Chương 4: Mô hình thực thể mối quan hệ mở rộng (EER)

Nội dung bài viết
Các khái niệm mô hình ER được thảo luận trong Chương 3 là đủ để biểu diễn nhiều lược đồ cơ sở dữ liệu cho các ứng dụng cơ sở dữ liệu truyền thống, bao gồm nhiều ứng dụng xử lý dữ liệu trong kinh doanh và công nghiệp. Tuy nhiên, kể từ cuối những năm 1970, các nhà thiết kế ứng dụng cơ sở dữ liệu đã cố gắng thiết kế các lược đồ cơ sở dữ liệu chính xác hơn phản ánh các thuộc tính và ràng buộc dữ liệu một cách chính xác hơn. Điều này đặc biệt quan trọng đối với các ứng dụng mới hơn của công nghệ cơ sở dữ liệu, chẳng hạn như cơ sở dữ liệu cho thiết kế và chế tạo kỹ thuật (CAD / CAM), viễn thông, hệ thống phần mềm phức tạp và hệ thống thông tin địa lý (GIS), trong số nhiều ứng dụng khác. Các loại cơ sở dữ liệu này có các yêu cầu phức tạp hơn so với các ứng dụng truyền thống. Điều này dẫn đến sự phát triển của các khái niệm mô hình dữ liệu ngữ nghĩa bổ sung được kết hợp vào các mô hình dữ liệu khái niệm như mô hình ER. Các mô hình dữ liệu ngữ nghĩa khác nhau đã được đề xuất trong tài liệu. Nhiều khái niệm trong số này cũng được phát triển độc lập trong các lĩnh vực liên quan của khoa học máy tính, chẳng hạn như lĩnh vực biểu diễn tri thức của trí tuệ nhân tạo và lĩnh vực mô hình hóa đối tượng trong kỹ thuật phần mềm
Trong chương này, chúng ta mô tả các tính năng đã được đề xuất cho các mô hình dữ liệu ngữ nghĩa và chỉ ra cách mô hình ER có thể được nâng cao để bao gồm các khái niệm này, dẫn đến mô hình ER mở rộng (EER ). Chúng ta bắt đầu bằng cách kết hợp các khái niệm của các mối quan hệ lớp cha / lớp con và kiểu kế thừa vào mô hình ER. Sau đó chúng ta bổ sung các khái niệm chuyên môn hóa và tổng quát hóa. Tiếp theo thảo luận về các loại ràng buộc khác nhau đối với chuyên môn hóa / tổng quát hóa. Hơn nữa cho thấy cách cấu trúc UNION có thể được mô hình hóa bằng cách đưa khái niệm danh mục vào mô hình EER. Ngoài ra cũng đưa ra một lược đồ cơ sở dữ liệu UNIVERSITY mẫu trong mô hình EER và tóm tắt các khái niệm mô hình EER bằng cách đưa ra các định nghĩa chính thức. Chúng ta sẽ sử dụng các thuật ngữ đối tượng và thực thể thay thế cho nhau trong chương này, bởi vì nhiều khái niệm này thường được sử dụng trong mô hình hướng đối tượng
Chúng ta sẽ trình bày ký hiệu sơ đồ lớp UML để biểu diễn chuyên môn hóa và tổng quát hóa trong chương nà, và chúng ta so sánh ngắn gọn chúng với ký hiệu và khái niệm EER. Đây là một ví dụ về ký hiệu thay thế trong chương 3, phần này đã trình bày ký hiệu sơ đồ lớp UML cơ bản tương ứng với mô hình ER cơ bản. Cuối cùng, chúng ta thảo luận về các yếu tố trừu tượng cơ bản được sử dụng làm cơ sở của nhiều mô hình dữ liệu ngữ nghĩa.
1. Lớp con, lớp cha và tính kế thừa
Mô hình EER bao gồm tất cả các khái niệm mô hình hóa của mô hình ER đã đượctrình bày trong chương trước đó. Ngoài ra, nó bao gồm các khái niệm về lớp con và lớp cha và các khái niệm liên quan về chuyên môn hóa và tổng quát hóa. Một khái niệm khác bao gồm trong mô hình EER là một loại hoặc kiểu liên hợp được sử dụng để đại diện cho một tập hợp các đối tượng (thực thể) là sự kết hợp của các đối tượng thuộc các kiểu thực thể khác nhau. Gắn liền với các khái niệm này là cơ chế quan trọng của sự kế thừa thuộc tính và quan hệ. Thật không may, không có thuật ngữ chuẩn nào tồn tại cho những khái niệm này, vì vậy chúng tôi sử dụng thuật ngữ phổ biến nhất. Thuật ngữ thay thế được đưa ra trong phần chú thích. Chúng tôi cũng mô tả một kỹ thuật sơ đồ để hiển thị những khái niệm này khi chúng xuất hiện trong một lược đồ EER. Chúng tôi gọi các sơ đồ này là sơ đồ ER hoặc EER – sơ đồ thực thể quan hệ nâng cao
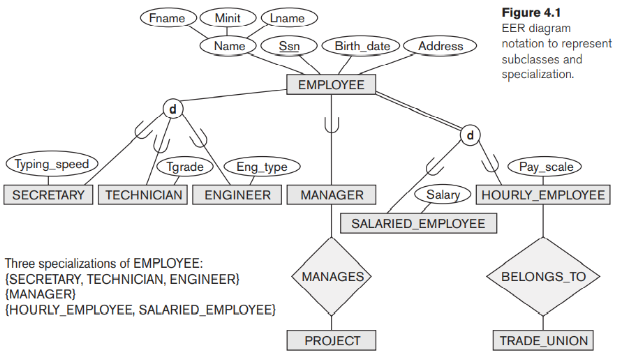
Khái niệm mô hình ER (EER) nâng cao đầu tiên mà chúng tôi sử dụng là một kiểu con hoặc lớp con của một kiểu thực thể. Như chúng ta đã thảo luận trong Chương 3, tên của một loại thực thể được sử dụng để đại diện cho cả một loại thực thể và tập thực thể hoặc tập hợp các thực thể của loại đó tồn tại trong cơ sở dữ liệu. Ví dụ: loại thực thể EMPLOYEE mô tả thuộc tính (nghĩa là, các thuộc tính và mối quan hệ) của mỗi thực thể nhân viên và cũng đề cập đến tập hợp các thực thể EMPLOYEE hiện tại trong cơ sở dữ liệu COMPANY. Trong nhiều trường hợp, một kiểu thực thể có nhiều nhóm con hoặc kiểu con của các thực thể của nó có ý nghĩa và cần được trình bày một cách rõ ràng vì tầm quan trọng của chúng đối với ứng dụng cơ sở dữ liệu. Ví dụ: các thực thể là thành viên của loại thực thể EMPLOYEE có thể được phân biệt thêm thành SECRETARY, ENGINEER, MANAGER, TECHNICIAN, SALARIED_EMPLOYEE, HOURLY_EMPLOYEE, v.v. Tập hợp hoặc tập hợp các thực thể trong mỗi nhóm sau này là một tập con của các thực thể thuộc tập thực thể EMPLOYEE, có nghĩa là mọi thực thể là thành viên của một trong các nhóm con này cũng là một nhân viên. Chúng tôi gọi mỗi nhóm con này là lớp con hoặc kiểu con của kiểu thực thể EMPLOYEE và kiểu thực thể EMPLOYEE được gọi là lớp con hoặc kiểu siêu cấp cho mỗi lớp con này. Hình 4.1 cho thấy cách biểu diễn các khái niệm này một cách sơ đồ trong biểu đồ EER.
Chúng ta gọi mối quan hệ giữa lớp cha và bất kỳ lớp con nào của nó là lớp cha / lớp con hoặc kiểu cha / kiểu con hoặc đơn giản là mối quan hệ lớp / lớp con. Trong ví dụ trước của chúng ta, EMPLOYEE / SECRETARY và EMPLOYEE / TECHNICIAN là hai mối quan hệ lớp / lớp con. Lưu ý rằng một thực thể thành viên của lớp con đại diện cho cùng một thực thể trong thế giới thực với một số thành viên của lớp cha; ví dụ: thực thể SECRETARY ‘Joan Logano’ cũng là EMPLOYEE ‘Joan Logano’. Do đó, thành viên lớp con giống như thực thể trong lớp cha, nhưng ở một vai trò cụ thể riêng biệt. Tuy nhiên, khi chúng ta triển khai mối quan hệ lớp cha / lớp con trong hệ thống cơ sở dữ liệu, chúng ta có thể đại diện cho một thành viên của lớp con dưới dạng một đối tượng cơ sở dữ liệu riêng biệt — ví dụ, một bản ghi riêng biệt có liên quan thông qua thuộc tính khóa với thực thể lớp cha của nó.
Một thực thể không thể tồn tại trong cơ sở dữ liệu chỉ bằng cách là thành viên của một lớp con; nó cũng phải là một thành viên của lớp cha. Một thực thể như vậy có thể được tùy chọn bao gồm như một thành viên của bất kỳ lớp con nào. Ví dụ: một nhân viên làm công ăn lương cũng là một kỹ sư thuộc hai lớp con ENGINEER và SALARIED_EMPLOYEE của loại thực thể EMPLOYEE. Tuy nhiên, không nhất thiết mọi thực thể trong lớp cha đều là thành viên của lớp con nào đó.
Một khái niệm quan trọng liên quan đến lớp con (kiểu con) là kiểu kế thừa. Nhớ lại rằng kiểu của một thực thể được xác định bởi các thuộc tính mà nó sở hữu và các kiểu quan hệ mà nó tham gia. Bởi vì một thực thể trong lớp con đại diện cho cùng một thực thể trong thế giới thực từ lớp cha, nó phải có các giá trị cho các thuộc tính cụ thể của nó cũng như các giá trị của các thuộc tính của nó với tư cách là một thành viên của “cha”. Chúng ta nói rằng một thực thể là thành viên của lớp con kế thừa tất cả các thuộc tính của thực thể như một thành viên của lớp cha. Thực thể cũng kế thừa tất cả các mối quan hệ mà lớp cha tham gia. Lưu ý rằng một lớp con, với các thuộc tính và mối quan hệ cụ thể (hoặc cục bộ) của riêng nó cùng với tất cả các thuộc tính và mối quan hệ mà nó kế thừa từ lớp cha, có thể được coi là một kiểu thực thể theo đúng nghĩa của nó.
2. Chuyên môn hóa và tổng quát hóa
2.1 Chuyên môn hóa
Chuyên môn hóa là quá trình xác định một tập hợp các lớp con của một kiểu thực thể; kiểu thực thể này được gọi là lớp cha của chuyên ngành. Tập hợp các lớp con tạo thành một chuyên biệt được xác định trên cơ sở một số đặc điểm phân biệt của các thực thể trong lớp cha. Ví dụ: tập hợp các lớp con {SECRETARY, ENGINEER, TECHNICIAN} là một chuyên môn hóa của nhân viên cấp trên phân biệt giữa các thực thể nhân viên dựa trên loại công việc của mỗi nhân viên. Chúng tôi có thể có một số chuyên ngành của cùng một loại thực thể dựa trên các đặc điểm phân biệt khác nhau. Ví dụ: một chuyên môn hóa khác của loại thực thể EMPLOYEE có thể mang lại tập hợp các lớp con {SALARIED_EMPLOYEE, HOURLY_EMPLOYEE}; sự chuyên môn hóa này phân biệt giữa các nhân viên dựa trên phương thức trả lương.
Hình 4.1 cho thấy cách chúng ta biểu diễn một chuyên môn theo sơ đồ trong biểu đồ EER. Các lớp con xác định một chuyên ngành được gắn bằng các dòng vào một vòng tròn biểu thị chuyên môn, được nối lần lượt với lớp cha. Biểu tượng tập hợp con trên mỗi dòng nối một lớp con với vòng tròn cho biết hướng của mối quan hệ lớp cha / lớp con. Các thuộc tính chỉ áp dụng cho các thực thể của một lớp con cụ thể — chẳng hạn như TypingSpeed of SECRETARY — được gắn vào góc trực tiếp đại diện cho lớp con đó. Chúng được gọi là các thuộc tính cụ thể (hoặc cục bộ) của lớp con. Tương tự, một lớp con có thể tham gia vào các kiểu quan hệ cụ thể, chẳng hạn như lớp con HOURLY_EMPLOYEE tham gia vào mối quan hệ BELONGS_TO trong Hình 4.1. Chúng ta sẽ giải thích ký hiệu d trong các vòng tròn trong Hình 4.1 và ký hiệu khác trong sơ đồ EER bổ sung ngay sau đây.
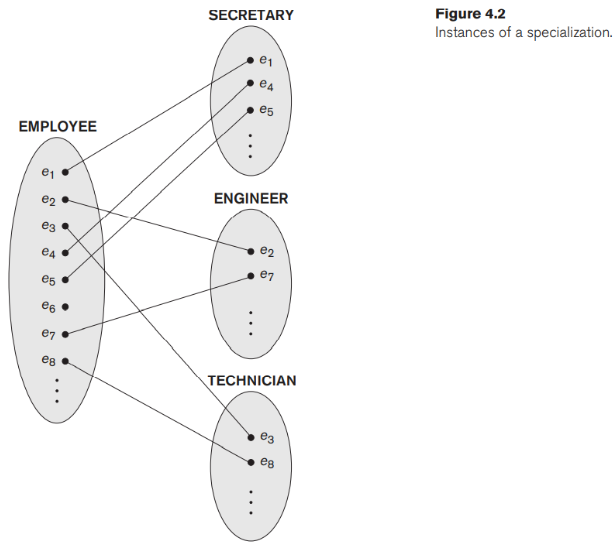
Hình 4.2 cho thấy một vài cá thể thực thể thuộc các lớp con của chuyên môn hóa {SECRETARY, ENGINEER, TECHNICIAN}. Một lần nữa, hãy lưu ý rằng một thực thể thuộc lớp con đại diện cho cùng một thực thể trong thế giới thực với thực thể được kết nối với nó trong lớp cha EMPLOYEE, mặc dù cùng một thực thể được hiển thị hai lần; ví dụ, e1 được hiển thị trong cả EMPLOYEE và SECRETARY trong Hình 4.2. Như hình cho thấy, một mối quan hệ lớp cha / lớp con chẳng hạn như EMPLOYEE / SECRETARY phần nào giống với mối quan hệ 1: 1 ở cấp độ cá thể (xem Hình 3.12). Điểm khác biệt chính là trong mối quan hệ 1: 1, hai thực thể riêng biệt có liên quan với nhau, trong khi trong mối quan hệ siêu lớp / lớp con, thực thể trong lớp con là thực thể trong thế giới thực giống như thực thể trong lớp cha nhưng đang đóng một vai trò chuyên biệt —Ví dụ, EMPLOYEE chuyên trách vai trò THƯ KÝ hoặc NHÂN VIÊN chuyên trách vai trò ENGINEER.
Có hai lý do chính để bao gồm các mối quan hệ lớp / lớp con và các chuyên môn hóa. Đầu tiên là các thuộc tính nhất định có thể áp dụng cho một số nhưng không phải tất cả các thực thể của kiểu thực thể lớp cha. Một lớp con được định nghĩa để nhóm các thực thể mà các thuộc tính này áp dụng. Các thành viên của lớp con vẫn có thể chia sẻ phần lớn các thuộc tính của chúng với các thành viên khác của lớp cha. Ví dụ, trong Hình 4.1, lớp con SECRETARY có thuộc tính cụ thể Typing_speed, trong khi lớp con ENGINEER có thuộc tính cụ thể Eng_type, nhưng SECRETARY và ENGINEER chia sẻ các thuộc tính kế thừa khác của chúng từ kiểu thực thể EMPLOYEE
Lý do thứ hai cho việc sử dụng các lớp con là một số kiểu quan hệ có thể chỉ được kết hợp bởi các thực thể là thành viên của lớp con. Ví dụ: nếu chỉ HOURLY_EMPLOYEES có thể thuộc về một tổ chức công đoàn, chúng tôi có thể biểu thị thực tế đó bằng cách tạo lớp con HOURLY_EMPLOYEE của EMPLOYEE và liên kết lớp con với kiểu thực thể TRADE_UNION thông qua kiểu quan hệ BELONGS_TO, như được đánh dấu trong Hình 4.1.
2.2 Tổng quát hóa
Chúng ta có thể nghĩ về một quá trình tổng quát hóa ngược lại, trong đó chúng ta loại bỏ sự khác biệt giữa một số loại thực thể, xác định các đặc điểm chung của chúng và tổng quát hóa chúng thành một lớp cha duy nhất trong đó các loại thực thể ban đầu là lớp con đặc biệt. Ví dụ, hãy xem xét các loại thực thể CAR và TRUCK được thể hiện trong Hình 4.3 (a). Bởi vì chúng có một số thuộc tính chung, chúng có thể được khái quát thành loại thực thể VEHICLE, như trong Hình 4.3 (b). Cả CAR và TRUCK hiện nay đều là các lớp con của lớp tổng quát VEHICLE. Chúng ta sử dụng thuật ngữ Tổng quát hóa để đề cập đến khả năng xác định một loại thực thể tổng quát hóa từ các loại thực thể nhất định.
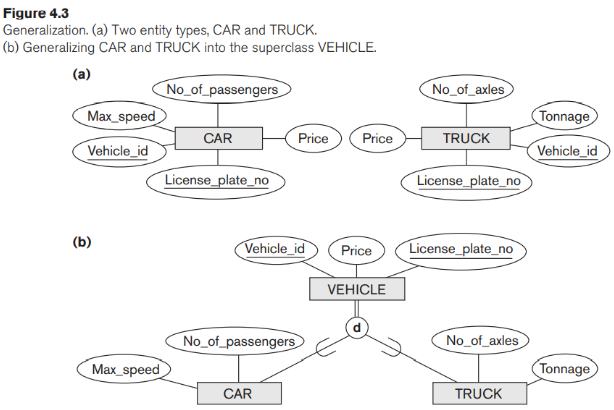
Lưu ý rằng quá trình tổng quát hóa có thể được xem xét về mặt chức năng là nghịch đảo của quá trình chuyên môn hóa; chúng ta có thể xem {CAR, TRUCK} là một lớp con chuyên biệt hóa của VEHICLE chứ không phải xem VEHICLE là một khái quát của CAR và TRUCK. Một ký hiệu sơ đồ để phân biệt giữa khái quát hóa và chuyên môn hóa được sử dụng trong một số phương pháp thiết kế. Một mũi tên trỏ đến siêu lớp tổng quát hóa đại diện cho một quá trình tổng quát hóa, trong khi các mũi tên chỉ đến các lớp con được ized đặc biệt đại diện cho một quá trình chuyên môn hóa. Chúng tôi sẽ không sử dụng ký hiệu này vì quyết định về quy trình nào được tuân theo trong một tình huống cụ thể thường mang tính chủ quan
Cho đến phần này chúng ta đã được giới thiệu các khái niệm về lớp con và các mối quan hệ liên quan đến lớp cha / lớp con, cũng như các quá trình chuyên biệt hóa và tổng quát hóa. Nói chung, một lớp cha hoặc lớp con đại diện cho một tập hợp các thực thể cùng kiểu và do đó cũng mô tả một kiểu thực thể; đó là lý do tại sao các lớp cha và lớp con đều được hiển thị dưới dạng hình chữ nhật trong sơ đồ EER, giống như các kiểu thực thể
3. Những ràng buộc và đặc điểm của cấu trúc phân cấp chuyên môn hóa và tổng quát hóa
Đầu tiên, chúng ta thảo luận về các ràng buộc áp dụng cho một chuyên môn hóa hoặc một tổng quát hóa duy nhất. Tóm lại, trong bài viết này chỉ đề cập đến chuyên môn hóa mặc dù nó áp dụng cho cả chuyên môn hóa và khái quát hóa. Sau đó, chúng tôi thảo luận về sự khác biệt giữa mạng lưới chuyên biệt hóa / tổng quát hóa (đa kế thừa) và phân cấp (kế thừa đơn), và chúng tôi giải thích sự khác biệt giữa quy trình chuyên biệt hóa và tổng quát hóa trong quá trình thiết kế lược đồ cơ sở dữ liệu ở mức khái niệm
3.1 Những ràng buộc về chuyên môn hóa và tổng quát hóa
Nói chung, chúng ta có thể có một số chuyên ngành được xác định trên cùng một kiểu thực thể (hoặc lớp cha), như trong Hình 4.1. Trong trường hợp như vậy, các thực thể có thể thuộc về các lớp con trong mỗi chuyên ngành. Một chuyên môn cũng có thể chỉ bao gồm một lớp con, chẳng hạn như chuyên môn {MANAGER} trong Hình 4.1; trong trường hợp như vậy, chúng tôi không sử dụng ký hiệu vòng tròn
Trong một số chuyên ngành, chúng ta có thể xác định chính xác các thực thể sẽ trở thành thành viên của mỗi lớp con bằng cách đặt một điều kiện về giá trị của một số thuộc tính của lớp cha. Các lớp con như vậy được gọi là lớp con do vị từ xác định (hoặc điều kiện xác định). Ví dụ, nếu kiểu thực thể EMPLOYEE có thuộc tính Job_type, như trong Hình 4.4, chúng ta có thể chỉ định điều kiện thành viên trong lớp con SECRETARY bằng điều kiện (Job_type = 'Thư ký'), mà chúng ta gọi là vị từ xác định của lớp con . Điều kiện này là một ràng buộc chỉ định rằng chính xác những thực thể của loại thực thể EMPLOYEE có giá trị thuộc tính cho Job_type là ‘Thư ký’ thuộc về lớp con. Chúng tôi hiển thị một lớp con xác định vị từ bằng cách viết điều kiện bên cạnh dòng kết nối lớp con với vòng tròn chuyên môn hóa.
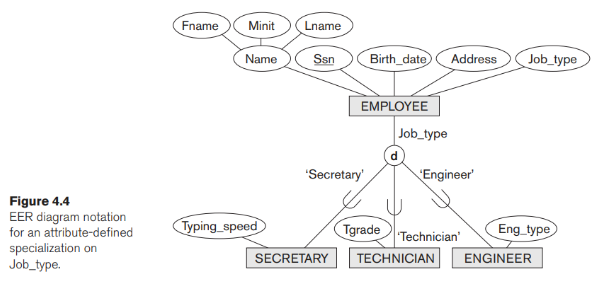
Nếu tất cả các lớp con trong một chuyên môn (lớp cha) có điều kiện thành viên của chúng trên cùng một thuộc tính của lớp cha, thì bản thân chuyên môn đó được gọi là chuyên môn do thuộc tính xác định, và thuộc tính này được gọi là thuộc tính xác định của chuyên biệt hóa. Trong trường hợp này, tất cả các thực thể có cùng giá trị cho thuộc tính thuộc cùng một lớp con. Chúng tôi hiển thị một chuyên môn hóa xác định thuộc tính bằng cách đặt tên thuộc tính xác định bên cạnh vòng tròn đến lớp cha, như thể hiện trong Hình 4.4.
Khi chúng ta không có điều kiện xác định tư cách thành viên trong một lớp con, lớp con được gọi là do người dùng xác định. Tư cách thành viên trong một lớp con như vậy được xác định bởi người dùng cơ sở dữ liệu khi họ áp dụng thao tác để thêm một thực thể vào lớp con; do đó, tư cách thành viên được chỉ định riêng cho từng thực thể bởi người dùng, không theo bất kỳ điều kiện nào có thể được đánh giá tự động
Hai ràng buộc khác có thể áp dụng cho một lớp chuyên môn hóa. Đầu tiên là ràng buộc rời rạc, quy định rằng các lớp con của lớp cha phải là các tập rời rạc. Điều này có nghĩa là một thực thể có thể là thành viên của nhiều nhất một trong các lớp con. Một lớp cha được xác định bởi thuộc tính ngụ ý ràng buộc về tính rời rạc (nếu thuộc tính được sử dụng để xác định vị từ thuộc tính là một giá trị duy nhất). Hình 4.4 minh họa trường hợp này, trong đó chữ d trong vòng tròn có nghĩa là rời rạc. Ký hiệu d cũng áp dụng cho các lớp con do người dùng định nghĩa của một chuyên ngành phải rời rạc, như được minh họa bởi chuyên môn {HOURLY_EMPLOYEE, SALARIED_EMPLOYEE} trong Hình 4.1. Nếu các lớp con không bị ràng buộc phải rời rạc, các tập thực thể của chúng có thể chồng chéo lên nhau; nghĩa là, cùng một thực thể (trong thế giới thực) có thể là thành viên của nhiều hơn một lớp con của chuyên ngành. Trường hợp này, là mặc định, được hiển thị bằng cách đặt một chữ o trong vòng tròn, như trong Hình 4.5
Ràng buộc thứ hai về chuyên môn hóa được gọi là ràng buộc tính đầy đủ (hay tính toàn bộ), có thể là toàn bộ hoặc từng phần. Một ràng buộc chuyên môn hóa tổng thể chỉ định rằng mọi thực thể trong lớp cha phải là thành viên của ít nhất một lớp con nào đó. Ví dụ: nếu mỗi EMPLOYEE phải là HOURLY_EMPLOYEE hoặc SALARIED_EMPLOYEE, thì chuyên môn {HOURLY_EMPLOYEE, SALARIED_EMPLOYEE} trong Hình 4.1 là tổng chuyên môn của NHÂN VIÊN. Điều này được thể hiện trong biểu đồ EER bằng cách sử dụng một đường đôi để kết nối lớp cha với vòng tròn. Một dòng duy nhất được sử dụng để hiển thị một chuyên môn hóa từng phần, cho phép một thực thể không thuộc bất kỳ lớp con nào. Ví dụ: nếu một số thực thể EMPLOYEE không thuộc bất kỳ lớp con nào {SECRETARY, ENGINEER, TECHNICIAN} trong Hình 4.1 và 4.4, thì chuyên môn đó là một phần.
Lưu ý rằng các ràng buộc rời rạc và đầy đủ là độc lập. Do đó, chúng ta có bốn ràng buộc có thể có sau đây đối với một lớp chuyên môn hóa:
-
Rời rạc, tổng số
-
Rời rạc, một phần
-
Chồng lắp, tổng số
-
Chồng lắp, một phần
Tất nhiên, ràng buộc chính xác được xác định từ ý nghĩa của thế giới thực áp dụng cho từng lớp chuyên môn hóa. Nói chung, một lớp cha đã được xác định thông qua quá trình tổng quát hóa thường là tổng số, bởi vì lớp cha được bắt nguồn từ các lớp con và do đó chỉ chứa các thực thể nằm trong các lớp con.
Một số quy tắc về việc thêm và xóa nhất định áp dụng cho lớp chuyên môn hóa (và tổng quát hóa) do các ràng buộc được chỉ định trước đó. Một số quy tắc này như sau:
-
Xóa một thực thể khỏi lớp cha nghĩa là nó sẽ tự động bị xóa khỏi tất cả các lớp con mà nó thuộc về
-
Chèn một thực thể vào một lớp cha ngụ ý rằng thực thể được chèn bắt buộc trong tất cả các lớp con do vị từ xác định (hoặc thuộc tính xác định) mà đối tượng đó thỏa mãn vị từ xác định.
-
Việc chèn một thực thể vào lớp cha của một chuyên môn hóa ngụ ý rằng thực thể đó được bắt buộc phải chèn vào ít nhất một trong các lớp con của chuyên môn đó.
Ở đây chúng ta được khuyến khích tạo một danh sách đầy đủ các quy tắc về chèn và xóa cho các lớp được chuyên môn hóa khác nhau
3.2 Cấu trúc phân cấp
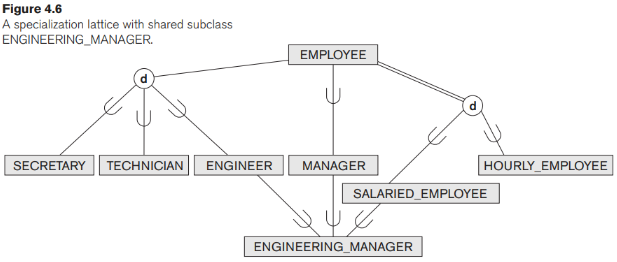
Bản thân một lớp con có thể có thêm các lớp con khác được chỉ định trên đó, tạo thành một hệ thống phân cấp hoặc một mạng lưới các lớp chuyên môn hóa. Ví dụ, trong Hình 4.6 ENGINEER là một lớp con của EMPLOYEE và cũng là một lớp cha của ENGINEERING_MANAGER; điều này thể hiện ràng buộc trong thế giới thực mà mọi giám đốc kỹ thuật đều phải là kỹ sư. Hệ thống phân cấp chuyên môn hóa có ràng buộc rằng mọi lớp con tham gia như một lớp con chỉ trong một mối quan hệ lớp cha / lớp con; nghĩa là mỗi lớp con chỉ có một lớp cha, điều này dẫn đến cấu trúc cây hoặc hệ thống phân cấp nghiêm ngặt. Ngược lại, đối với mạng chuyên môn hóa, một lớp con có thể là một lớp con trong nhiều hơn một mối quan hệ lớp cha/ lớp con. Do đó, Hình 4.6 là một mạng phân cấp.
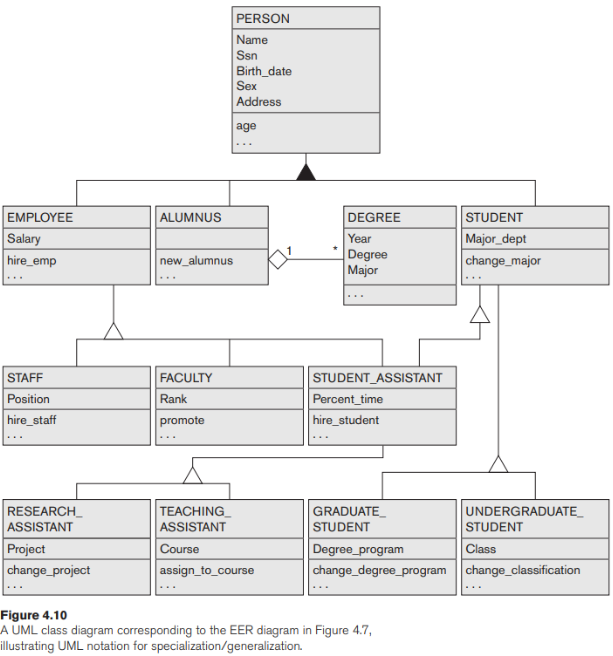
Hình 4.7 cho thấy một mạng lưới chuyên môn hóa khác có nhiều hơn một cấp độ. Đây có thể là một phần của lược đồ khái niệm cho cơ sở dữ liệu UNIVERSITY. Lưu ý rằng sự sắp xếp này sẽ là một hệ thống phân cấp ngoại trừ lớp con STUDENT_ASSISTANT, là một lớp con trong hai mối quan hệ lớp cha / lớp con riêng biệt
Các yêu cầu đối với một phần của cơ sở dữ liệu UNIVERSITY được thể hiện trong Hình 4.7 như sau:
-
Cơ sở dữ liệu theo dõi ba loại người: nhân viên, cựu sinh viên và sinh viên. Một người có thể thuộc một, hai hoặc cả ba loại này. Mỗi người có tên, SSN, giới tính, địa chỉ và ngày sinh.
-
Mọi nhân viên đều có lương, và có ba loại nhân viên: nhân viên phụ trách, nhân viên và trợ lý sinh viên. Mỗi nhân viên thuộc đúng một trong những loại này. Đối với mỗi cựu sinh viên, một hồ sơ về bằng cấp hoặc các bằng cấp mà họ đã đạt được tại trường đại học được lưu giữ, bao gồm tên của bằng cấp, năm được cấp và khoa chính. Mỗi sinh viên có một bộ phận chính.
-
Mỗi khoa có một cấp bậc, ngược lại mỗi cán bộ có một chức vụ. Trợ lý Stu dent được phân loại thêm là trợ lý nghiên cứu hoặc trợ giảng và phần trăm thời gian họ làm việc được ghi lại trong cơ sở dữ liệu. Trợ lý nghiên cứu có dự án nghiên cứu của họ được lưu trữ, trong khi trợ lý giảng dạy có khóa học hiện tại mà họ làm việc
-
Sinh viên được phân loại thêm là sau đại học hoặc đại học, với chương trình cấp bằng thuộc tính cụ thể (M.S., Ph.D., M.B.A., v.v.) cho sinh viên sau đại học và lớp (sinh viên năm nhất, năm hai, v.v.) cho sinh viên đại học
Trong Hình 4.7, tất cả các thực thể người được đại diện trong cơ sở dữ liệu là thành viên của kiểu thực thể PERSON, được chuyên biệt hóa thành các lớp con {EMPLOYEE, ALUMNUS, STUDENT}. Chuyên ngành này bị chồng chéo; ví dụ, một cựu nhân viên cũng có thể là một nhân viên và một sinh viên đang theo đuổi một bằng cấp cao. Lớp con STUDENT là lớp cha cho chuyên môn {GRADUATE_STUDENT, UNDERGRADUATE_STUDENT}, trong khi EMPLOYEE là lớp cha cho chuyên môn {STUDENT_ASSISTANT, FACULTY, STAFF}. Lưu ý rằng STUDENT_ASSISTANT cũng là một lớp con của STUDENT. Cuối cùng, STUDENT_ASSISTANT là lớp cha cho chuyên môn thành {RESEARCH_ASSISTANT, TEACHING_ASSISTANT}.
Trong một mạng hoặc hệ thống phân cấp chuyên môn hóa như vậy, một lớp con kế thừa các thuộc tính không chỉ của lớp cha trực tiếp của nó mà còn của tất cả các lớp cha tiền nhiệm của nó đến tận gốc của hệ thống phân cấp. Ví dụ: một thực thể trong GRADUATE_STUDENT kế thừa tất cả các thuộc tính của thực thể đó với tư cách là STUDENT và PERSON. Lưu ý rằng một thực thể có thể tồn tại trong một số nút lá của hệ thống phân cấp, trong đó nút lá là một lớp không có lớp con của riêng nó. Ví dụ: thành viên của GRADUATE_STUDENT cũng có thể là thành viên của RESEARCH_ASSISTANT.
Một lớp con có nhiều hơn một lớp cha được gọi là lớp con được sử dụng chung, chẳng hạn như ENGINEERING_MANAGER trong Hình 4.6. Điều này dẫn đến khái niệm được gọi là đa kế thừa, trong đó lớp con được chia sẻ ENGINEERING_MANAGER kế thừa trực tiếp các thuộc tính và mối quan hệ từ nhiều lớp cha. Lưu ý rằng sự tồn tại của ít nhất một lớp con được chia sẻ dẫn đến một mạng tinh thể (và do đó dẫn đến đa kế thừa); Nếu không có con lớp được chia sẻ nào tồn tại, chúng ta sẽ có một hệ thống phân cấp hơn là một mạng và chỉ có một kế thừa duy nhất tồn tại. Một quy tắc quan trọng liên quan đến đa kế thừa có thể được minh họa bằng ví dụ về lớp con chia sẻ STUDENT_ASSISTANT trong Hình 4.7, lớp này kế thừa các thuộc tính từ cả EMPLOYEE và STUDENT. Ở đây, cả NHÂN VIÊN và SINH VIÊN đều kế thừa các thuộc tính giống nhau từ PERSON. Quy tắc nêu rõ nếu một thuộc tính (hoặc hệ thống tàu) có nguồn gốc trong cùng một lớp cha (PERSON) được kế thừa nhiều lần thông qua các đường dẫn khác nhau (EMPLOYEE and STUDENT) trong mạng, thì nó chỉ nên được đưa vào một lớp con được chia sẻ (STUDENT_ASSISTANT). Do đó, các thuộc tính của PERSON chỉ được kế thừa một lần trong lớp con STUDENT_ASSISTANT in Hình 4.7
Điều quan trọng cần lưu ý ở đây là một số mô hình và ngôn ngữ được giới hạn ở thừa kế đơn và không cho phép đa kế thừa (các lớp con được chia sẻ). Cũng cần lưu ý rằng một số mô hình không cho phép một thực thể có nhiều kiểu và do đó một thực thể chỉ có thể là thành viên của một lớp lá.8 Trong một mô hình như vậy, cần tạo thêm các lớp con làm nút lá để bao gồm tất cả các kết hợp có thể có của các lớp có thể có một số thực thể thuộc tất cả các lớp này đồng thời. Ví dụ: trong chuyên môn hóa chồng chéo PERSON thành {EMPLOYEE, ALUMNUS, STUDENT} (hoặc viết tắt là {E, A, S}), cần phải tạo bảy lớp con của PERSON để bao gồm tất cả các loại thực thể có thể có: E, A, S, E_A, E_S, A_S và E_A_S. Rõ ràng, điều này có thể dẫn đến điều gì đó phức tạp hơn
Mặc dù chúng tôi đã sử dụng chuyên biệt hóa để minh họa cho cuộc thảo luận của mình, các khái niệm tương tự cũng áp dụng tương tự đối với khái quát hóa, như chúng tôi đã đề cập ở đầu phần này. Do đó, chúng ta cũng có thể nói về cấu trúc phân cấp tổng quát.
3.3 Sử dụng chuyên môn hóa và tổng quát hóa trong việc tinh chỉnh các lược đồ khái niệm
Bây giờ chúng tôi giải thích thêm về sự khác biệt giữa các quá trình chuyên biệt hóa và tổng quát hóa và cách chúng được sử dụng để tinh chỉnh các lược đồ khái niệm trong quá trình thiết kế cơ sở dữ liệu khái niệm. Trong quá trình chuyên môn hóa, các nhà thiết kế cơ sở dữ liệu thường bắt đầu với một kiểu thực thể và sau đó xác định các lớp con của kiểu thực thể bằng cách phân biệt các lần liên tiếp; nghĩa là, chúng lặp đi lặp lại xác định các nhóm cụ thể hơn của loại thực thể. Ví dụ, khi thiết kế mạng chuyên môn hóa trong Hình 4.7, trước tiên chúng ta có thể chỉ định kiểu thực thể PERSON cho cơ sở dữ liệu trường đại học. Sau đó, chúng ta phát hiện ra rằng ba loại người sẽ được đại diện trong cơ sở dữ liệu: trường đại học tuyển dụng nhân viên, cựu sinh viên và sinh viên và chúng ta tạo ra các thực thể chuyên biệt hóa {EMPLOYEE, ALUMNUS, STUDENT}. Ràng buộc chồng chéo được chọn vì một người có thể thuộc nhiều hơn một trong các lớp con. Chúng tôi chuyên sâu hơn về EMPLOYEE vào {STAFF, FACULTY, STUDENT_ASSISTANT} và chuyên môn hóa STUDENT vào {GRADUATE_STUDENT, UNDERGRADUATE_STUDENT}. Cuối cùng, chúng tôi chuyển STUDENT_ASSISTANT thành {RESEARCH_ASSISTANT, TEACHING_ASSISTANT}. Quá trình này được gọi là sàng lọc khái niệm từ trên xuống. Cho đến nay, chúng tôi có một hệ thống cao hơn; thì chúng tôi nhận ra rằng STUDENT_ASSISTANT là một lớp con được chia sẻ, vì nó cũng là một lớp con của STUDENT, dẫn đến mạng phân cấp.
Có thể tiếp cận việc xây dựng một hệ thống phân cấp từ hướng khác. Trong trường hợp như vậy, quá trình liên quan đến tổng quát hóa hơn là chuyên biệt hóa là một tổng hợp khái niệm từ dưới lên. Ví dụ: người thiết kế cơ sở dữ liệu trước tiên có thể khám phá ra các kiểu thực thể như STAFF, FACULTY, ALUMNUS, GRADUATE_STUDENT, UNDERGRADUATE_STUDENT, RESEARCH_ASSISTANT, TEACHING_ASSISTANT, v.v.; sau đó họ tổng quát hóa {GRADUATE_STUDENT, UNDERGRADUATE_STUDENT} thành STUDENT; sau đó {RESEARCH_ASSISTANT, DẠY_ASSISTANT} thành STUDENT_ASSISTANT; sau đó {STAFF, FACULTY, STUDENT_ASSISTANT} thành EMPLOYEE; và cuối cùng {EMPLOYEE, ALUMNUS, STUDENT} thành PERSON.
Kết quả thiết kế cuối cùng của hệ thống phân cấp từ một trong hai quy trình có thể giống hệt nhau; sự khác biệt duy nhất liên quan đến cách thức hoặc thứ tự mà các lớp cha và lớp con của lược đồ được tạo ra trong quá trình thiết kế. Trong thực tế, có khả năng là sự kết hợp của hai quy trình được sử dụng. Lưu ý rằng khái niệm biểu diễn dữ liệu và tri thức bằng cách sử dụng các chies và mạng phân cấp lớp cha / lớp con khá phổ biến trong các hệ thống dựa trên tri thức và hệ thống chuyên gia, kết hợp công nghệ cơ sở dữ liệu với các kỹ thuật trí tuệ nhân tạo. Ví dụ, các lược đồ biểu diễn tri thức dựa trên khung gần giống với cấu trúc phân cấp lớp. Chuyên biệt hóa cũng phổ biến trong các phương pháp luận thiết kế kỹ thuật phần mềm dựa trên mô hình hướng đối tượng.
4. Mô hình hóa các loại UNION sử dụng danh mục
Đôi khi cần phải đại diện cho một tập hợp các thực thể từ các loại thực thể khác nhau. Trong trường hợp này, một lớp con sẽ đại diện cho một tập hợp các thực thể là một tập con của UNION các thực thể từ các loại thực thể riêng biệt; chúng tôi gọi một lớp con như vậy là một kiểu liên hợp hoặc một danh mục
Ví dụ: giả sử rằng chúng ta có ba loại thực thể: PERSON, BANK và COMPANY. Trong cơ sở dữ liệu về đăng ký xe cơ giới, chủ sở hữu xe có thể là một người, một ngân hàng (đang cầm giữ xe) hoặc một công ty. Chúng ta cần tạo một lớp (tập hợp các thực thể) bao gồm các thực thể của cả ba loại để đóng vai trò là chủ phương tiện. Danh mục chủ sở hữu là một lớp con của UNION trong ba bộ thực thể PERSON, BANK và COMPANY có thể được tạo cho mục đích này. Chúng tôi hiển thị các danh mục trong một biểu đồ EER như trong Hình 4.8. Các lớp cha COMPANY, BANK và PERSON được kết nối với vòng tròn bằng ký hiệu ∪, viết tắt của hoạt động liên hợp đã đặt. Một vòng cung với biểu tượng tập hợp con nối vòng tròn với danh mục OWNER (lớp con). Trong Hình 4.8, chúng ta có hai loại: CHỦ SỞ HỮU, là một lớp con (tập con) của liên hiệp PERSON, BANK và COMPANY; và REGISTERED_VEHICLE, là một lớp con (tập con) của sự kết hợp giữa CAR và TRUCK.
Một danh mục có hai hoặc nhiều lớp cha có thể đại diện cho tập hợp các thực thể từ các kiểu thực thể riêng biệt, trong khi các mối quan hệ lớp cha / lớp con khác luôn có một lớp cha duy nhất. Để hiểu rõ hơn về sự khác biệt, chúng ta có thể so sánh một danh mục, chẳng hạn như OWNER trong Hình 4.8, với lớp con chia sẻ ENGINEERING_MANAGER trong Hình 4.6. Cái sau là một lớp con của mỗi trong ba lớp cha ENGINEER, MANAGER và SALARIED_EMPLOYEE, vì vậy một thực thể là thành viên của ENGINEERING_MANAGER phải tồn tại trong cả ba tập hợp. Điều này thể hiện ràng buộc rằng người quản lý kỹ thuật phải là ENGINEER, MANAGER và SALARIED_EMPLOYEE; nghĩa là, tập thực thể ENGINEERING_MANAGER là một tập hợp con của phần giao nhau của ba tập thực thể. Mặt khác, một thể loại là một tập hợp con của sự kết hợp của các siêu lớp của nó. Do đó, một thực thể là thành viên của OWNER phải chỉ tồn tại ở một trong các lớp cha. Điều này thể hiện ràng buộc rằng OWNERcó thể là PERSON, BANK và COMPANY; và REGISTERED_VEHICLE trong Hình 4.8
Kế thừa thuộc tính hoạt động có chọn lọc hơn. Ví dụ, trong Hình 4.8, mỗi thực thể OWNER kế thừa các thuộc tính của PERSON, BANK và COMPANY, tùy thuộc vào lớp cha mà thực thể đó thuộc về. Mặt khác, một lớp con được chia sẻ như ENGINEERING_MANAGER (Hình 4.6) kế thừa tất cả các thuộc tính của các lớp cha của nó SALARIED_EMPLOYEE, ENGINEER và MANAGER
Thật thú vị khi lưu ý sự khác biệt giữa danh mục REGISTERED_VEHICLE (Hình 4.8) và siêu lớp tổng quát VEHICLE (Hình 4.3 (b)). Trong Hình 4.3 (b), mọi ô tô và mọi xe tải đều là VEHICLE; nhưng trong Hình 4.8, danh mục REGISTERED_VEHICLE bao gồm một số ô tô và một số xe tải nhưng không nhất thiết là tất cả chúng (ví dụ, một số ô tô hoặc xe tải có thể không được đăng ký). Nói chung, việc chuyên môn hóa hoặc khái quát hóa như trong Hình 4.3 (b), nếu là một phần, sẽ không ngăn cản VEHICLE chứa các loại thực thể khác, chẳng hạn như xe máy. Tuy nhiên, một danh mục như REGISTERED_VEHICLE trong Hình 4.8 ngụ ý rằng chỉ ô tô và xe tải, chứ không phải các loại thực thể khác, mới có thể là thành viên của REGISTERED_VEHICLE.
Một danh mục có thể là toàn bộ hoặc một phần. Một danh mục tổng thể chứa sự kết hợp của tất cả các thực thể trong các lớp cha của nó, trong khi một danh mục riêng phần có thể chứa một tập hợp con của sự kết hợp. Tổng danh mục được biểu thị theo sơ đồ bằng một đường đôi nối danh mục và vòng tròn, trong khi danh mục một phần được biểu thị bằng một đường đơn.
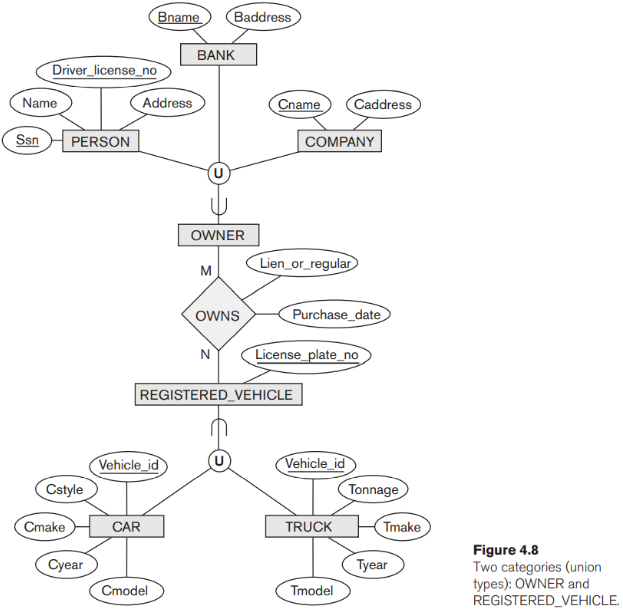
Các lớp cha của một danh mục có thể có các thuộc tính khóa khác nhau, như được trình bày bởi danh mục OWNER trong Hình 4.8, hoặc chúng có thể có cùng một thuộc tính khóa, như thể hiện trong danh mục REGISTERED_VEHICLE. Lưu ý rằng nếu một danh mục là tổng thể (không phải một phần), nó có thể được biểu diễn theo cách khác dưới dạng chuyên môn hóa tổng thể (tổng quát hóa). Trong trường hợp này, việc lựa chọn biểu diễn nào để sử dụng là ý kiến phụ. Nếu hai lớp đại diện cho cùng một loại thực thể và chia sẻ nhiều thuộc tính, bao gồm các thuộc tính khóa giống nhau, thì việc chuyên môn hóa / tổng quát hóa được lên trước; nếu không, phân loại hoặc kết hợp là thích hợp hơn.
Điều quan trọng cần lưu ý là một số phương pháp lập mô hình không có các kiểu liên kết. Trong các mô hình này, một loại liên kết phải được biểu diễn theo cách xoay vòng. Chúng ta sẽ tìm hiểu phần này sau
5. Ví dụ về lược đồ EER UNIVERSITY, Lựa chọn thiết kế và Định nghĩa chính thức
Trong phần này, trước tiên chúng tôi đưa ra một ví dụ về lược đồ cơ sở dữ liệu trong mô hình EER để minh họa việc sử dụng các khái niệm khác nhau được thảo luận ở đây và trong Chương 3. Sau đó, chúng tôi thảo luận về các lựa chọn thiết kế cho các lược đồ khái niệm và cuối cùng chúng tôi tóm tắt các khái niệm mô hình EER và định nghĩa chúng một cách chính thức theo cùng một cách mà chúng tôi đã biết trong các khái niệm về mô hình ER cơ bản trong Chương 3
5.1 Một ví dụ về cơ sở dữ liệu UNIVERSITY khác
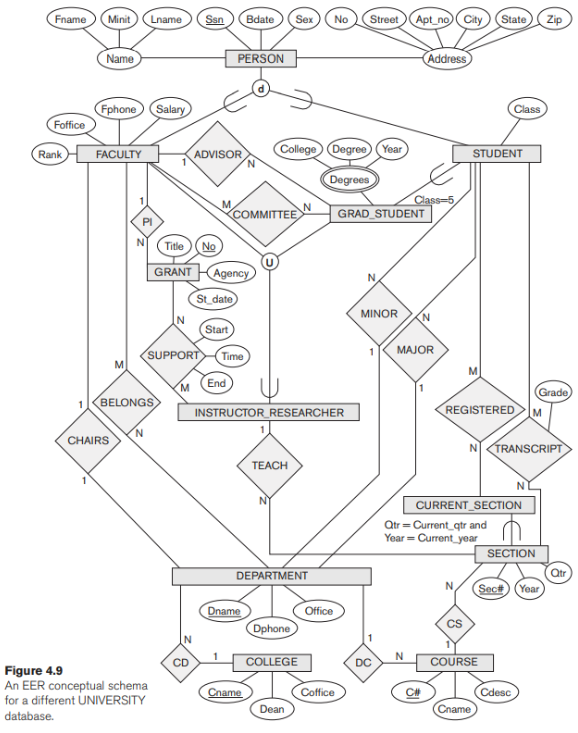
Hãy xem xét một cơ sở dữ liệu ĐẠI HỌC có các yêu cầu khác với cơ sở dữ liệu ĐẠI HỌC được trình bày trong Phần 3.10. Cơ sở dữ liệu này theo dõi sinh viên và chuyên ngành, bảng điểm và đăng ký của họ cũng như các khóa học của trường đại học. Cơ sở dữ liệu cũng theo dõi các dự án nghiên cứu được tài trợ của giảng viên và sinh viên sau đại học. Lược đồ này được thể hiện trong Hình 4.9. Một cuộc thảo luận về các yêu cầu dẫn đến giản đồ này như sau:
Đối với mỗi người, cơ sở dữ liệu lưu trữ thông tin về Tên [Name], số An sinh xã hội [Ssn], địa chỉ [Address], giới tính [Sex] và ngày sinh [Bdate]. Hai lớp con của kiểu thực thể PERSON được xác định: FACULTY và STUDENT. Các thuộc tính cụ thể của FACULTY là cấp bậc [Rank] (trợ lý, cộng sự, phụ tá, nghiên cứu, thăm, v.v.), văn phòng [Foffice], điện thoại văn phòng [Fphone] và lương [Salary]. Tất cả các thành viên của khoa đều có liên quan đến (các) khoa mà họ liên kết [BELONGS] (một thành viên của khoa có thể được liên kết với nhiều phòng ban, vì vậy mối quan hệ là M: N). Một thuộc tính cụ thể của STUDENT là [Class] (sinh viên năm nhất = 1, sopho more = 2,…, MS student = 5, PhD student = 6). Mỗi STUDENT cũng có liên quan đến các chuyên ngành và khoa của mình (nếu biết) [MAJOR] và [MINOR], đến các phần khóa học mà họ hiện đang theo học [REGISTERED] và các khóa học đã hoàn thành [TRANSCRIPT]. Mỗi phiên bản TRANSCRIPT bao gồm điểm mà học sinh nhận được [Grade] trong một phần của khóa học.
GRAD_STUDENT là một lớp con của STUDENT, với vị từ xác định (Lớp = 5 HOẶC Lớp = 6). Đối với mỗi sinh viên tốt nghiệp, chúng tôi giữ một danh sách các bằng cấp trước đó trong thuộc tính đa trị phức hợp [Degrees]. Chúng tôi cũng liên hệ sinh viên tốt nghiệp với cố vấn của khoa [ADVISOR] và với hội động luận văn [COMMITTEE], nếu có
Các thông tin lưu trữ liên quan đến khóa gồm có các thuộc tính [Dname], điện thoại [Dphone] và số văn phòng [Office] và có liên quan đến thành viên của khoa là chủ tịch của khoa [CHAIRS] và trường đại học mà nó trực thuộc [CD]. Mỗi trường đại học có thuộc tính như tên trường đại học [Cname], số văn phòng [Coffice] và tên của hiệu trưởng [Dean]
Một khóa học có các thuộc tính mã số khóa học [C#], tên khóa học [Cname] và mô tả khóa học [Cdesc]. Một số học phần của mỗi khóa học được cung cấp, với mỗi học phần có cần lưu số học phần [Sec#] và năm và quý mà phần đó được cung cấp ([Year] và [Qtr]). Số học phần xác định duy nhất mỗi phần. Các phần đang được cung cấp trong quý hiện tại nằm trong lớp con CURRENT_SECTION của SECTION, với vị từ xác định Qtr = Current_qtr và Year = Current_year. Mỗi phần có liên quan đến giảng viên đã dạy hoặc đang giảng dạy phần đó ([TEACH]), nếu giảng viên đó có trong cơ sở dữ liệu.
Danh mục INTHEROR_RESEARCHER là một tập hợp con của FACULTY và GRAD_STUDENT và bao gồm tất cả các giảng viên, cũng như các sinh viên sau đại học được hỗ trợ bởi quá trình giảng dạy hoặc nghiên cứu. Cuối cùng, loại thực thể GRANT theo dõi các khoản tài trợ nghiên cứu và các hợp đồng được trao cho trường đại học. Mỗi khoản trợ cấp có các thuộc tính như tiêu đề [Title], số tài trợ [No], cơ quan trao giải [Agency] và ngày bắt đầu [St_date]. Một khoản trợ cấp liên quan đến một nhà đầu tư [PI] và cho tất cả các nhà nghiên cứu mà nó hỗ trợ [Start]. Mỗi trường hợp hỗ trợ có các thuộc tính như ngày bắt đầu hỗ trợ [Bắt đầu], ngày kết thúc hỗ trợ (nếu biết) [Kết thúc] và phần trăm thời gian dành cho dự án [Thời gian] của nhà nghiên cứu được hỗ trợ.
5.2 Lựa chọn thiết kế cho vấn đề chuyên môn hóa và tổng quát hóa
Không phải lúc nào cũng dễ dàng chọn thiết kế khái niệm thích hợp nhất cho một ứng dụng cơ sở dữ liệu. Trong Phần 3.7.3, chúng tôi đã trình bày một số vấn đề điển hình mà một nhà thiết kế cơ sở dữ liệu phải đối mặt khi lựa chọn giữa các khái niệm về kiểu thực thể, kiểu quan hệ và thuộc tính để đại diện cho một miniworld cụ thể dưới dạng một lược đồ ER. Trong phần này, chúng tôi thảo luận về các hướng dẫn thiết kế và lựa chọn cho các khái niệm EER về chuyên môn hóa / tổng quát hóa và các danh mục (union type).
Như chúng tôi đã đề cập trong Phần 3.7.3, thiết kế cơ sở dữ liệu khái niệm nên được coi là một quá trình cải tiến lặp đi lặp lại cho đến khi đạt được thiết kế phù hợp nhất. Các hướng dẫn dưới đây có thể giúp bạn hình dung quy trình thiết kế cho các khái niệm EER
-
Nói chung, nhiều lớp chuyên biệt hóa và lớp con có thể được định nghĩa để làm cho mô hình khái niệm trở nên chính xác. Tuy nhiên, điểm hạn chế là thiết kế trở nên khá lộn xộn. Điều quan trọng là chỉ biểu diễn những lớp con được cho là cần thiết để tránh sự lộn xộn cực độ của lược đồ khái niệm.
-
Nếu một lớp con có ít thuộc tính cụ thể (cục bộ) và không có mối quan hệ cụ thể, nó có thể được hợp nhất vào lớp cha. Các thuộc tính cụ thể sẽ giữ giá trị NULL cho các thực thể không phải là thành viên của lớp con. Thuộc tính type có thể chỉ định liệu một thực thể có phải là thành viên của lớp con hay không.
-
Tương tự, nếu tất cả các lớp con của một chuyên môn hóa / tổng quát hóa có ít thuộc tính cụ thể và không có mối quan hệ cụ thể, chúng có thể được hợp nhất vào lớp cha và được thay thế bằng một hoặc nhiều thuộc tính kiểu chỉ định lớp con hoặc các lớp con mà mỗi thực thể thuộc về
-
Union và categories thường nên tránh trừ khi tình huống chắc chắn bảo đảm cho loại cấu trúc này, điều này xảy ra trong một số tình huống thực tế. Nếu có thể, chúng ta cố gắng lập mô hình bằng cách sử dụng chuyên môn hóa / tổng quát hóa như thảo luận
-
Việc lựa chọn các ràng buộc rời rạc / chồng chéo và toàn bộ / một phần đối với việc hình thành / tổng quát hóa đặc biệt được thúc đẩy bởi các quy tắc trong thế giới nhỏ đang được sửa đổi. Nếu các yêu cầu không chỉ ra bất kỳ ràng buộc cụ thể nào, mặc định nói chung sẽ là chồng chéo và từng phần, vì điều này không xác định nếu có bất kỳ hạn chế nào đối với tư cách thành viên lớp con.
Để làm ví dụ về việc áp dụng các hướng dẫn này, hãy xem Hình 4.6, không có thuộc tính cụ thể (cục bộ) nào được hiển thị. Chúng tôi có thể hợp nhất tất cả các lớp con thành loại thực thể EMPLOYEE và thêm các thuộc tính sau vào EMPLOYEE
-
Thuộc tính Job_type có tập giá trị {Secretary’, ‘Engineer’, ‘Technician’} sẽ cho biết lớp con nào trong chuyên môn đầu tiên mà mỗi nhân viên thuộc về.
-
Thuộc tính Pay_method có tập giá trị {‘Salaried’, ‘Hourly’} sẽ cho biết lớp con nào trong chuyên môn thứ hai mà mỗi nhân viên thuộc về
-
Thuộc tính Is_a_manager có tập giá trị {‘Yes, ‘No’} sẽ cho biết một thực thể nhân viên riêng lẻ có phải là người quản lý hay không.
5.3 Các định nghĩa chính thức cho mô hình EER
Bây giờ chúng ta tóm tắt các khái niệm mô hình EER và đưa ra các định nghĩa chính thức. Một lớp xác định một loại thực thể và đại diện cho một tập hợp hoặc tập hợp các thực thể thuộc loại đó; điều này bao gồm bất kỳ cấu trúc lược đồ EER nào tương ứng với tập hợp các thực thể, chẳng hạn như kiểu thực thể, lớp con, lớp cha và danh mục. Lớp con S là một lớp mà các thực thể của nó luôn phải là một tập con của các thực thể trong lớp khác, được gọi là lớp cha C của quan hệ lớp cha / lớp con (hoặc IS-A). Chúng tôi biểu thị mối quan hệ như vậy bằng C / S. Đối với mối quan hệ lớp cha / lớp con như vậy, chúng ta phải luôn có S ⊆ C
Chuyên biệt Z = {S1, S2,…, Sn} là tập các lớp con có cùng siêu lớp G; nghĩa là, G / Si là mối quan hệ lớp cha / lớp con đối với i = 1, 2,…, n. G được gọi là kiểu thực thể tổng quát hóa (hoặc lớp cha của chuyên môn hóa, hoặc tổng quát hóa của các lớp con {S1, S2,…, Sn}). Z được cho là tổng nếu chúng ta luôn (tại bất kỳ thời điểm nào) có
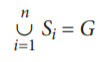
Nếu không, Z được cho là một phần. Z được cho là rời rạc nếu chúng ta luôn có
Si ∩ Sj = ∅ (empty set) for i ≠ j
Nếu không, Z được cho là chồng chéo.
Một lớp con S của C được cho là được xác định vị từ nếu một vị từ p trên các thuộc tính của C được sử dụng để chỉ định các thực thể nào trong C là thành viên của S; nghĩa là, S = C [p], trong đó C [p] là tập các thực thể trong C thỏa mãn p. Một lớp con không được xác định bởi một vị từ được gọi là do người dùng định nghĩa
Một chuyên biệt hóa Z (hoặc tổng quát hóa G) được cho là thuộc tính xác định nếu một vị từ (A = ci), trong đó A là một thuộc tính của G và ci là một giá trị không đổi từ miền của A, được sử dụng để chỉ định thành viên trong mỗi lớp con Si trong Z. Chú ý rằng nếu ci ≠ cj với i ≠ j, và A là một thuộc tính có giá trị đơn, thì nó là rời rạc.
Loại T là một lớp là một tập hợp con của sự kết hợp của n xác định các lớp cha D1, D2,…, Dn, n> 1 và được chỉ định chính thức như sau:
T ⊆ (D1 ∪ D2 ... ∪ Dn)
Một vị từ pi trên các thuộc tính của Di có thể được sử dụng để chỉ định các thành viên của mỗi Di là thành viên của T. Nếu một vị từ được chỉ định trên mọi Di, chúng ta nhận được
T = (D1[p1] ∪ D2[p2] ... ∪ Dn[pn])
Bây giờ chúng ta nên mở rộng định nghĩa về kiểu quan hệ được đưa ra trong Chương 3 bằng cách cho phép bất kỳ lớp nào — không chỉ bất kỳ kiểu thực thể nào — tham gia vào một mối quan hệ. Do đó, chúng ta nên thay thế các từ loại thực thể bằng lớp trong định nghĩa đó. Ký hiệu đồ họa của EER phù hợp với ER vì tất cả các lớp được biểu diễn bằng hình chữ nhật.
6. Ví dụ về ký hiệu khác: Biểu diễn sự chuyên môn hóa và tổng quát hóa trong sơ đồ lớp UML
Bây giờ chúng ta thảo luận về ký hiệu UML cho tổng quát hóa / chuyên biệt hóa và kế thừa. Chúng tôi đã trình bày thuật ngữ và ký hiệu sơ đồ lớp UML cơ bản trong Phần 3.8. Hình 4.10 minh họa một biểu đồ lớp UML có thể có tương ứng với biểu đồ EER trong Hình 4.7. Kí hiệu cơ bản cho đặc biệt hóa / tổng quát hóa (xem Hình 4.10) là kết nối các lớp con bằng các đường thẳng với một đường ngang, có một tam giác nối đường ngang qua một đường thẳng đứng khác với lớp cha. Hình tam giác trống biểu thị sự chuyên biệt hóa / tổng quát hóa với ràng buộc rời rạc và hình tam giác được tô đầy cho biết ràng buộc chồng chéo. Lớp cha gốc được gọi là lớp cơ sở, và các lớp con (nút lá) được gọi là lớp lá.
Phần thảo luận trước và ví dụ trong Hình 4.10, cũng như phần trình bày trong Phần 3.8, đã đưa ra một cái nhìn tổng quan ngắn gọn về các sơ đồ lớp UML và thuật ngữ. Chúng tôi tập trung vào các khái niệm có liên quan đến mô hình cơ sở dữ liệu ER và EER hơn là vào những khái niệm phù hợp hơn với kỹ thuật phần mềm. Trong UML, có nhiều chi tiết mà chúng ta chưa thảo luận vì chúng nằm ngoài phạm vi của môn học này và chủ yếu liên quan đến kỹ thuật phần mềm. Ví dụ, các lớp có thể có nhiều kiểu khác nhau:
-
Các lớp trừu tượng xác định các thuộc tính và hoạt động nhưng không có các đối tượng tương ứng với các lớp đó. Chúng chủ yếu được sử dụng để chỉ định một tập hợp các thuộc tính và hoạt động có thể được kế thừa.
-
Các lớp cụ thể có thể có các đối tượng (thực thể) được khởi tạo để thuộc về lớp.
-
Các lớp mẫu chỉ định một mẫu có thể được sử dụng thêm để định nghĩa các lớp khác.
Trong thiết kế cơ sở dữ liệu, chúng tôi chủ yếu quan tâm đến việc chỉ định các lớp cụ thể mà tập hợp các đối tượng được lưu trữ vĩnh viễn (hoặc liên tục) trong cơ sở dữ liệu. Các ghi chú thư mục ở cuối chương này cung cấp một số tài liệu tham khảo đến các sách mô tả chi tiết đầy đủ về UML.
7. Khái niệm trừu tượng hóa dữ liệu, biểu diễn tri thức và bản thể học
Trong phần này, chúng ta thảo luận một cách tổng quát về một số khái niệm mô hình mà chúng tôi đã mô tả khá cụ thể trong phần trình bày của chúng tôi về các mô hình ER và EER trong Chương 3 và trước đó trong chương này. Thuật ngữ này không chỉ được sử dụng trong mô hình hóa dữ liệu khái niệm mà còn được sử dụng trong các tài liệu về trí tuệ nhân tạo khi thảo luận về biểu diễn tri thức (KR). Phần này thảo luận về những điểm giống và khác nhau giữa mô hình hóa khái niệm và biểu diễn tri thức, đồng thời giới thiệu một số thuật ngữ thay thế và một số khái niệm bổ sung.
Mục tiêu của kỹ thuật KR là phát triển các khái niệm để mô hình hóa chính xác một số miền tri thức bằng cách tạo bản thể luận mô tả các khái niệm của miền và cách các khái niệm này có mối quan hệ với nhau. Bản thể luận được sử dụng để lưu trữ và vận dụng kiến thức để rút ra các suy luận, đưa ra quyết định hoặc trả lời các câu hỏi. Các mục tiêu của KR tương tự như các mục tiêu của mô hình dữ liệu ngữ nghĩa, nhưng có một số điểm tương đồng và khác biệt quan trọng giữa hai lĩnh vực:
-
Cả hai ngành đều sử dụng quy trình trừu tượng hóa để xác định các thuộc tính chung và các khía cạnh quan trọng của các đối tượng trong thế giới nhỏ (còn được gọi là miền diễn ngôn trong KR) trong khi loại bỏ các khác biệt không đáng kể và các chi tiết không quan trọng
-
Cả hai ngành đều cung cấp các khái niệm, mối quan hệ, ràng buộc, hoạt động và ngôn ngữ để xác định dữ liệu và biểu diễn tri thức.
-
KR thường có phạm vi rộng hơn so với các mô hình dữ liệu ngữ nghĩa. Các dạng kiến thức khác nhau, chẳng hạn như các quy tắc (được sử dụng trong suy luận, suy diễn và tìm kiếm), kiến thức không đầy đủ và mặc định, cũng như kiến thức thời gian và không gian, được biểu diễn trong lược đồ KR. Các mô hình cơ sở dữ liệu đang được mở rộng để bao gồm một số khái niệm này
-
Các lược đồ KR bao gồm các cơ chế lập luận suy ra các dữ kiện bổ sung từ các dữ kiện được lưu trữ trong cơ sở dữ liệu. Do đó, trong khi hầu hết các hệ thống cơ sở dữ liệu hiện tại bị giới hạn trong việc trả lời các truy vấn trực tiếp, các hệ thống dựa trên tri thức sử dụng lược đồ KR có thể trả lời các truy vấn liên quan đến suy luận về dữ liệu được lưu trữ. Công nghệ cơ sở dữ liệu đang được mở rộng với các cơ chế suy luận
-
Trong khi hầu hết các mô hình dữ liệu tập trung vào việc biểu diễn các lược đồ cơ sở dữ liệu hoặc siêu kiến thức, các lược đồ KR thường kết hợp các lược đồ với chính các phiên bản để cung cấp sự linh hoạt trong việc biểu diễn các ngoại lệ. Điều này thường dẫn đến sự kém hiệu quả khi các kế hoạch KR này được thực hiện, đặc biệt là khi so sánh với cơ sở dữ liệu và khi cần lưu trữ một lượng lớn dữ liệu có cấu trúc (sự kiện).
Bây giờ chúng ta thảo luận về bốn khái niệm trừu tượng được sử dụng trong các mô hình dữ liệu ngữ nghĩa, chẳng hạn như mô hình EER, cũng như trong các lược đồ KR: (1) phân loại và khởi tạo, (2) nhận dạng (trừu tượng hóa), (3) chuyên biệt hóa và tổng quát hóa, và (4) tập hợp và liên kết. Các khái niệm được ghép nối giữa phân loại và khởi tạo là nghịch đảo của nhau, cũng như khái quát hóa và chuyên môn hóa. Các khái niệm về tập hợp và liên kết cũng có liên quan với nhau. Chúng tôi thảo luận về các khái niệm trừu tượng này và mối quan hệ của chúng với các biểu diễn cụ thể được sử dụng trong mô hình EER để làm rõ quá trình trừu tượng hóa dữ liệu và nâng cao hiểu biết của chúng tôi về quy trình liên quan của thiết kế lược đồ khái niệm. Chúng tôi kết thúc phần này với một cuộc thảo luận ngắn gọn về KR, đang được sử dụng rộng rãi trong nghiên cứu biểu diễn tri thức gần đây.
7.1 Phân loại và Thuyết minh
Quá trình phân loại bao gồm việc gán các đối tượng / thực thể tương tự một cách có hệ thống cho các lớp đối tượng / kiểu thực thể. Bây giờ chúng ta có thể mô tả (trong DB) hoặc lý luận về (trong KR) các lớp hơn là các đối tượng riêng lẻ. Tập hợp các đối tượng có cùng kiểu thuộc tính, mối quan hệ và ràng buộc được phân loại thành các lớp để đơn giản hóa quá trình khám phá các thuộc tính của chúng. Instantiation là nghịch đảo của phân loại và đề cập đến việc tạo ra và kiểm tra cụ thể các đối tượng riêng biệt của một lớp. Một cá thể đối tượng liên quan đến lớp đối tượng của nó theo mối quan hệ IS-AN-INSTANCE-OF hoặc IS-A-MEMBER-OF. Mặc dù các biểu đồ EER không hiển thị các cá thể, nhưng các biểu đồ UML cho phép một dạng khởi tạo bằng cách cho phép hiển thị các đối tượng riêng lẻ. Chúng tôi đã không mô tả tính năng này trong phần giới thiệu của chúng tôi về sơ đồ lớp UML.
Nói chung, các đối tượng của một lớp nên có cấu trúc kiểu tương tự. Tuy nhiên, một số đối tượng có thể hiển thị các thuộc tính khác với các đối tượng khác của lớp ở một số khía cạnh; các đối tượng ngoại lệ này cũng cần được mô hình hóa và các lược đồ KR cho phép các ngoại lệ đa dạng hơn các mô hình cơ sở dữ liệu. Ngoài ra, một số thuộc tính nhất định áp dụng cho toàn bộ lớp chứ không áp dụng cho các đối tượng riêng lẻ; Các lược đồ KR cho phép các thuộc tính của lớp như vậy. Biểu đồ UML cũng cho phép đặc tả các thuộc tính của lớp
Trong mô hình EER, các thực thể được phân loại thành các loại thực thể theo các thuộc tính và mối quan hệ cơ bản của chúng. Các thực thể được phân loại thêm thành các lớp con và phân loại dựa trên những điểm tương đồng và khác biệt bổ sung (ngoại lệ) giữa chúng. Các cá thể của mối quan hệ được phân loại thành các kiểu quan hệ. Do đó, kiểu thực thể, lớp con, loại và kiểu quan hệ là những khái niệm khác nhau được sử dụng để phân loại trong mô hình EER. Mô hình EER không cung cấp các thuộc tính của lớp một cách rõ ràng, nhưng nó có thể được mở rộng để làm như vậy. Trong UML, các đối tượng được phân loại thành các lớp và có thể hiển thị cả các thuộc tính của lớp và các đối tượng riêng lẻ.
Các mô hình biểu diễn tri thức cho phép nhiều lược đồ phân loại trong đó một lớp là một thể hiện của lớp khác (được gọi là meta-class). Lưu ý rằng điều này không thể được biểu diễn trực tiếp trong mô hình EER, bởi vì chúng ta chỉ có hai cấp — lớp và thể hiện. Mối quan hệ duy nhất giữa các lớp trong mô hình EER là mối quan hệ lớp cha / lớp con, trong khi trong một số lược đồ KR, mối quan hệ lớp / cá thể bổ sung có thể được biểu diễn trực tiếp trong một hệ thống phân cấp lớp. Bản thân một cá thể có thể là một lớp khác, cho phép các lược đồ phân loại nhiều cấp.
7.2 Nhận dạng
Nhận dạng là quá trình trừu tượng hóa, theo đó các lớp và đối tượng được tạo ra có thể nhận dạng duy nhất bằng một số định danh. Ví dụ, một tên lớp xác định duy nhất một lớp trong một lược đồ. Một cơ chế bổ sung là cần thiết để phân biệt các cá thể đối tượng riêng biệt bằng các mã nhận dạng đối tượng. Hơn nữa, cần phải xác định nhiều biểu hiện trong cơ sở dữ liệu của cùng một đối tượng trong thế giới thực. Ví dụ: chúng ta có thể có một bộ giá trị trong quan hệ NGƯỜI và bộ khác trong quan hệ SINH VIÊN diễn ra đại diện cho cùng một thực thể trong thế giới thực. Không có cách nào để xác định thực tế là hai đối tượng cơ sở dữ liệu (bộ dữ liệu) này đại diện cho cùng một thực thể trong thế giới thực trừ khi chúng tôi đưa ra điều khoản tại thời điểm thiết kế cho việc tham chiếu chéo thích hợp để cung cấp nhận dạng này. Do đó, cần nhận dạng ở hai cấp độ:
-
Để phân biệt giữa các đối tượng và lớp cơ sở dữ liệu
-
Để xác định các đối tượng cơ sở dữ liệu và liên hệ chúng với các đối tác trong thế giới thực của chúng
Trong mô hình EER, việc xác định các cấu trúc lược đồ dựa trên một hệ thống các tên duy nhất cho các cấu trúc trong một lược đồ. Ví dụ: mọi lớp trong lược đồ EER — cho dù đó là kiểu thực thể, lớp con, danh mục hay kiểu quan hệ — đều phải có một tên riêng biệt. Tên của các thuộc tính của một lớp cụ thể cũng phải khác biệt. Cũng cần có các quy tắc để xác định rõ ràng các tham chiếu tên thuộc tính trong mạng hoặc hệ thống phân cấp riêng biệt hoặc tổng quát hóa.
Ở cấp độ đối tượng, giá trị của các thuộc tính chính được sử dụng để phân biệt giữa các thực thể của một loại thực thể cụ thể. Đối với các loại thực thể yếu, các thực thể được xác định bằng sự kết hợp của các giá trị khóa một phần của riêng chúng và các thực thể mà chúng có liên quan trong (các) loại thực thể chủ sở hữu. Các cá thể của mối quan hệ được xác định bằng một số kết hợp của các thực thể mà chúng có liên quan, tùy thuộc vào tỷ lệ bản số được chỉ định
7.3 Chuyên biệt hóa và tổng quát hóa
Chuyên môn hóa là quá trình phân loại một lớp đối tượng thành các lớp con chuyên biệt hơn. Tổng quát hóa là quá trình ngược lại của việc tổng quát hóa một số lớp thành một lớp trừu tượng cấp cao hơn bao gồm các đối tượng trong tất cả các lớp này. Chuyên môn hóa là sàng lọc khái niệm, trong khi khái quát hóa là tổng hợp khái niệm. Các lớp con được sử dụng trong mô hình EER để thể hiện sự chuyên môn hóa và tổng quát hóa. Chúng tôi gọi mối quan hệ giữa lớp con và lớp cha của nó là mối quan hệ IS-A-SUBCLASS-OF, hoặc đơn giản là mối quan hệ IS-A. Điều này cũng giống như thảo luận về mối quan hệ IS-A ở phần trước.
7.4 Tổng hợp và liên kết
Tổng hợp là một khái niệm trừu tượng để xây dựng các đối tượng tổng hợp từ các đối tượng thành phần của chúng. Có ba trường hợp mà khái niệm này có thể liên quan đến mô hình EER. Trường hợp đầu tiên là tình huống chúng ta tổng hợp các giá trị thuộc tính của một đối tượng để tạo thành toàn bộ đối tượng. Trường hợp thứ hai là khi chúng ta biểu diễn một mối quan hệ tổng hợp như một mối quan hệ thông thường. Trường hợp thứ ba, mà mô hình EER không cung cấp một cách rõ ràng, liên quan đến khả năng kết hợp các đối tượng có liên quan bởi một cá thể mối quan hệ cụ thể thành một đối tượng tổng hợp cấp cao hơn. Điều này đôi khi hữu ích khi bản thân đối tượng tổng hợp cấp cao hơn có liên quan đến một đối tượng khác. Chúng tôi gọi mối quan hệ giữa các đối tượng nguyên thủy và đối tượng tổng hợp của chúng là IS-A-PART-OF; nghịch đảo được gọi là IS-A-COMPONENT-OF. UML cung cấp cho cả ba loại tập hợp
Sự liên kết trừu tượng được sử dụng để liên kết các đối tượng từ một số lớp độc lập. Do đó, nó hơi giống với cách sử dụng tập hợp thứ hai. Nó được biểu diễn trong mô hình EER bởi các kiểu quan hệ và trong UML bởi các liên kết. Mối quan hệ trừu tượng này được gọi là IS-ASSOCIATED-WITH.
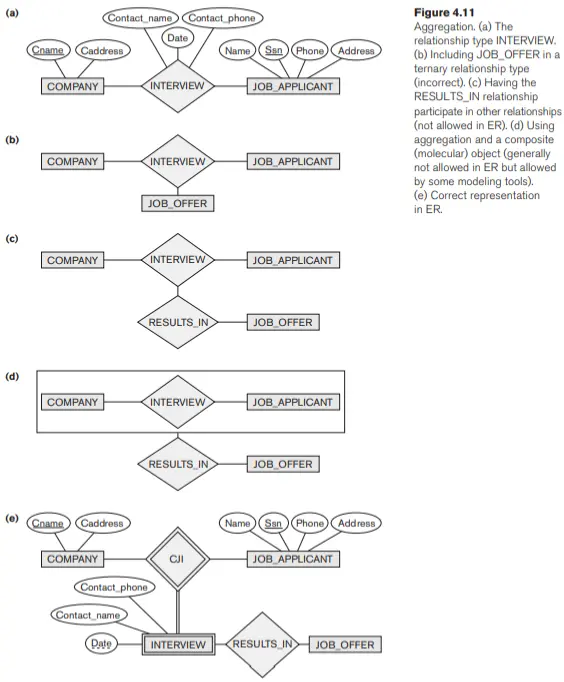
Để hiểu rõ hơn các cách sử dụng khác nhau của tổng hợp, hãy xem xét lược đồ ER được thể hiện trong Hình 4.11 (a), lược đồ này lưu trữ thông tin về các cuộc phỏng vấn của những người xin việc vào các công ty khác nhau. Lớp COMPANY là tập hợp các thuộc tính (hoặc các đối tượng thành phần) Cname (tên công ty) và Caddress (địa chỉ công ty), trong khi JOB_APPLICANT là tập hợp của Ssn, Name, Address và Phone. Thuộc tính mối quan hệ Contact_name và Contact_phone đại diện cho tên và số điện thoại của người chịu trách nhiệm phỏng vấn trong công ty. Giả sử rằng một số cuộc phỏng vấn dẫn đến lời mời làm việc, trong khi những cuộc phỏng vấn khác thì không. Chúng tôi muốn coi INTERVIEW là một lớp để liên kết nó với JOB_OFFER. Lược đồ thể hiện trong Hình 4.11 (b) không chính xác vì nó yêu cầu mỗi cá thể mối quan hệ phỏng vấn phải có một lời mời làm việc. Lược đồ thể hiện trong Hình 4.11 (c) không được phép vì mô hình ER không cho phép quan hệ tương đối giữa các mối quan hệ
Một cách để thể hiện tình huống này là tạo một lớp tổng hợp cấp cao hơn bao gồm COMPANY, JOB_APPLICANT và INTERVIEW và liên kết lớp này với JOB_OFFER, như thể hiện trong Hình 4.11 (d). Mặc dù mô hình EER như được mô tả trong cuốn sách này không có cơ sở này, nhưng một số mô hình dữ liệu ngữ nghĩa cho phép nó và gọi đối tượng kết quả là một đối tượng hỗn hợp hoặc phân tử. Các mô hình khác coi các kiểu thực thể và kiểu mối quan hệ một cách thống nhất và do đó cho phép mối quan hệ giữa các mối quan hệ, như được minh họa trong Hình 4.11 (c) .
Để biểu diễn tình huống này một cách chính xác trong mô hình ER như được mô tả ở đây, chúng ta cần tạo một INTERVIEW kiểu thực thể yếu mới, như thể hiện trong Hình 4.11 (e), và liên hệ nó với JOB_OFFER. Do đó, chúng ta luôn có thể biểu diễn các tình huống này một cách chính xác trong mô hình ER bằng cách tạo các kiểu thực thể bổ sung, mặc dù có thể mong muốn hơn về mặt khái niệm để cho phép biểu diễn tổng hợp trực tiếp, như trong Hình 4.11 (d) hoặc cho phép các mối quan hệ giữa các mối quan hệ, như trong Hình 4.11 (c)
Sự khác biệt về cấu trúc chính giữa tập hợp và liên kết là khi một cá thể liên kết bị xóa, các đối tượng tham gia có thể tiếp tục tồn tại. Tuy nhiên, nếu chúng tôi ủng hộ khái niệm về một đối tượng tổng hợp — ví dụ: CAR được tạo thành từ các đối tượng ENGINE, CHASSIS và TIRES — thì việc xóa đối tượng tổng hợp CAR sẽ đồng nghĩa với việc xóa tất cả các đối tượng thành phần của nó
7.5 Bản thể học và Web ngữ nghĩa
Trong những năm gần đây, số lượng dữ liệu máy tính và thông tin có sẵn trên Web đã vượt quá tầm kiểm soát. Nhiều mô hình và định dạng khác nhau được sử dụng. Ngoài các mô hình cơ sở dữ liệu mà chúng tôi trình bày trong văn bản này, nhiều thông tin được lưu trữ dưới dạng tài liệu, có cấu trúc ít hơn đáng kể so với thông tin cơ sở dữ liệu. Một dự án đang thực hiện đang cố gắng cho phép trao đổi thông tin giữa các máy tính trên Web được gọi là Web ngữ nghĩa, cố gắng tạo ra các mô hình biểu diễn tri thức khá chung chung để cho phép trao đổi và tìm kiếm thông tin có ý nghĩa giữa các máy. Khái niệm bản thể luận được coi là cơ sở hứa hẹn nhất để đạt được các mục tiêu của Web ngữ nghĩa và có liên quan chặt chẽ đến biểu diễn tri thức. Trong phần này, chúng tôi giới thiệu ngắn gọn về bản thể học là gì và nó có thể được sử dụng làm cơ sở để tự động hóa việc hiểu, tìm kiếm và trao đổi thông tin.
Nghiên cứu về bản thể học cố gắng mô tả các khái niệm và mối quan hệ có thể có trong thực tế thông qua một số từ vựng phổ biến; do đó, nó có thể được coi là một cách để mô tả kiến thức của một cộng đồng nhất định về thực tế. Bản thể học bắt nguồn từ các lĩnh vực triết học và siêu hình học. Một định nghĩa thường được sử dụng về bản thể học là một đặc tả của một khái niệm hóa
Theo định nghĩa này, khái niệm hóa là tập hợp các khái niệm và mối quan hệ được sử dụng để thể hiện phần thực tế hoặc kiến thức mà cộng đồng người dùng quan tâm. Đặc tả đề cập đến các thuật ngữ ngôn ngữ và từ vựng được sử dụng để chỉ định khái niệm. Bản thể luận bao gồm cả đặc tả và khái niệm hóa. Ví dụ, cùng một khái niệm có thể được chỉ định bằng hai ngôn ngữ khác nhau, tạo ra hai bản thể luận riêng biệt. Dựa trên định nghĩa chung này, không có sự đồng thuận về bản thể học chính xác là gì. Một số cách có thể để mô tả các bản thể học như sau:
-
Từ điển đồng nghĩa (hoặc thậm chí từ điển hoặc bảng chú giải thuật ngữ) mô tả mối quan hệ giữa các từ (từ vựng) đại diện cho các khái niệm khác nhau.
-
Phép phân loại mô tả cách các khái niệm của một lĩnh vực kiến thức cụ thể có liên quan với nhau bằng cách sử dụng các cấu trúc tương tự như các cấu trúc được sử dụng trong chuyên môn hóa hoặc khái quát hóa
-
Một số người coi một lược đồ cơ sở dữ liệu chi tiết là một bản thể luận mô tả các khái niệm (thực thể và thuộc tính) và các mối quan hệ của một thế giới nhỏ từ thực tế.
-
Một lý thuyết lôgic sử dụng các khái niệm từ lôgic toán học để cố gắng xác định các khái niệm và mối quan hệ qua lại giữa chúng
Thông thường, các khái niệm được sử dụng để mô tả bản thể học tương tự như các khái niệm chúng ta thảo luận trong mô hình khái niệm, chẳng hạn như thực thể, thuộc tính, mối quan hệ, chuyên biệt, v.v. Sự khác biệt chính giữa bản thể luận và lược đồ cơ sở dữ liệu, ví dụ, lược đồ này thường được giới hạn trong việc mô tả một tập hợp con nhỏ của một thế giới nhỏ từ thực tế để lưu trữ và quản lý dữ liệu. Bản thể luận thường được coi là tổng quát hơn ở chỗ nó cố gắng mô tả một phần của thực tế hoặc một lĩnh vực quan tâm (ví dụ: thuật ngữ y tế, ứng dụng thương mại điện tử, thể thao, v.v.) hoàn toàn có thể.
8. Tóm tắt
Bài viết khá dài nên mình sẽ tóm tắt các ý chính trong phần này như bên dưới:
- Mô hình EER bao gồm tất cả các khái niệm của mô hình thực thể quan hệ ER nhưng bổ sung thêm các khái niệm lớp cha / lớp con (subclasses / superclasses), tổng quát hoát và chuyên biệt hóa, phân loại, thừa kế thuộc tính -> Sử dụng để mô hình các ứng dụng phức tạp và sự chính xác cao hơn bao gồm một số khái niệm hướng đối tượng
- Trong mối quan hệ lớp cha / lớp con (quan hệ 1:1) mối liên kết với kiểu thực thể cha cho biết tất cả các kiểu thực thể con cũng tham gia mối liên kết này, có 4 kiểu ràng buộc là (disjoint - total, disjoint - partial, overlapping - total, overlapping - partial)
- Tổng quát hóa là quá trình định nghĩa một kiểu thực tế từ một tập các thực thể chuyên biệt ban đầu và chuyên biệt hóa là quá trình ngược lại
Chúc bạn đọc vui vẻ
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Cơ sở dữ liệu và hệ quản trị cơ sở dữ liệu là một thành phần thiết yếu của cuộc sống trong xã hội hiện đại: hầu hết chúng ta đều gặp các hoạt động liên quan đến hoạt động với cơ sở dữ liệu trong cuộc sống hằng ngày. Trong bài viết này chúng ta sẽ tìm hiểu khái niệm đầu tiên về hệ quản trị cơ sở dữ liệu và nhóm người dùng
Kiến trúc của các gói DBMS đã phát triển từ các hệ thống nguyên khối ban đầu, trong đó toàn bộ gói phần mềm DBMS là một hệ thống tích hợp chặt chẽ, đến các gói DBMS hiện đại được thiết kế theo dạng mô-đun, với kiến trúc client / server trong bài hôm nay mình cùng tìm hiểu về khái niệm và kiến trúc hệ quản trị cơ sở dữ liệu
Mô hình hóa khái niệm là một giai đoạn rất quan trọng trong việc thiết kế một ứng dụng cơ sở dữ liệu thành công. Thông thường, thuật ngữ ứng dụng cơ sở dữ liệu đề cập đến một cơ sở dữ liệu cụ thể và các chương trình liên quan thực hiện các truy vấn và cập nhật cơ sở dữ liệu. Trong bài này chúng ta sẽ tìm hiểu mô hình hóa dữ liệu với sơ đồ ER
Mô hình dữ liệu quan hệ lần đầu tiên được giới thiệu bởi Ted Codd của IBM Research vào năm 1970 trong một bài báo kinh điển (Codd, 1970), và nó đã thu hút sự chú ý ngay lập tức do tính đơn giản và nền tảng toán học của nó. Mô hình sử dụng khái niệm quan hệ toán học - trông giống như một bảng giá trị - làm khối xây dựng cơ bản của nó và có cơ sở lý thuyết trong lý thuyết tập hợp và logic vị từ bậc nhất.
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên