỉ quan tâm đến việc truy cập và in bảng điểm của mỗi học sinh; chế độ xem cho người dùng này được hiển thị trong Hình (a). Người dùng thứ hai, người chỉ liên quan đến việc kiểm tra xem sinh viên đã thực hiện tất cả các điều kiện tiên quyết của mỗi khóa học mà sinh viên đăng ký hay chưa, có thể yêu cầu chế độ xem trong Hình (b).
2.4 Chia sẻ dữ liệu và xử lý giao dịch đa người dùng
Một DBMS đa người dùng, như tên gọi của nó, phải cho phép nhiều người dùng truy cập cơ sở dữ liệu cùng một lúc. Điều này là cần thiết nếu dữ liệu cho nhiều ứng dụng được tích hợp và duy trì trong một cơ sở dữ liệu duy nhất. DBMS phải đảm bảo vấn đề đồng thời (data concurrency) khi một số người dùng đang cố gắng cập nhật cùng một dữ liệu phải đảm bảo rằng việc cập nhật là chính xác. Ví dụ, khi một số đại lý đặt chỗ cố gắng chỉ định một chỗ ngồi trên một chuyến bay của hãng hàng không, DBMS phải đảm bảo rằng mỗi lần chỉ có một đại lý có thể truy cập vào một chỗ ngồi để chỉ định cho hành khách. Các loại ứng dụng này thường được gọi là ứng dụng xử lý giao dịch trực tuyến (OLTP). Vai trò cơ bản của phần mềm DBMS đa người dùng là đảm bảo rằng các giao dịch đồng thời hoạt động chính xác và hiệu quả
Khái niệm giao dịch đã trở thành trọng tâm của nhiều ứng dụng cơ sở dữ liệu. Giao dịch là một chương trình hoặc quy trình đang thực thi bao gồm một hoặc nhiều quyền truy cập cơ sở dữ liệu, chẳng hạn như đọc hoặc cập nhật các bản ghi cơ sở dữ liệu. Mỗi giao dịch được đặt ra để thực hiện một truy cập cơ sở dữ liệu chính xác về mặt logic nếu được thực thi toàn bộ mà không có sự can thiệp từ các giao dịch khác. DBMS phải thực thi một số thuộc tính giao dịch. Thuộc tính cách ly đảm bảo rằng mỗi giao dịch dường như được thực hiện tách biệt với các giao dịch khác, ngay cả khi hàng trăm giao dịch có thể được thực hiện đồng thời. Thuộc tính toàn vẹn đảm bảo rằng tất cả các hoạt động cơ sở dữ liệu trong một giao dịch được thực thi hoặc không có.
3. Người dùng cơ sở dữ liệu
Đối với cơ sở dữ liệu cá nhân nhỏ, chẳng hạn như danh sách địa chỉ được thảo luận trong Phần 1.1, thường chỉ có một người xác định, xây dựng và thao tác cơ sở dữ liệu và không có chia sẻ. Tuy nhiên, trong các tổ chức lớn, nhiều người tham gia vào việc thiết kế, sử dụng và duy trì một cơ sở dữ liệu lớn với hàng trăm hoặc hàng nghìn người dùng. Trong phần này, chúng ta xác định những người có công việc liên quan đến việc sử dụng cơ sở dữ liệu lớn hàng ngày; chúng ta gọi họ là người dùng cơ sở dữ liệu.
3.1 Database Administrator (Quản trị viên)
Trong bất kỳ tổ chức nào có nhiều người cùng sử dụng các nguồn lực, cần có một quản trị viên chính để giám sát và quản lý các nguồn lực này. Trong môi trường cơ sở dữ liệu, tài nguyên chính là chính cơ sở dữ liệu và tài nguyên thứ cấp là DBMS và phần mềm liên quan. Quản lý các tài nguyên này là trách nhiệm của người quản trị cơ sở dữ liệu (DBA). DBA chịu trách nhiệm cấp quyền truy cập vào cơ sở dữ liệu, điều phối và giám sát việc sử dụng cơ sở dữ liệu cũng như thu thập các tài nguyên phần mềm và phần cứng khi cần thiết. DBA phải chịu trách nhiệm về các vấn đề như vi phạm bảo mật và hiệu năng của hệ thống. Trong các tổ chức lớn, DBA được hỗ trợ bởi đội ngũ nhân viên thực hiện các chức năng này
3.2 Database Designers (Người thiết kế)
Người thiết kế cơ sở dữ liệu có trách nhiệm xác định dữ liệu sẽ được lưu trữ trong cơ sở dữ liệu và lựa chọn cấu trúc thích hợp để biểu diễn và lưu trữ dữ liệu này. Những tác vụ này chủ yếu được thực hiện trước khi cơ sở dữ liệu thực sự được triển khai và được cập nhật dữ liệu. Các nhà thiết kế cơ sở dữ liệu có trách nhiệm giao tiếp với tất cả người dùng cơ sở dữ liệu tiềm năng để hiểu các yêu cầu của họ và tạo ra một thiết kế đáp ứng các yêu cầu này. Trong nhiều trường hợp, các nhà thiết kế là nhân viên của DBA và có thể được giao trách nhiệm cho nhân viên khác sau khi hoàn thành thiết kế cơ sở dữ liệu. Các nhà thiết kế cơ sở dữ liệu thường tương tác với từng nhóm người dùng tiềm năng và phát triển các view của cơ sở dữ liệu đáp ứng các yêu cầu xử lý và dữ liệu của các nhóm này. Mỗi view sau đó được phân tích và tích hợp với các view của các nhóm người dùng khác. Thiết kế cơ sở dữ liệu cuối cùng phải có khả năng hỗ trợ các yêu cầu của tất cả các nhóm người dùng
3.3 End Users (Người dùng cuối)
Người dùng cuối là những người có công việc yêu cầu quyền truy cập vào cơ sở dữ liệu để truy vấn, cập nhật và tạo báo cáo; cơ sở dữ liệu chủ yếu tồn tại để sử dụng. Có một số loại người dùng cuối:
-
Người dùng cuối thông thường thỉnh thoảng truy cập vào cơ sở dữ liệu, nhưng họ có thể cần thông tin khác nhau mỗi lần. Họ sử dụng giao diện truy vấn cơ sở dữ liệu phức tạp để chỉ định yêu cầu của họ và thường là người quản lý cấp trung hoặc cấp cao hoặc các trình duyệt không thường xuyên khác.
-
Người dùng cuối “ngây thơ” chiếm một phần khá lớn người dùng cuối cơ sở dữ liệu. Chức năng công việc chính của họ xoay quanh việc liên tục truy vấn và cập nhật cơ sở dữ liệu, sử dụng các loại truy vấn và cập nhật tiêu chuẩn — được gọi là giao dịch được đóng gói — đã được lập trình và thử nghiệm cẩn thận. Nhiều tác vụ trong số này hiện có sẵn dưới dạng ứng dụng dành cho thiết bị di động để sử dụng với các thiết bị di động. Các tác vụ mà những người dùng đó thực hiện rất đa dạng. Một vài ví dụ là:
-
Khách hàng và giao dịch viên của ngân hàng kiểm tra số dư tài khoản, gửi tiền và rút tiền.
- Các đại lý đặt chỗ hoặc khách hàng của các hãng hàng không, khách sạn và công ty cho thuê xe hơi kiểm tra tình trạng sẵn có cho một yêu cầu nhất định và đặt chỗ
- Nhân viên tại các trạm tiếp nhận của các công ty vận chuyển nhập thông tin nhận dạng gói hàng qua mã vạch và thông tin mô tả thông qua các nút để cập nhật cơ sở dữ liệu trung tâm về các gói hàng đã nhận và đang vận chuyển
- Người dùng mạng xã hội đăng và đọc các mục trên các trang web mạng xã hội
-
-
Người dùng cuối “tinh vi” bao gồm các lập trình viên, nhà khoa học, nhà phân tích nghiệp vụ và những người khác đã hoàn toàn làm quen với các cơ sở của DBMS để triển khai các ứng dụng của riêng họ nhằm đáp ứng các yêu cầu phức tạp của họ.
-
Người dùng độc lập duy trì cơ sở dữ liệu cá nhân bằng cách sử dụng các phần mềm đóng gói làm sẵn cung cấp giao diện dựa trên menu hoặc đồ họa dễ sử dụng. Một ví dụ là người dùng gói phần mềm tài chính lưu trữ nhiều loại dữ liệu tài chính cá nhân.
Một DBMS điển hình cung cấp nhiều phương tiện để truy cập cơ sở dữ liệu. Người dùng cuối “ngây thơ” cần tìm hiểu rất ít về các tính năng được cung cấp bởi DBMS; họ chỉ đơn giản là phải hiểu giao diện người dùng của ứng dụng dành cho thiết bị di động hoặc các giao dịch tiêu chuẩn được thiết kế và triển khai để sử dụng. Người dùng thông thường chỉ tìm hiểu một số phương tiện mà họ có thể sử dụng nhiều lần. Những người dùng “tinh vi” cố gắng tìm hiểu hầu hết các cơ sở DBMS để đạt được các yêu cầu phức tạp của họ. Người dùng độc lập thường trở nên rất thành thạo trong việc sử dụng một gói phần mềm cụ thể.
3.4 Software Engineer (Kỹ sư phần mềm)
Các kỹ sư phần mềm phân tích hệ thống xác định yêu cầu của người dùng cuối, đặc biệt là người dùng cuối ngây thơ và có tham số, đồng thời phát triển các yêu cầu cho các giao dịch đóng gói tiêu chuẩn đáp ứng các yêu cầu này. Các lập trình viên ứng dụng thực hiện các đặc tả này như các chương trình; sau đó họ kiểm tra, gỡ lỗi, lập tài liệu và duy trì các giao dịch đã thực hiện trước đây. Các nhà phân tích và lập trình viên như vậy — thường được gọi là nhà phát triển phần mềm hoặc kỹ sư phần mềm — nên quen thuộc với đầy đủ các khả năng do DBMS cung cấp để hoàn thành nhiệm vụ của họ.
4. Người vận hành cơ sở dữ liệu
Ngoài những người thiết kế, sử dụng và quản trị cơ sở dữ liệu, thì cũng có những người khác có liên quan đến việc vận hành môi trường hệ thống và phần mềm DBMS. Những người này thường không quan tâm đến nội dung cơ sở dữ liệu. Chúng ta gọi họ là những người vận hành, và họ bao gồm những nhóm người dưới đây:
-
Người thiết kế và triển khai hệ thống DBMS thiết kế và triển khai các mô-đun và giao diện DBMS dưới dạng một gói phần mềm. DBMS là một hệ thống phần mềm rất phức tạp bao gồm nhiều thành phần hoặc mô-đun, bao gồm các mô-đun để triển khai danh mục, công cụ nhập ngôn ngữ truy vấn, xử lý giao diện, truy cập và đệm dữ liệu, kiểm soát thời gian truy cập đồng thời, xử lý khôi phục và bảo mật dữ liệu. DBMS có giao diện khác với phần mềm hệ thống khác.
-
Các nhà phát triển công cụ thiết kế và triển khai các công cụ — các gói phần mềm hỗ trợ việc tạo và thiết kế cơ sở dữ liệu, thiết kế hệ thống cơ sở dữ liệu và cải thiện hiệu suất. Công cụ là các gói tùy chọn thường được tách riêng. Chúng bao gồm các tính năng thiết kế cơ sở dữ liệu, giám sát hiệu suất, ngôn ngữ tự nhiên hoặc giao diện đồ họa, mẫu, mô phỏng và tạo dữ liệu thử nghiệm.
-
Nhân viên vận hành và bảo trì (nhân viên quản trị hệ thống) chịu trách nhiệm vận hành và bảo trì môi trường phần cứng và phần mềm cho hệ thống cơ sở dữ liệu
5. Lợi ích của hướng tiếp cận cơ sở dữ liệu
Trong phần này, chúng ta thảo luận về một số lợi thế của việc sử dụng DBMS và các khả năng mà một DBMS tốt cần có. Những khả năng này bổ sung cho bốn đặc điểm chính được thảo luận trong phần trước. DBA phải sử dụng các khả năng này để hoàn thành nhiều mục tiêu khác nhau liên quan đến thiết kế, quản trị và sử dụng cơ sở dữ liệu đa người dùng lớn
5.1 Kiểm soát việc dư thừa dữ liệu
Trong phương pháp phát triển phần mềm truyền thống sử dụng xử lý tệp, mỗi nhóm người dùng duy trì tệp của riêng mình để xử lý các ứng dụng xử lý dữ liệu của họ. Ví dụ, hãy xem xét ví dụ cơ sở dữ liệu ĐẠI HỌC của Phần 1.2; ở đây, hai nhóm người dùng có thể là bộ phận quản lý đăng ký khóa học và văn phòng kế toán. Theo cách tiếp cận truyền thống, mỗi nhóm lưu giữ các tệp tin về dữ liệu học sinh một cách độc lập. Văn phòng kế toán lưu giữ dữ liệu về đăng ký và thông tin thanh toán liên quan, trong khi văn phòng đăng ký theo dõi các khóa học và điểm của sinh viên. Các nhóm khác có thể sao chép thêm một số hoặc tất cả cùng một dữ liệu trong các tệp của riêng họ.
Sự dư thừa này trong việc lưu trữ cùng một dữ liệu nhiều lần dẫn đến một số vấn đề. Đầu tiên, cần phải thực hiện một cập nhật logic duy nhất — chẳng hạn như nhập dữ liệu về một sinh viên mới — nhiều lần: một lần cho mỗi tệp nơi dữ liệu sinh viên được ghi lại. Điều này dẫn đến sự trùng lặp. Thứ hai, không gian lưu trữ bị lãng phí khi cùng một dữ liệu được lưu trữ lặp đi lặp lại và vấn đề này có thể nghiêm trọng đối với cơ sở dữ liệu lớn. Thứ ba, các tệp đại diện cho cùng một dữ liệu có thể trở nên không nhất quán. Điều này có thể xảy ra vì bản cập nhật được áp dụng cho một số tệp nhưng không áp dụng cho những tệp khác. Ngay cả khi một bản cập nhật — chẳng hạn như thêm một sinh viên mới — được áp dụng cho tất cả các tệp thích hợp, thì dữ liệu liên quan đến sinh viên đó vẫn có thể không nhất quán vì các bản cập nhật được áp dụng độc lập bởi mỗi nhóm người dùng. Ví dụ: một nhóm người dùng có thể nhập sai ngày sinh của sinh viên là "JAN-19-1988", trong khi các nhóm người dùng khác có thể nhập đúng giá trị của "JAN-29-1988".
Trong cách tiếp cận cơ sở dữ liệu, các view của các nhóm người dùng khác nhau được tích hợp trong quá trình thiết kế cơ sở dữ liệu. Tốt nhất, chúng ta nên có một thiết kế cơ sở dữ liệu để lưu trữ từng mục dữ liệu logic — chẳng hạn như tên hoặc ngày sinh của học sinh — chỉ ở một nơi trong cơ sở dữ liệu. Đây được gọi là chuẩn hóa dữ liệu, nó đảm bảo tính nhất quán và tiết kiệm dung lượng lưu trữ
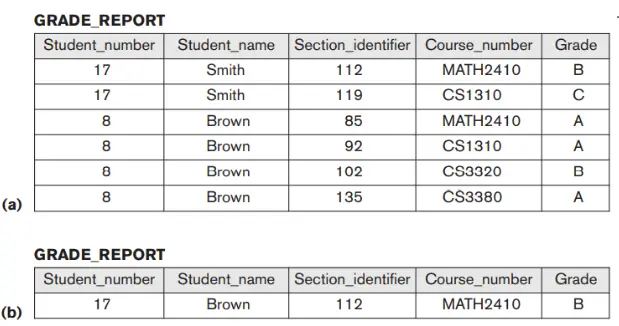
Tuy nhiên, trong thực tế, đôi khi cần sử dụng hạn chế dư thừa dữ liệu để cải thiện hiệu suất của các truy vấn. Ví dụ: chúng ta có thể lưu trữ dư thừa Student_name và Course_number trong tệp GRADE_REPORT (Hình 1.6 (a)) vì bất cứ khi nào chúng ta truy xuất bản ghi GRADE_REPORT, chúng ta muốn truy xuất tên sinh viên và số khóa học cùng với lớp, số sinh viên và định danh. Bằng cách đặt tất cả dữ liệu lại với nhau, chúng ta không phải tìm kiếm nhiều tệp để phân tích dữ liệu này. Điều này được gọi là không chuẩn hóa. Trong những trường hợp như vậy, DBMS phải có khả năng kiểm soát sự dư thừa này để ngăn chặn việc không thống nhất giữa các tệp. Điều này có thể được thực hiện bằng cách tự động kiểm tra xem các giá trị Student_name Student_number trong bất kỳ bản ghi GRADE_REPORT nào trong Hình 1.6 (a) khớp với một trong các giá trị Name-Student_number của bản ghi STUDENT (Hình 1.2). Tương tự, các giá trị Section_identifier – Course_number trong GRADE_REPORT có thể được kiểm tra dựa trên các bản ghi SECTION. Các kiểm tra như vậy có thể được chỉ định cho DBMS trong quá trình thiết kế cơ sở dữ liệu và được DBMS tự động thực thi bất cứ khi nào tệp GRADE_REPORT được cập nhật. Hình 1.6 (b) cho thấy một bản ghi GRADE_REPORT không phù hợp với tệp STUDENT trong Hình 1.2; loại lỗi nàycó thể xảy ra nếu bạn không kiểm soát việc dư thừa dữ liệu. Bạn có thể cho biết phần nào là không nhất quán?
5.2 Hạn chế truy cập trái phép
Khi nhiều người dùng chia sẻ một cơ sở dữ liệu lớn, có khả năng là hầu hết người dùng sẽ không được phép truy cập tất cả thông tin trong cơ sở dữ liệu. Ví dụ: dữ liệu tài chính như tiền lương và tiền thưởng thường được coi là bí mật và chỉ những người có thẩm quyền mới được phép truy cập vào dữ liệu đó. Ngoài ra, một số người dùng có thể chỉ được phép truy xuất dữ liệu, trong khi những người khác được phép truy xuất và cập nhật. Do đó, loại hoạt động truy cập — truy xuất hoặc cập nhật — cũng phải được bảo mật. Thông thường, người dùng hoặc nhóm người dùng được cấp tài khoản và mật khẩu mà họ có thể sử dụng để truy cập vào cơ sở dữ liệu. DBMS phải cung cấp hệ thống bảo mật và phân quyền, hệ thống này DBA sử dụng để tạo tài khoản và phân quyền cho các tài khoản. Sau đó, DBMS sẽ tự động thực thi các phân quyền này. Lưu ý rằng chúng ta có thể áp dụng các tương tự cho phần mềm DBMS. Ví dụ: chỉ nhân viên của DBA mới được phép sử dụng một số phần mềm đặc quyền, chẳng hạn như phần mềm quản lý tài khoản. Tương tự, người dùng chỉ có thể được phép truy cập cơ sở dữ liệu thông qua các ứng dụng được xác định trước hoặc các giao dịch đóng gói được phát triển để họ sử dụng
5.3 Cung cấp khả năng lưu trữ cho các ứng dụng
Cơ sở dữ liệu có thể được sử dụng để cung cấp khả năng lưu trữ liên tục cho các đối tượng chương trình và cấu trúc dữ liệu. Đây là một trong những lý do chính của hệ thống cơ sở dữ liệu hướng đối tượng. Các ngôn ngữ lập trình thường có cấu trúc dữ liệu phức tạp, chẳng hạn như cấu trúc hoặc định nghĩa lớp trong C ++ hoặc Java. Giá trị của các biến hoặc đối tượng chương trình bị loại bỏ sau khi chương trình kết thúc, trừ khi người lập trình giải thích rõ ràng rằng nó sẽ lưu trữ chúng trong các tệp vĩnh viễn, thường liên quan đến việc chuyển đổi các cấu trúc phức tạp này thành một định dạng phù hợp để lưu trữ tệp. Khi phát sinh nhu cầu đọc dữ liệu này một lần nữa, người lập trình phải chuyển đổi từ định dạng tệp sang biến chương trình hoặc cấu trúc đối tượng. Hệ thống cơ sở dữ liệu hướng đối tượng tương thích với các ngôn ngữ lập trình như C ++ và Java, và phần mềm DBMS tự động thực hiện bất kỳ chuyển đổi cần thiết nào. Do đó, một đối tượng phức tạp trong C ++ có thể được lưu trữ vĩnh viễn trong một DBMS hướng đối tượng. Một đối tượng như vậy được cho là tồn tại lâu dài, vì nó vẫn tồn tại sau khi kết thúc thực thi chương trình và sau đó có thể được một chương trình khác truy xuất trực tiếp.
Việc lưu trữ liên tục các đối tượng chương trình và cấu trúc dữ liệu là một chức năng quan trọng của hệ thống cơ sở dữ liệu. Các hệ thống cơ sở dữ liệu truyền thống thường gặp phải vấn đề gọi là không khớp, vì cấu trúc dữ liệu do DBMS cung cấp không tương thích với cấu trúc dữ liệu của ngôn ngữ lập trình. Hệ thống cơ sở dữ liệu hướng đối tượng thường cung cấp khả năng tương thích cấu trúc dữ liệu với một hoặc nhiều ngôn ngữ lập trình hướng đối tượng.
5.4 Cung cấp cấu trúc lưu trữ và tìm kiếm, kỹ thuật xử lý truy vấn hiệu quả
Hệ thống cơ sở dữ liệu phải cung cấp các khả năng để thực thi các truy vấn và cập nhật một cách hiệu quả. Vì cơ sở dữ liệu thường được lưu trữ trên ổ cứng, DBMS phải cung cấp các cấu trúc dữ liệu chuyên biệt và các kỹ thuật tìm kiếm để tăng tốc độ tìm kiếm trên ổ cứngcho các bản ghi mong muốn. Các tệp phụ trợ được gọi là chỉ mục thường được sử dụng cho mục đích này. Các chỉ mục thường dựa trên cấu trúc dữ liệu dạng cây hoặc cấu trúc dữ liệu băm được sửa đổi phù hợp để tìm kiếm trên ổ cứng. Để xử lý các bản ghi cơ sở dữ liệu cần thiết bởi một truy vấn cụ thể, các bản ghi đó phải được sao chép từ ổ cứng vào bộ nhớ chính. Do đó, DBMS thường có một mô-đun đệm hoặc bộ nhớ đệm để duy trì các phần của cơ sở dữ liệu trong các bộ đệm bộ nhớ chính. Nói chung, hệ điều hành có khả năng phục hồi để đệm ổ cứng vào bộ nhớ. Tuy nhiên, vì bộ đệm dữ liệu rất quan trọng đối với hiệu suất của DBMS, nên hầu hết các DBMS đều thực hiện bộ đệm dữ liệu của riêng chúng.
Mô-đun xử lý và tối ưu hóa truy vấn của DBMS chịu trách nhiệm chọn một kế hoạch thực thi truy vấn hiệu quả cho mỗi truy vấn dựa trên cấu trúc lưu trữ hiện có. Việc lựa chọn chỉ mục nào để tạo và duy trì là một phần của thiết kế và điều chỉnh cơ sở dữ liệu vật lý, đây là một trong những trách nhiệm của nhân viên DBA
5.5 Cung cấp khả năng sao lưu và phục hồi
DBMS phải cung cấp các phương tiện để khôi phục từ các lỗi phần cứng hoặc phần mềm. Hệ thống con sao lưu và phục hồi của DBMS chịu trách nhiệm khôi phục. Ví dụ: nếu hệ thống máy tính bị lỗi giữa một giao dịch cập nhật phức tạp, hệ thống con phục hồi có trách nhiệm đảm bảo rằng cơ sở dữ liệu được khôi phục về trạng thái trước khi giao dịch bắt đầu thực hiện. Sao lưu ổ cứng cũng cần thiết trong trường hợp ổ cứng bị lỗi nghiêm trọng
5.6 Cung cấp giao diện cho nhiều người dùng
Vì nhiều kiểu người dùng với các mức độ hiểu biết kỹ thuật khác nhau sử dụng cơ sở dữ liệu, nên DBMS phải cung cấp nhiều giao diện người dùng khác nhau. Chúng bao gồm các ứng dụng cho người dùng di động, ngôn ngữ truy vấn cho người dùng thông thường, giao diện ngôn ngữ lập trình cho người lập trình ứng dụng, biểu mẫu và mã lệnh cho người dùng tham số và giao diện hướng menu và giao diện ngôn ngữ tự nhiên cho người dùng độc lập. Cả giao diện kiểu biểu mẫu và giao diện hướng menu thường được gọi là giao diện người dùng đồ họa (GUI). Nhiều ngôn ngữ và môi trường chuyên biệt tồn tại để chỉ định GUI. Khả năng cung cấp giao diện web GUI cho cơ sở dữ liệu — hoặc hỗ trợ cơ sở dữ liệu web — cũng khá phổ biến.
5.7 Thể hiện mối quan hệ phức tạp giữa các dữ liệu
Một cơ sở dữ liệu có thể bao gồm nhiều loại dữ liệu có liên quan với nhau theo nhiều cách. Hãy xem xét ví dụ trong hình trên. Bản ghi cho ‘Brown’ trong tệp STUDENT liên quan đến bốn bản ghi trong tệp GRADE_REPORT. Tương tự, mỗi bản ghi SECTION có liên quan đến một hồ sơ khóa học và một số bản ghi GRADE_REPORT — một bản ghi cho mỗi học sinh đã hoàn thành phần đó. Một DBMS phải có khả năng đại diện cho nhiều mối quan hệ phức tạp giữa dữ liệu, để xác định các mối quan hệ mới khi chúng phát sinh, đồng thời truy xuất và cập nhật dữ liệu liên quan một cách dễ dàng và hiệu quả.
5.8 Thực thi các ràng buộc về mặt logic
Hầu hết các ứng dụng cơ sở dữ liệu có các ràng buộc toàn vẹn dữ liệu. DBMS phải cung cấp các khả năng để xác định và thực thi các ràng buộc này. Loại ràng buộc toàn vẹn đơn giản nhất liên quan đến việc chỉ định một kiểu dữ liệu cho mỗi mục dữ liệu. Ví dụ, trong hình dưới, chúng ta đã chỉ định rằng giá trị của mục dữ liệu GRADE trong mỗi bản ghi STUDENT phải là số nguyên có một chữ số và giá trị của NAME phải là một chuỗi không quá 30 ký tự chữ cái. Để hạn chế giá trị của GRADE từ 1 đến 5 sẽ là một ràng buộc bổ sung không được hiển thị trong danh mục hiện tại. Một loại ràng buộc phức tạp hơn thường xuyên xảy ra liên quan đến việc chỉ định rằng một bản ghi trong một tệp phải liên quan đến các bản ghi trong các tệp khác. Ví dụ, trong Hình b, chúng ta có thể chỉ định rằng mọi bản ghi SECTION phải liên quan đến một bản ghi COURSE. Điều này được gọi là một toàn vẹn tham chiếu. Một loại ràng buộc khác chỉ định tính duy nhất trên các giá trị mục dữ liệu, chẳng hạn như mọi bản ghi khóa học phải có một giá trị duy nhất cho Course_number. Điều này được gọi là một khóa hoặc ràng buộc duy nhất. Những ràng buộc này bắt nguồn từ ý nghĩa hoặc ngữ nghĩa của dữ liệu và của thế giới nhỏ mà nó đại diện. Người thiết kế cơ sở dữ liệu có trách nhiệm xác định các ràng buộc toàn vẹn trong quá trình thiết kế cơ sở dữ liệu. Một số ràng buộc có thể được chỉ định cho DBMS và được thực thi tự động. Các ràng buộc khác có thể phải được kiểm tra bằng các chương trình cập nhật hoặc tại thời điểm nhập dữ liệu. Đối với các ứng dụng lớn điển hình, thường gọi các ràng buộc như vậy là các quy tắc nghiệp vụ.
Một mục dữ liệu có thể được nhập sai và vẫn đáp ứng các ràng buộc toàn vẹn đã chỉ định. Ví dụ: nếu một học sinh nhận được điểm ‘A’ nhưng điểm ‘C’ được nhập vào cơ sở dữ liệu, thì DBMS không thể tự động phát hiện ra lỗi này vì ‘C’ là giá trị hợp lệ cho kiểu dữ liệu Điểm. Những lỗi nhập dữ liệu như vậy chỉ có thể được phát hiện theo cách thủ công (khi học sinh nhận điểm và khiếu nại) và sửa chữa sau đó bằng cách cập nhật cơ sở dữ liệu. Tuy nhiên, cấp ‘Z’ sẽ tự động bị DBMS từ chối vì ‘Z’ không phải là giá trị hợp lệ cho kiểu dữ liệu GRADE
5.9 Cho phép suy diễn và hành động bằng cách sử dụng quy tắc và đồng bộ (trigger)
Một số hệ thống cơ sở dữ liệu cung cấp khả năng xác định các quy tắc suy luận để suy ra thông tin mới từ các dữ kiện cơ sở dữ liệu được lưu trữ. Hệ thống như vậy được gọi là hệ thống cơ sở dữ liệu suy diễn. Ví dụ, có thể có những quy tắc phức tạp trong ứng dụng thế giới nhỏ để xác định thời điểm một sinh viên đang trong thời gian quản chế. Các quy tắc này có thể được chỉ định một cách khai báo dưới dạng các quy tắc, khi được biên soạn và duy trì bởi DBMS có thể xác định tất cả các sinh viên đang trong thời gian tập sự. Trong một DBMS truyền thống, một mã chương trình thủ tục (procedure) rõ ràng sẽ phải được viết để hỗ trợ các ứng dụng như vậy. Nhưng nếu các quy tắc của thế giới nhỏ thay đổi, nói chung sẽ thuận tiện hơn để thay đổi các quy tắc khấu trừ đã khai báo hơn là mã hóa lại các chương trình thủ tục. Trong các hệ thống cơ sở dữ liệu quan hệ ngày nay, có thể kết hợp trigger với các bảng. Trigger là một dạng quy tắc được kích hoạt bởi các bản cập nhật cho bảng, dẫn đến việc thực hiện một số hoạt động bổ sung cho một số bảng khác, gửi tin nhắn, v.v. Các biện pháp proce liên quan nhiều hơn để thực thi các quy tắc thường được gọi là các thủ tục được lưu trữ; chúng trở thành một phần của định nghĩa cơ sở dữ liệu tổng thể và được gọi một cách thích hợp khi đáp ứng các điều kiện nhất định. Chức năng mạnh mẽ hơn được cung cấp bởi các hệ thống cơ sở dữ liệu đang hoạt động, cung cấp các quy tắc hoạt động có thể tự động bắt đầu các hành động khi các sự kiện và điều kiện nhất định xảy ra
5.10 Các lợi ích khác
Khả năng thực thi các tiêu chuẩn. Cách tiếp cận cơ sở dữ liệu cho phép DBA xác định và thực thi các tiêu chuẩn giữa những người sử dụng cơ sở dữ liệu trong một tổ chức lớn. Điều này tạo điều kiện thuận lợi cho việc giao tiếp và hợp tác giữa các phòng ban, dự án và người dùng khác nhau trong tổ chức. Các tiêu chuẩn có thể được xác định cho tên và định dạng của các phần tử dữ liệu, định dạng hiển thị, cấu trúc báo cáo, thuật ngữ, v.v. DBA có thể thực thi các tiêu chuẩn trong môi trường cơ sở dữ liệu tập trung dễ dàng hơn so với môi trường mà mỗi nhóm người dùng có quyền kiểm soát các tệp dữ liệu và phần mềm của riêng mình.
Giảm thời gian phát triển ứng dụng. Một đặc điểm nổi bật của phương pháp tiếp cận cơ sở dữ liệu là việc phát triển một ứng dụng mới — chẳng hạn như việc truy xuất một số dữ liệu nhất định từ cơ sở dữ liệu để in một báo cáo mới — mất rất ít thời gian. Việc thiết kế và triển khai một cơ sở dữ liệu đa người dùng lớn từ đầu có thể mất nhiều thời gian hơn so với việc viết một ứng dụng tệp chuyên biệt. Tuy nhiên, một khi cơ sở dữ liệu được thiết lập và đang chạy, thường cần ít thời gian hơn đáng kể để tạo các ứng dụng mới bằng cách sử dụng các cơ sở DBMS. Thời gian phát triển sử dụng DBMS được ước tính bằng 1/6 đến 1/4 thời gian đối với hệ thống tệp
Uyển chuyển. Có thể cần phải thay đổi cấu trúc của cơ sở dữ liệu khi có yêu cầu thay đổi. Ví dụ, một nhóm người dùng mới có thể xuất hiện cần thông tin hiện không có trong cơ sở dữ liệu. Đáp lại, có thể cần thêm tệp vào cơ sở dữ liệu hoặc mở rộng các phần tử dữ liệu trong tệp hiện có. Các DBMS hiện đại cho phép một số kiểu thay đổi hiện đại nhất định đối với cấu trúc của cơ sở dữ liệu mà không ảnh hưởng đến việc nhập dữ liệu được lưu trữ và các chương trình ứng dụng hiện có.
Hiệu quả kinh tế. Cách tiếp cận DBMS cho phép hợp nhất dữ liệu và ứng dụng, do đó giảm số lượng chồng chéo lãng phí giữa các hoạt động của nhân viên xử lý dữ liệu trong các dự án hoặc phòng ban khác nhau cũng như các tệp dự phòng giữa các ứng dụng. Điều này cho phép toàn bộ tổ chức đầu tư vào các bộ xử lý, thiết bị lưu trữ hoặc thiết bị mạng mạnh mẽ hơn, thay vì để mỗi bộ phận mua thiết bị riêng (hiệu suất thấp hơn). Điều này làm giảm tổng chi phí vận hành và quản lý.
6. Sơ lược về lịch sử ứng dụng cơ sở dữ liệu
Bây giờ chúng ta tìm hiểu tổng quan lịch sử ngắn gọn về các ứng dụng sử dụng DBMS và cách các ứng dụng này tạo động lực cho các loại hệ thống cơ sở dữ liệu mới.
6.1 Các ứng dụng cơ sở dữ liệu ban đầu sử dụng hệ thống phân cấp và mạng
Nhiều ứng dụng cơ sở dữ liệu ban đầu duy trì bản ghi của các tổ chức lớn như tập đoàn, trường đại học, bệnh viện và ngân hàng. Trong nhiều ứng dụng này, có một số lượng lớn các bản ghi có cấu trúc tương tự. Ví dụ, trong một ứng dụng quản lý thông tin sinh viên của trường đại học, thông tin tương tự sẽ được lưu giữ cho mỗi học sinh, mỗi khóa học, mỗi hồ sơ điểm, v.v. Cũng có nhiều loại hồ sơ và nhiều mối quan hệ giữa chúng.
Một trong những vấn đề chính đối với các hệ thống cơ sở dữ liệu ban đầu là sự đan xen giữa các mối quan hệ liên tục với việc lưu trữ vật lý và sắp xếp các bản ghi trên ổ đĩa. Do đó, các hệ thống này không cung cấp đủ khả năng trừu tượng hóa dữ liệu và độc lập dữ liệu chương trình. Ví dụ, hồ sơ điểm của một học sinh cụ thể có thể được lưu trữ vật lý bên cạnh hồ sơ học sinh. Mặc dù điều này cung cấp quyền truy cập rất hiệu quả cho các truy vấn và giao dịch ban đầu mà cơ sở dữ liệu được thiết kế để xử lý, nhưng nó không cung cấp đủ tính linh hoạt để truy cập các bản ghi một cách hiệu quả khi các truy vấn và giao dịch mới được xác định. Đặc biệt, các truy vấn mới yêu cầu một tổ chức lưu trữ khác để xử lý hiệu quả khá khó thực hiện một cách hiệu quả. Việc tổ chức lại cơ sở dữ liệu cũng rất tốn công sức khi thực hiện các thay đổi đối với các yêu cầu của ứng dụng.
Một thiếu sót khác của các hệ thống ban đầu là chúng chỉ cung cấp các giao diện ngôn ngữ lập trình. Điều này làm cho việc triển khai các truy vấn và giao dịch mới tốn nhiều thời gian và tốn kém, vì các chương trình mới phải được viết, thử nghiệm và gỡ lỗi. Hầu hết các hệ thống cơ sở dữ liệu này đã được triển khai trên các máy tính lớn và đắt tiền bắt đầu từ giữa những năm 1960 và tiếp tục qua những năm 1970 và 1980. Các loại hệ thống ban đầu chính dựa trên ba mô hình chính: hệ thống phân cấp, hệ thống dựa trên mô hình mạng và hệ thống tệp đảo ngược (inverted file systems)
6.2 Cung cấp tính trừu tượng hóa dữ liệu và tính linh hoạt của ứng dụng với Cơ sở dữ liệu quan hệ
Cơ sở dữ liệu quan hệ ban đầu được đề xuất để tách lưu trữ vật lý của dữ liệu khỏi biểu diễn khái niệm của nó và cung cấp nền tảng toán học cho việc biểu diễn và truy vấn dữ liệu. Mô hình dữ liệu quan hệ cũng giới thiệu các ngôn ngữ truy vấn cấp cao cung cấp một sự thay thế cho các giao diện ngôn ngữ lập trình, giúp việc viết các truy vấn mới nhanh hơn nhiều. Biểu diễn quan hệ của dữ liệu. Các mục tiêu ban đầu của hệ thống quan hệ nhắm đến các ứng dụng tương tự như các hệ thống trước đó và cung cấp sự linh hoạt để phát triển các truy vấn mới một cách nhanh chóng và tổ chức lại cơ sở dữ liệu khi các yêu cầu thay đổi. Do đó, tính trừu tượng hóa dữ liệu và tính độc lập của chương trình-dữ liệu đã được cải thiện nhiều so với các hệ thống trước đó.
Các hệ thống quan hệ thử nghiệm ban đầu được phát triển vào cuối những năm 1970 và hệ thống quản lý cơ sở dữ liệu quan hệ (RDBMS) được giới thiệu vào đầu những năm 1980 khá chậm, vì chúng không sử dụng con trỏ lưu trữ vật lý hoặc vị trí bản ghi để truy cập các bản ghi dữ liệu liên quan. Với sự phát triển của các kỹ thuật lưu trữ và lập chỉ mục mới cũng như xử lý và tối ưu hóa truy vấn tốt hơn, hiệu suất của chúng được cải thiện. Cuối cùng, cơ sở dữ liệu quan hệ đã trở thành loại hệ thống cơ sở dữ liệu thay cho các ứng dụng cơ sở dữ liệu truyền thống. Cơ sở dữ liệu quan hệ hiện tồn tại trên hầu hết các loại máy tính, từ máy tính cá nhân nhỏ đến máy chủ lớn
6.3 Ứng dụng hướng đối tượng và nhu cầu về cơ sở dữ liệu phức tạp hơn
Sự xuất hiện của các ngôn ngữ lập trình hướng đối tượng trong những năm 1980 và nhu cầu lưu trữ và chia sẻ các đối tượng có cấu trúc, phức tạp đã dẫn đến sự phát triển của cơ sở dữ liệu hướng đối tượng (OODB). Ban đầu, OODB được coi là đối thủ cạnh tranh với cơ sở dữ liệu quan hệ, vì chúng cung cấp các cấu trúc dữ liệu tổng quát hơn. Họ cũng kết hợp nhiều mô hình hướng đối tượng hữu ích, chẳng hạn như kiểu dữ liệu trừu tượng, các tính toán mang tính đóng gói, kế thừa và nhận dạng đối tượng. Tuy nhiên, sự phức tạp của mô hình và việc thiếu một tiêu chuẩn ban đầu đã góp phần vào việc sử dụng nó một cách hạn chế. Hiện nay chúng chủ yếu được sử dụng trong các ứng dụng chuyên biệt, chẳng hạn như thiết kế kỹ thuật, xuất bản đa phương tiện và hệ thống sản xuất. Mặc dù kỳ vọng rằng họ sẽ tạo ra tác động lớn, nhưng mức độ thâm nhập tổng thể của họ vào thị trường cơ sở dữ liệu vẫn ở mức thấp. Ngoài ra, nhiều khái niệm hướng đối tượng đã được đưa vào các phiên bản mới hơn của RDBMS, dẫn đến hệ thống quản lý cơ sở dữ liệu quan hệ đối tượng, được gọi là ORDBMS.
6.4 Trao đổi dữ liệu trên web cho thương mại điện tử bằng XML
World Wide Web cung cấp một mạng lớn các máy tính được kết nối với nhau. Người dùng có thể tạo các trang web tĩnh bằng ngôn ngữ xuất bản web, chẳng hạn như Hyper text markup language (HTML) và lưu trữ các tài liệu này trên máy chủ web nơi người dùng khác (khách hàng) có thể truy cập và xem chúng thông qua trình duyệt Web. Các tài liệu có thể được liên kết thông qua các đường link, là các con trỏ đến các tài liệu khác. Bắt đầu từ những năm 1990, thương mại điện tử (e-commerce) nổi lên như một ứng dụng chính trên Web. Phần lớn thông tin quan trọng trên các trang Web thương mại điện tử được trích xuất động dữ liệu từ các DBMS, chẳng hạn như thông tin chuyến bay, giá hàng hóa và tồn kho của sản phẩm. Nhiều kỹ thuật đã được phát triển để cho phép trao đổi dữ liệu được trích xuất động trên Web để hiển thị trên các trang Web. Extended Markup Language (XML) là một tiêu chuẩn để trao đổi dữ liệu giữa các loại cơ sở dữ liệu và trang Web. XML kết hợp các khái niệm từ các mô hình được sử dụng trong hệ thống tài liệu với các khái niệm mô hình cơ sở dữ liệu
6.5 Mở rộng khả năng cơ sở dữ liệu cho các ứng dụng mới
Sự thành công của các hệ thống cơ sở dữ liệu trong các ứng dụng truyền thống đã khuyến khích các nhà phát triển của các loại ứng dụng khác cố gắng sử dụng chúng. Các ứng dụng như vậy thường sử dụng phần mềm chuyên dụng và cấu trúc tệp và dữ liệu của riêng chúng. Các hệ thống cơ sở dữ liệu hiện cung cấp các phần mở rộng để hỗ trợ tốt hơn các yêu cầu chuyên biệt cho một số ứng dụng này. Sau đây là một số ví dụ về các ứng dụng này:
-
Các ứng dụng khoa học lưu trữ lượng lớn dữ liệu thu được từ các thí nghiệm khoa học kỹ thuật trong các lĩnh vực như vật lý năng lượng cao, lập bản đồ bộ gen người và khám phá cấu trúc protein
-
Lưu trữ và truy xuất hình ảnh, bao gồm tin tức được quét hoặc đồ thị hình ảnh cá nhân, hình ảnh chụp từ vệ tinh và hình ảnh từ các thủ tục y tế như chụp X-quang và xét nghiệm MRI (chụp cộng hưởng từ)
-
Lưu trữ và truy xuất video, chẳng hạn như phim và video clip từ tin tức hoặc máy ảnh kỹ thuật số cá nhân
-
Các ứng dụng khai thác dữ liệu phân tích lượng lớn dữ liệu để tìm kiếm sự xuất hiện của các mẫu hoặc mối quan hệ cụ thể và để xác định các mẫu bất thường trong các lĩnh vực như phát hiện gian lận thẻ tín dụng
-
Các ứng dụng không gian lưu trữ và phân tích dữ liệu vị trí không gian, chẳng hạn như thông tin thời tiết, bản đồ được sử dụng trong hệ thống thông tin địa lý và hệ thống định vị ô tô
-
Các ứng dụng phân tích dữ liệu theo thời gian lưu trữ thông tin chẳng hạn như dữ liệu kinh tế tại các thời điểm thông thường, doanh số hàng ngày và số liệu tổng sản phẩm quốc dân hàng tháng
Rõ ràng là các hệ thống quan hệ cơ bản không phù hợp lắm với nhiều ứng dụng này, thường vì một hoặc nhiều lý do sau
-
Các cấu trúc dữ liệu phức tạp hơn cần thiết để mô hình hóa ứng dụng hơn là biểu diễn quan hệ đơn giản
-
Cần có các kiểu dữ liệu mới ngoài các kiểu chuỗi ký tự và số cơ bản
-
Các phép toán mới và cấu trúc ngôn ngữ truy vấn là cần thiết để thao tác với các kiểu dữ liệu mới
-
Các cấu trúc lưu trữ và lập chỉ mục mới là cần thiết để tìm kiếm hiệu quả các kiểu dữ liệu mới.
Điều này khiến các nhà phát triển DBMS bổ sung thêm chức năng cho hệ thống của họ. Một số chức năng là mục đích chung, chẳng hạn như kết hợp các khái niệm từ cơ sở dữ liệu hướng đối tượng vào các hệ thống quan hệ. Chức năng khác có mục đích đặc biệt, dưới dạng các mô-đun tùy chọn có thể được sử dụng cho các ứng dụng cụ thể. Ví dụ: người dùng có thể mua một mô-đun theo dõi dữ liệu theo thời gian để sử dụng với DBMS quan hệ của họ cho ứng dụng theo dõi dữ liệu theo thời gian của họ
6.6 Sự xuất hiện của Hệ thống lưu trữ dữ liệu lớn và Cơ sở dữ liệu NOSQL
Trong thập kỷ đầu tiên của thế kỷ XXI, sự gia tăng của các ứng dụng và nền tảng như các trang web truyền thông xã hội, các công ty thương mại điện tử lớn, chỉ mục tìm kiếm trên web và lưu trữ / sao lưu đám mây đã dẫn đến sự gia tăng số lượng dữ liệu được lưu trữ trên các cơ sở dữ liệu lớn. và các máy chủ lớn. Các loại hệ thống cơ sở dữ liệu mới là cần thiết để quản lý các cơ sở dữ liệu khổng lồ này — các hệ thống cung cấp khả năng tìm kiếm và truy xuất nhanh chóng cũng như lưu trữ an toàn và đáng tin cậy đối với các loại dữ liệu phi truyền thống, chẳng hạn như các bài đăng và tweet trên mạng xã hội. Một số yêu cầu của các hệ thống mới này không tương thích với các DBMS quan hệ SQL (SQL là ngôn ngữ và mô hình dữ liệu chuẩn cho cơ sở dữ liệu quan hệ). Thuật ngữ NOSQL thường được hiểu là Not Only SQL, có nghĩa là trong các hệ thống ngoài việc quản lý lượng lớn dữ liệu, một số dữ liệu được lưu trữ bằng hệ thống SQL, trong khi dữ liệu khác sẽ được lưu trữ bằng NOSQL, tùy thuộc vào yêu cầu ứng dụng.
7. Những trường hợp không nên sử dụng DBMS
Mặc dù có những ưu điểm của việc sử dụng DBMS, có một số tình huống trong đó DBMS có thể liên quan đến các chi phí chung không cần thiết mà sẽ không phát sinh trong quá trình xử lý tệp truyền thống. Chi phí chung của việc sử dụng DBMS là do những điều sau đây
-
Đầu tư ban đầu cao vào phần cứng, phần mềm và đào tạo
-
Tính tổng quát mà một DBMS cung cấp để xác định và xử lý dữ liệu
-
Chi phí cung cấp chức năng bảo mật, kiểm soát đồng thời, khôi phục và tính toàn vẹn
Do đó, có thể không cần thiết trong việc sử dụng cơ sở dữ liệu trong các trường hợp sau:
-
Các ứng dụng cơ sở dữ liệu đơn giản, được xác định rõ ràng và không có gì thay đổi
-
Các yêu cầu nghiêm ngặt, theo thời gian thực đối với một số chương trình ứng dụng có thể không được đáp ứng do chi phí DBMS
-
Hệ thống nhúng có dung lượng lưu trữ hạn chế, trong đó DBMS có mục đích chung sẽ không phù hợp
-
Không có nhiều người dùng truy cập vào dữ liệu này
Một số ngành và ứng dụng nhất định đã chọn không sử dụng các DBMS có mục đích chung. Ví dụ: nhiều công cụ thiết kế có sự hỗ trợ của máy tính (CAD) được sử dụng bởi các kỹ sư cơ khí và dân dụng có phần mềm quản lý dữ liệu và tệp độc quyền dành cho các thao tác bên trong bản vẽ và vật thể 3D. Tương tự, các hệ thống liên lạc và chuyển mạch được thiết kế bởi các công ty như AT&T là biểu hiện ban đầu của phần mềm cơ sở dữ liệu được tạo ra để chạy rất nhanh với dữ liệu được tổ chức phân cấp để truy cập và định tuyến cuộc gọi nhanh chóng. Đề cập đến GIS thường triển khai các sơ đồ tổ chức dữ liệu của riêng họ để thực hiện hiệu quả các chức năng liên quan đến xử lý bản đồ, đường nét vật lý, đường thẳng, đa giác, v.v.
8. Tóm tắt
Bài viết khá dài nên mình sẽ tóm tắt các ý chính trong phần dưới đây để bạn đọc dễ theo dõi. Trong phần này chúng ta được làm quen và giới thiệu các khái niệm liên quan đến hệ quản trị cơ sở dữ liệu và các ý chính như sau
- Dữ liệu (data) là các thông tin hay dữ kiện có ý nghĩa có thể là hình ảnh, văn bản và có thể ghi nhận và lưu trữ
- Cơ sở dữ liệu (database) là tập hợp có tổ chức các liệu có quan hệ luận lý với nhau. Siêu dữ liệu (Metadata) là dữ liệu dùng để mô tả đặc trưng của các dữ liệu khác như cấu trúc dữ liệu, ràng buộc dữ liệu
- Trước khi có sự xuất hiện của hệ quản trị cơ sở dữ liệu các hướng tiếp cận trước đây là hệ thống xử lý tập tin với các nhược điểm chính là phụ thuộc giữa chương trình và dữ liệu, sự dư thừa dữ liệu, hạn chế trong chia sẻ dữ liệu và chi phí bảo trì lớn (chiếm 80% ngân sách hệ thống) cũng như thời gian phát triển chương trình bị kéo dài
- Các tiếp cận cơ sở dữ liệu mang lại sự lưu trữ tập trung các dữ liệu và hỗ trợ chia sẻ dữ liệu tốt hơn, dữ liệu được quản lý chuyên trách hơn, tách biệt giữa chương trình và dữ liệu -> Cần một hệ quản trị cơ sở dữ liệu
- Trong một số trường hợp cụ thể bạn cũng nên cân nhắc có nên sử dụng hệ quản trị cơ sở dữ liệu hay không
Chúc bạn đọc vui vẻ!
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Kiến trúc của các gói DBMS đã phát triển từ các hệ thống nguyên khối ban đầu, trong đó toàn bộ gói phần mềm DBMS là một hệ thống tích hợp chặt chẽ, đến các gói DBMS hiện đại được thiết kế theo dạng mô-đun, với kiến trúc client / server trong bài hôm nay mình cùng tìm hiểu về khái niệm và kiến trúc hệ quản trị cơ sở dữ liệu
Mô hình hóa khái niệm là một giai đoạn rất quan trọng trong việc thiết kế một ứng dụng cơ sở dữ liệu thành công. Thông thường, thuật ngữ ứng dụng cơ sở dữ liệu đề cập đến một cơ sở dữ liệu cụ thể và các chương trình liên quan thực hiện các truy vấn và cập nhật cơ sở dữ liệu. Trong bài này chúng ta sẽ tìm hiểu mô hình hóa dữ liệu với sơ đồ ER
Các khái niệm mô hình ER được thảo luận trong Chương 3 là đủ để biểu diễn nhiều lược đồ cơ sở dữ liệu cho các ứng dụng cơ sở dữ liệu truyền thống, bao gồm nhiều ứng dụng xử lý dữ liệu trong kinh doanh và công nghiệp. Tuy nhiên, kể từ cuối những năm 1970, các nhà thiết kế ứng dụng cơ sở dữ liệu đã cố gắng thiết kế các lược đồ cơ sở dữ liệu chính xác hơn phản ánh các thuộc tính và ràng buộc dữ liệu một cách chính xác hơn từ đó chúng ta có mô hình thực thể mối quan hệ mở rộng - EER
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên