Kiến trúc hệ thống data warehouse
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kiến trúc luồng dữ liệu (Data flow architecture)
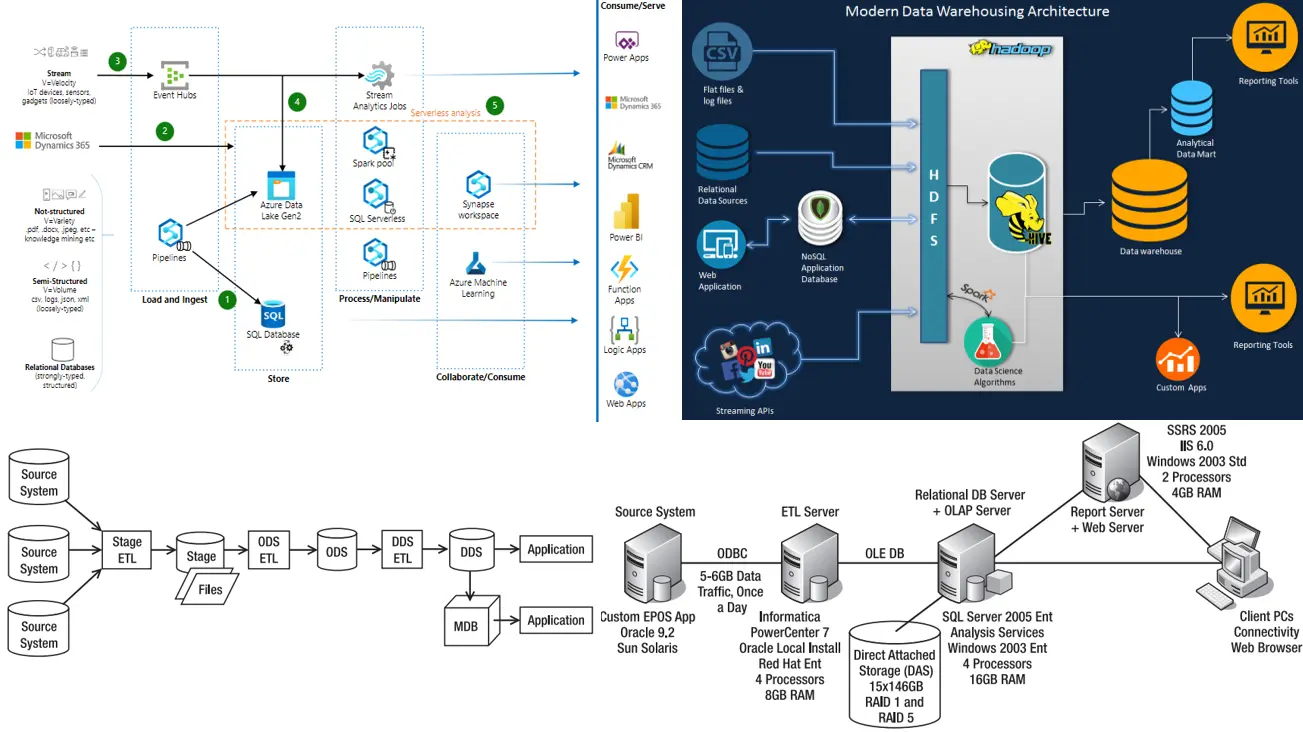
Trong kho dữ liệu, kiến trúc luồng dữ liệu là một cấu hình lưu trữ dữ liệu trong hệ thống kho dữ liệu, cùng với việc sắp xếp cách dữ liệu chảy từ hệ thống nguồn thông qua các kho lưu trữ dữ liệu này đến các ứng dụng được người dùng cuối sử dụng. Điều này bao gồm cách các luồng dữ liệu được kiểm soát, ghi nhật ký và giám sát, cũng như cơ chế đảm bảo chất lượng của dữ liệu trong kho lưu trữ dữ liệu. Chúng ta đã thảo luận ngắn gọn về kiến trúc luồng dữ liệu trong phần định nghĩa kho dữ liệu (data warehouse), nhưng trong bài này sẽ thảo luận chi tiết hơn, cùng với bốn kiến trúc luồng dữ liệu: Single DDS, NDS + DDS, ODS + DDS và kho dữ liệu liên kết.
Kiến trúc luồng dữ liệu khác với kiến trúc dữ liệu. Kiến trúc dữ liệu là về cách dữ liệu được sắp xếp trong mỗi kho dữ liệu và cách kho dữ liệu được thiết kế để phản ánh các quy trình kinh doanh. Hoạt động tạo ra kiến trúc dữ liệu được gọi là mô hình hóa dữ liệu
Lưu trữ dữ liệu là thành phần quan trọng của kiến trúc luồng dữ liệu. Tôi sẽ bắt đầu thảo luận về kiến trúc luồng dữ liệu bằng cách giải thích kho lưu trữ dữ liệu là gì. Kho lưu trữ dữ liệu là một hoặc nhiều cơ sở dữ liệu hoặc tệp chứa dữ liệu của kho dữ liệu, được sắp xếp theo một định dạng cụ thể và tham gia vào các hoạt động của kho dữ liệu.
Dựa trên khả năng truy cập của người dùng, bạn có thể phân loại kho lưu trữ dữ liệu kho dữ liệu thành ba loại:
- Kho lưu trữ dữ liệu hướng tới người dùng là kho lưu trữ dữ liệu phù hợp cho người dùng cuối và được truy vấn bởi người dùng cuối và các ứng dụng của người dùng cuối.
- Kho lưu trữ dữ liệu nội bộ là kho lưu trữ dữ liệu được sử dụng nội bộ bởi các thành phần kho dữ liệu nhằm mục đích tích hợp, làm sạch, ghi nhật ký và chuẩn bị dữ liệu và nó không mở để truy vấn bởi người dùng cuối và ứng dụng của người dùng cuối.
- Kho lưu trữ dữ liệu kết hợp được sử dụng cho cả cơ chế kho dữ liệu nội bộ và cho truy vấn của người dùng cuối và ứng dụng của người dùng cuối
Kho lưu trữ dữ liệu master là kho lưu trữ dữ liệu kết hợp hoặc hướng tới người dùng chứa một bộ dữ liệu hoàn chỉnh trong kho dữ liệu, bao gồm tất cả các phiên bản và tất cả dữ liệu lịch sử
Dựa trên định dạng dữ liệu, bạn có thể phân loại kho lưu trữ dữ liệu thành bốn loại:
- Stage là kho lưu trữ dữ liệu nội bộ được sử dụng để chuyển đổi và chuẩn bị dữ liệu thu được từ hệ thống nguồn, trước khi dữ liệu được tải đến các kho lưu trữ dữ liệu khác trong kho dữ liệu.
- Kho lưu trữ dữ liệu được chuẩn hóa (Normalized Data Store - NDS) là kho lưu trữ dữ liệu chính bên trong dưới dạng một hoặc nhiều cơ sở dữ liệu quan hệ được chuẩn hóa nhằm mục đích tích hợp dữ liệu từ các hệ thống nguồn khác nhau được thu thập trong một giai đoạn, trước khi dữ liệu được tải vào kho lưu trữ dữ liệu dành cho người dùng
- Kho lưu trữ dữ liệu vận hành (Operational Data Store - ODS) là một kho lưu trữ dữ liệu kết hợp ở dạng một hoặc nhiều cơ sở dữ liệu quan hệ được chuẩn hóa, chứa dữ liệu giao dịch và phiên bản mới nhất của dữ liệu chủ, nhằm mục đích hỗ trợ các ứng dụng vận hành.
- Kho lưu trữ dữ liệu thứ nguyên (Dimensional Data Store - DDS) là kho lưu trữ dữ liệu hướng tới người dùng, ở dạng một hoặc nhiều cơ sở dữ liệu quan hệ, trong đó dữ liệu được sắp xếp ở định dạng thứ nguyên nhằm mục đích hỗ trợ các truy vấn phân tích
Một số ứng dụng yêu cầu dữ liệu ở dạng cơ sở dữ liệu đa chiều (MDB) thay vì cơ sở dữ liệu quan hệ. MDB là một dạng cơ sở dữ liệu trong đó dữ liệu được lưu trữ trong các ô và vị trí của mỗi ô được xác định bởi một số biến được gọi là kích thước. Mỗi ô đại diện cho một sự kiện kinh doanh và giá trị của các thứ nguyên hiển thị thời gian và địa điểm sự kiện này xảy ra. MDB được điền từ DDS
Trích xuất, chuyển đổi và tải (ETL) là một hệ thống có khả năng đọc dữ liệu từ một kho lưu trữ dữ liệu, chuyển đổi dữ liệu và tải dữ liệu đó vào một kho lưu trữ dữ liệu khác. Kho lưu trữ dữ liệu nơi ETL đọc dữ liệu từ đó được gọi là nguồn và kho lưu trữ dữ liệu mà ETL tải dữ liệu vào được gọi là đích
Hình 2-1 cho thấy kiến trúc luồng dữ liệu với bốn kho lưu trữ dữ liệu: Stage, ODS, DDS và MDB.
Một gói ETL bao gồm một số xử lý ETL. Quy trình ETL là một chương trình nằm trong gói ETL truy xuất dữ liệu từ một hoặc một số nguồn và điền vào một bảng đích. Một xử lý ETL bao gồm một số bước. Một bước là một thành phần của xử lý ETL thực hiện một tác vụ cụ thể. Ví dụ trích xuất dữ liệu cụ thể từ kho lưu trữ dữ liệu nguồn hoặc thực hiện chuyển đổi dữ liệu nhất định. Các gói ETL trong kho dữ liệu được quản lý bởi một hệ thống điều khiển, là hệ thống quản lý thời gian mỗi gói ETL chạy, điều chỉnh trình tự thực hiện các xử lý trong một gói ETL và cung cấp khả năng khởi động lại các gói ETL từ điểm lỗi dẫn đến xử lý thất bại. Cơ chế ghi lại kết quả của từng bước trong xử lý ETL được gọi là ETL Audit. Ví dụ về kết quả được ghi lại bởi ETL Audit là có bao nhiêu bản ghi được chuyển đổi hoặc tải trong bước đó, thời gian bắt đầu và kết thúc bước cũng như mã định danh bước để bạn có thể theo dõi nó khi gỡ lỗi (debug) hoặc cho mục đích kiểm tra
Mô tả của từng xử lý ETL được lưu trữ trong siêu dữ liệu (metadata). Điều này bao gồm nguồn mà nó trích xuất dữ liệu, đích mà nó tải dữ liệu vào, chuyển đổi được áp dụng, xử lý gốc và lịch trình mỗi xử lý ETL được thực thi. Trong kho dữ liệu, siêu dữ liệu là kho lưu trữ dữ liệu chứa mô tả về cấu trúc, dữ liệu và các xử lý trong kho dữ liệu. Điều này bao gồm các định nghĩa và ánh xạ dữ liệu, cấu trúc dữ liệu của từng kho lưu trữ dữ liệu, cấu trúc dữ liệu của hệ thống nguồn, mô tả của từng quy trình ETL, mô tả quy tắc chất lượng dữ liệu và nhật ký của tất cả các xử lý và hoạt động trong kho dữ liệu
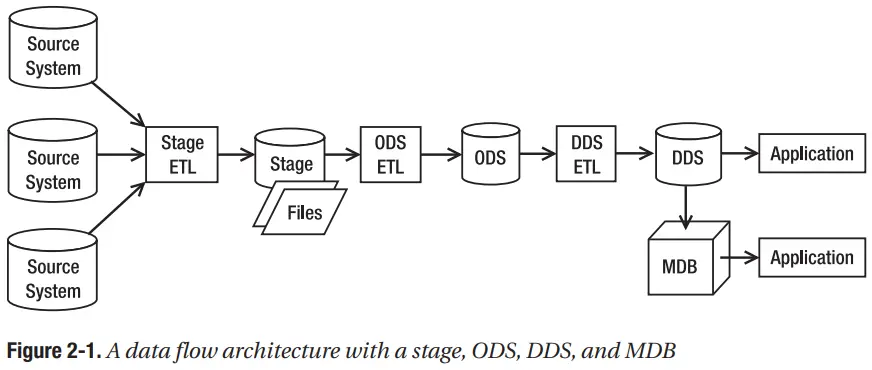
Xử lý chất lượng dữ liệu là các hoạt động và cơ chế để đảm bảo dữ liệu trong kho dữ liệu là chính xác và đầy đủ. Điều này thường được thực hiện bằng cách kiểm tra dữ liệu trên đường vào kho dữ liệu. Các xử lý về chất lượng dữ liệu cũng bao gồm cơ chế báo cáo dữ liệu xấu và sửa nó. Tường lửa dữ liệu là một chương trình kiểm tra xem dữ liệu đến có tuân thủ các quy tắc về chất lượng dữ liệu hay không. Quy tắc chất lượng dữ liệu là tiêu chí xác minh dữ liệu từ các hệ thống nguồn nằm trong phạm vi dự kiến và ở định dạng chính xác. Cơ sở dữ liệu "quality" là cơ sở dữ liệu chứa dữ liệu đến không đạt các quy tắc về chất lượng dữ liệu. Báo cáo chất lượng dữ liệu đọc các vi phạm chất lượng dữ liệu từ cơ sở dữ liệu "quality" (DQ) và hiển thị báo cáo.
Hình 2-2 cho thấy một kiến trúc luồng dữ liệu hoàn chỉnh với hệ thống kiểm soát, siêu dữ liệu và các thành phần của xử lý chất lượng dữ liệu.
Kiến trúc luồng dữ liệu là một trong những điều đầu tiên bạn cần quyết định khi xây dựng hệ thống kho dữ liệu vì kiến trúc luồng dữ liệu xác định những thành phần nào cần được xây dựng và do đó ảnh hưởng đến kế hoạch và chi phí dự án. Kiến trúc luồng dữ liệu cho biết cách dữ liệu chảy qua các kho lưu trữ dữ liệu trong kho dữ liệu
Kiến trúc luồng dữ liệu được thiết kế dựa trên các yêu cầu dữ liệu từ các ứng dụng, bao gồm các yêu cầu về chất lượng dữ liệu. Các ứng dụng kho dữ liệu yêu cầu dữ liệu ở các định dạng khác nhau. Các định dạng này quy định các kho lưu trữ dữ liệu bạn cần phải có. Nếu các ứng dụng yêu cầu định dạng chiều, thì bạn cần xây dựng một DDS. Nếu các ứng dụng yêu cầu định dạng chuẩn hóa cho mục đích hoạt động, thì bạn cần xây dựng một ODS. Nếu ứng dụng yêu cầu định dạng đa chiều thì bạn cần xây dựng một MDB. Khi bạn xác định kho lưu trữ dữ liệu mình cần xây dựng, bạn có thể thiết kế ETL để điền vào các kho lưu trữ dữ liệu đó. Sau đó, bạn xây dựng cơ chế chất lượng dữ liệu để đảm bảo dữ liệu trong kho dữ liệu là chính xác và đầy đủ.
Trong phần tiếp theo bài viết sẽ thảo luận về bốn kiến trúc luồng dữ liệu với những ưu điểm và nhược điểm của chúng:
- Kiến trúc DDS single có các kho lưu trữ dữ liệu Stage và DDS.
- Kiến trúc NDS + DDS có các kho lưu trữ dữ liệu Stage, NDS và DDS
- Kiến trúc ODS + DDS có các kho lưu trữ dữ liệu Stage, ODS và DDS.
- Kiến trúc kho dữ liệu liên kết (FDW) bao gồm một số kho dữ liệu được tích hợp bởi một lớp truy xuất dữ liệu.
Bốn kiến trúc luồng dữ liệu này chỉ là ví dụ. Khi xây dựng kho dữ liệu, bạn cần thiết kế kiến trúc luồng dữ liệu sao cho phù hợp với yêu cầu dữ liệu và yêu cầu chất lượng dữ liệu của dự án. Bốn kiến trúc này không phải là tất cả; bạn nên thiết kế kiến trúc luồng dữ liệu của riêng mình
Single DDS
Trong phần này, bạn sẽ tìm hiểu về kiến trúc luồng dữ liệu đơn giản chỉ bao gồm hai kho lưu trữ dữ liệu: Stage và DDS. Trong kiến trúc này, kho lưu trữ kho dữ liệu core ở định dạng thứ nguyên.
Trong kiến trúc single DDS, bạn có kho lưu trữ dữ liệu một chiều. DDS bao gồm một hoặc nhiều kho dữ liệu chiều. Một mart dữ liệu thứ nguyên là một nhóm các bảng dữ kiện có liên quan và các bảng thứ nguyên tương ứng của chúng có chứa phép đo các sự kiện kinh doanh, được phân loại theo thứ nguyên của chúng. Gói ETL trích xuất dữ liệu từ các hệ thống nguồn khác nhau và đưa chúng vào stage.
Stage là nơi bạn tạm thời lưu trữ dữ liệu mà bạn đã trích xuất từ hệ thống lưu trữ, trước khi xử lý thêm dữ liệu đó. Một stage là cần thiết khi quá trình chuyển đổi phức tạp (nói cách khác, không thể thực hiện nhanh chóng trong một bước duy nhất trong bộ nhớ), khi khối lượng dữ liệu lớn (nói cách khác, không đủ để đưa vào bộ nhớ) hoặc khi dữ liệu từ một số hệ thống nguồn đến vào các thời điểm khác nhau (nói cách khác, không được trích xuất bởi một ETL). Một stage cũng cần thiết nếu bạn cần giảm thiểu thời gian trích xuất dữ liệu từ hệ thống nguồn. Nói cách khác, các quy trình ETL kết xuất dữ liệu được trích xuất trên đĩa và ngắt kết nối khỏi hệ thống nguồn càng sớm càng tốt, sau đó vào thời điểm riêng của chúng, chúng có thể xử lý dữ liệu.
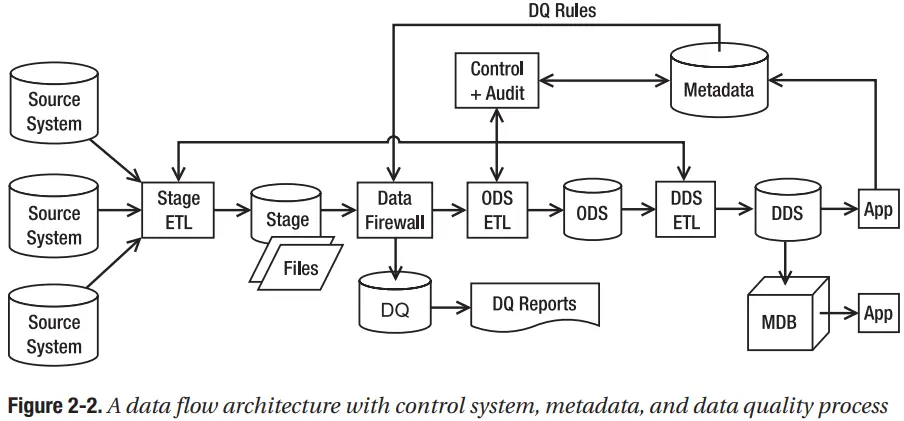
Hình thức vật lý của một stage có thể là cơ sở dữ liệu hoặc tệp. ETL trích xuất dữ liệu từ hệ thống nguồn sẽ chèn dữ liệu vào cơ sở dữ liệu hoặc ghi chúng dưới dạng tệp. Gói ETL thứ hai chọn dữ liệu từ giai đoạn, tích hợp dữ liệu từ hệ thống nguồn khác, áp dụng một số quy tắc chất lượng dữ liệu và đưa dữ liệu hợp nhất vào DDS. Hình 2-3 mô tả một mô hình chung của kiến trúc này.
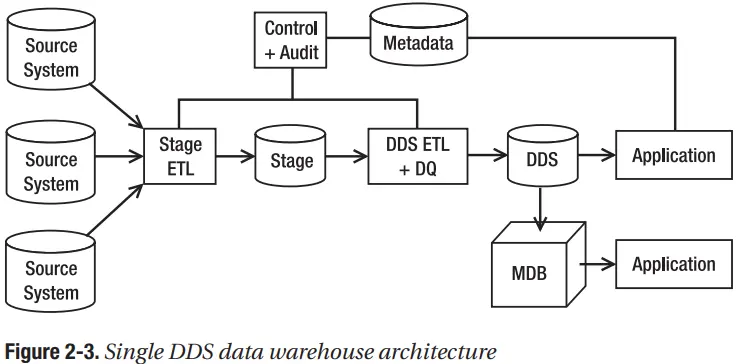
Trong Hình 2-3, “Control + Audit” chứa hệ thống kiểm soát và ETL Audit, như đã thảo luận trước đó. Chúng quản lý các xử lý ETL và ghi nhật ký kết quả thực thi ETL. Cơ sở dữ liệu metadata chứa mô tả về cấu trúc, dữ liệu và quy trình trong kho dữ liệu
Các ứng dụng kho dữ liệu, chẳng hạn như business intelligence (BI), đọc dữ liệu trong DDS và đưa dữ liệu đến người dùng. Dữ liệu trong DDS cũng có thể được tải lên cơ sở dữ liệu đa chiều, chẳng hạn như SQL Server Analysis Services, sau đó được người dùng truy cập thông qua OLAP và các ứng dụng khai thác dữ liệu.
Một số kiến trúc sư ETL thích kết hợp hai gói ETL và Stage trong Hình 2-3 thành một gói như trong Hình 2-4. Trong Hình 2-4, ETL giai đoạn, ETL DDS và các quy trình chất lượng dữ liệu được kết hợp thành một ETL. Ưu điểm của việc kết hợp chúng thành một gói là có nhiều quyền kiểm soát hơn đối với thời điểm dữ liệu được ghi vào và truy xuất từ Stage. Đặc biệt, bạn có thể tải dữ liệu trực tiếp vào DDS mà không cần đưa dữ liệu vào đĩa trước. Nhược điểm là gói ETL trở nên phức tạp hơn.
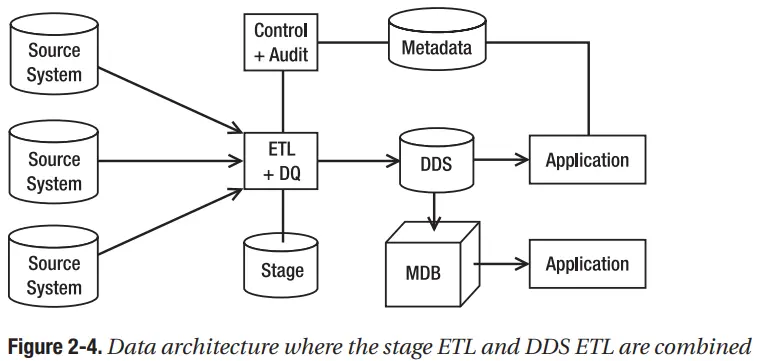
Một lợi thế của một kiến trúc DDS single là nó đơn giản hơn ba kiến trúc tiếp theo. Nó đơn giản hơn vì dữ liệu từ giai đoạn được tải thẳng vào kho lưu trữ dữ liệu thứ nguyên mà không cần đến bất kỳ loại kho lưu trữ chuẩn hóa nào trước. Nhược điểm chính là trong kiến trúc này, việc tạo một DDS thứ hai sẽ khó khăn hơn. DDS trong kiến trúc DDS duy nhất là kho lưu trữ dữ liệu chính. Nó chứa một bộ dữ liệu hoàn chỉnh trong kho dữ liệu. Một lợi thế của một kiến trúc DDS duy nhất là nó đơn giản hơn ba kiến trúc tiếp theo. Nó đơn giản hơn vì dữ liệu từ giai đoạn được tải thẳng vào kho lưu trữ dữ liệu thứ nguyên mà không cần đến bất kỳ loại kho lưu trữ chuẩn hóa nào trước. Nhược điểm chính là trong kiến trúc này, việc tạo một DDS thứ hai sẽ khó khăn hơn. DDS trong kiến trúc DDS single là kho lưu trữ dữ liệu chính. Nó chứa một bộ dữ liệu hoàn chỉnh trong kho dữ liệu
Ví dụ: người dùng có thể yêu cầu một DDS tĩnh nhỏ hơn chỉ chứa dữ liệu đơn đặt hàng nhằm mục đích phân tích tác động của việc tăng giá đối với các tài khoản khách hàng khác nhau. Họ muốn công cụ BI (ví dụ: Business Objects, Cognos hoặc Analysis Services) chạy trên DDS nhỏ hơn này để họ có thể phân tích mức tăng giá. Để tạo DDS nhỏ hơn này, bạn cần viết một gói ETL mới
Bạn sẽ sử dụng một kiến trúc DDS single khi bạn chỉ cần kho lưu trữ một chiều và bạn không cần kho lưu trữ dữ liệu chuẩn hóa. Nó được sử dụng cho một giải pháp BI phân tích đơn giản, nhanh chóng và dễ hiểu, trong đó dữ liệu chỉ được sử dụng để cung cấp cho kho dữ liệu thứ nguyên. Một giải pháp DDS duy nhất đặc biệt có thể áp dụng khi bạn chỉ có một hệ thống nguồn vì bạn không cần thêm NDS hoặc ODS để tích hợp dữ liệu từ các hệ thống nguồn khác nhau. So với kiến trúc NDS + DDS hoặc ODS + DDS, kiến trúc DDS single là kiến trúc đơn giản nhất để xây dựng và có thời gian chạy ETL nhanh nhất vì dữ liệu được tải thẳng vào DDS mà không cần vào kho lưu trữ dữ liệu NDS hoặc ODS trước.
NDS + DDS
Trong kiến trúc luồng dữ liệu NDS + DDS, có ba kho lưu trữ dữ liệu: Stage, NDS và DDS. Kiến trúc này tương tự như kiến trúc DDS single, nhưng nó có một kho lưu trữ dữ liệu được chuẩn hóa trước DDS. NDS ở dạng chuẩn hóa bậc ba hoặc cao hơn. Mục đích của việc có NDS gồm hai nhiệm vụ chính. Đầu tiên, nó tích hợp dữ liệu từ một số hệ thống nguồn. Thứ hai, nó có thể tải dữ liệu vào một số DDS. Không giống như kiến trúc DDS single, trong kiến trúc NDS + DDS, bạn có thể có nhiều DDS. Hình 2-5 cho thấy kiến trúc luồng dữ liệu NDS + DDS
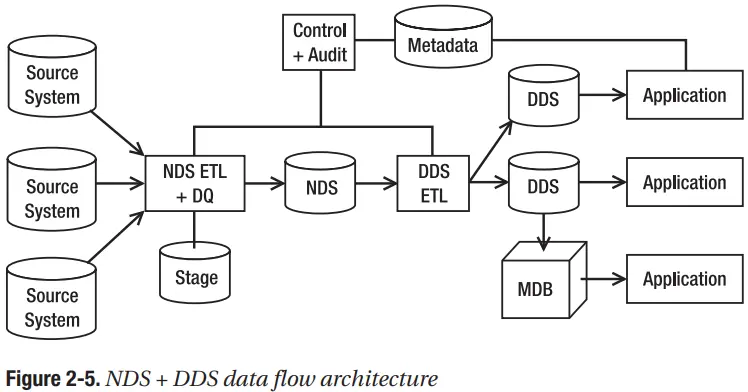
Trong kiến trúc NDS + DDS, NDS là kho lưu trữ dữ liệu chính, nghĩa là NDS chứa các bộ dữ liệu hoàn chỉnh, bao gồm tất cả dữ liệu giao dịch lịch sử và tất cả các phiên bản lịch sử của dữ liệu chính. Dữ liệu giao dịch lịch sử có nghĩa là các giao dịch kinh doanh đã xảy ra trong quá khứ. Dữ liệu từ mỗi năm được lưu trữ trong NDS. Mặt khác, DDS không phải là kho lưu trữ dữ liệu chính. Nó có thể không chứa tất cả dữ liệu giao dịch cho mỗi năm. NDS chứa tất cả các phiên bản lịch sử của dữ liệu master. Nếu có sự thay đổi trong dữ liệu master, các thuộc tính sẽ không bị ghi đè bởi các giá trị mới. Các giá trị mới được chèn dưới dạng một bản ghi mới và phiên bản cũ (hàng cũ) được giữ trong cùng một bảng
Tương tự như hệ thống nguồn OLTP, có hai loại bảng trong NDS: bảng giao dịch (transaction table) và bảng master (master table). Bảng giao dịch là bảng chứa giao dịch kinh doanh hoặc sự kiện kinh doanh. Bảng master là bảng chứa những người hoặc đối tượng tham gia vào sự kiện kinh doanh. Bảng đơn đặt hàng là một ví dụ về bảng giao dịch. Bảng sản phẩm là một ví dụ về bảng master. Các bảng giao dịch NDS là nguồn dữ liệu cho bảng DDS. Nói cách khác, các bảng thực tế trong DDS được điền từ các bảng giao dịch trong NDS. Các bảng master NDS là nguồn dữ liệu cho các bảng thứ nguyên DDS. Nghĩa là, các bảng kích thước trong DDS được điền từ các bảng master trong NDS
NDS là kho lưu trữ dữ liệu nội bộ, nghĩa là người dùng cuối hoặc các ứng dụng của người dùng cuối không thể truy cập được. Dữ liệu từ NDS được tải vào DDS ở định dạng thứ nguyên và người dùng cuối truy cập các DDS này. Ứng dụng duy nhất có thể cập nhật NDS là NDS ETL. Không ứng dụng nào khác có thể cập nhật NDS
Các nguyên tắc về stage, kiểm soát, audit và siêu dữ liệu (metadata) đã thảo luận trước đó cũng được áp dụng ở đây. Một số thực thể có thể di chuyển trực tiếp đến NDS mà không cần được sắp xếp vào đĩa trước. Trong trường hợp đó, việc tích hợp/chuyển đổi dữ liệu được thực hiện trực tuyến trong bộ nhớ của máy chủ ETL. ETL đọc dữ liệu từ hệ thống nguồn, biến đổi hoặc tích hợp dữ liệu trong bộ nhớ và ghi dữ liệu trực tiếp vào NDS mà không cần ghi bất kỳ thứ gì vào vùng hiển thị. Chuyển đổi dữ liệu là chuyển đổi, tính toán hoặc sửa đổi dữ liệu cho phù hợp với cơ sở dữ liệu đích. Tích hợp dữ liệu đang kết hợp cùng một bản ghi từ một số hệ thống nguồn khác nhau thành một bản ghi hoặc kết hợp các thuộc tính khác nhau của dữ liệu master hoặc dữ liệu giao dịch.
Trong kiến trúc NDS + DDS, DDS ETL tải dữ liệu vào DDS đơn giản hơn dữ liệu trong kiến trúc DDS single vì dữ liệu trong NDS đã được tích hợp và làm sạch. Trong một số trường hợp, DDS ETL chỉ cần cung cấp dữ liệu tăng dần cho DDS mà không có bất kỳ chuyển đổi nào. Hầu hết, nếu không muốn nói là tất cả, tính toán bảng dữ kiện đã được thực hiện trong NDS.
Dữ liệu trong NDS được tải lên DDS. Tính linh hoạt của việc sử dụng NDS tập trung là bạn có thể xây dựng một DDS mà bạn cần bất cứ lúc nào với phạm vi dữ liệu theo yêu cầu. Khả năng xây dựng một DDS mới bất cứ lúc nào rất hữu ích để đáp ứng các yêu cầu từ các dự án liên quan đến phân tích dữ liệu. Khả năng đặt phạm vi dữ liệu khi xây dựng DDS mới có nghĩa là bạn có thể chọn bảng, cột và hàng nào bạn muốn chuyển sang DDS mới. Ví dụ: bạn có thể xây dựng một DDS chỉ chứa một siêu thị dữ liệu về lợi nhuận của khách hàng (một bảng thực tế và tất cả các thứ nguyên của nó) chỉ chứa dữ liệu trong ba tháng qua.
Để tạo một DDS mới, bạn có thể sử dụng DDS ETL hiện có. Bạn chỉ cần trỏ ETL tới DDS mới. Nếu bạn xây dựng DDS ETL một cách chính xác, bạn có thể xây dựng lại bất kỳ DDS nào một cách nhanh chóng, nói cách khác, thời gian duy nhất chúng ta cần là thời gian để chạy ETL. Bạn không phải mất nhiều ngày hoặc nhiều tuần để xây dựng gói ETL mới để tải DDS mới. Để có được sự linh hoạt này, DDS ETL cần phải được tham số hóa; nghĩa là, phạm vi ngày, bảng thực tế và kích thước được sao chép đều được đặt làm tham số có thể dễ dàng thay đổi để trỏ đến một DDS mới. Chi tiết kết nối cơ sở dữ liệu cũng được viết dưới dạng tham số. Điều này cho phép bạn trỏ ETL tới cơ sở dữ liệu khác.
Trong kiến trúc NDS + DDS, bạn có thể có nhiều DDS. Nhưng có một DDS mà bạn phải xây dựng và duy trì: DDS chứa tất cả các bảng thực tế và tất cả các kích thước. Điều này là bắt buộc; tất cả các DDS khác là tùy chọn—bạn xây dựng chúng khi cần. Bạn cần có một DDS bắt buộc này vì nó chứa một bộ dữ liệu kho dữ liệu hoàn chỉnh và được sử dụng bởi tất cả các ứng dụng BI yêu cầu lưu trữ dữ liệu thứ nguyên
Các bảng NDS sử dụng khóa thay thế và khóa tự nhiên. Khóa thay thế là mã định danh của hàng dữ liệu master trong kho dữ liệu. Trong DDS, khóa thay thế được sử dụng làm khóa chính của bảng thứ nguyên. Khóa thay thế là một số nguyên tuần tự, bắt đầu từ 0. Vì vậy, nó là 0, 1, 2, 3, …, v.v. Sử dụng khóa thay thế, bạn có thể xác định một bản ghi duy nhất trên bảng thứ nguyên. Các khóa thay thế cũng tồn tại trong các bảng thực tế để xác định các thuộc tính thứ nguyên cho một giao dịch kinh doanh cụ thể. Các khóa thay thế được sử dụng để liên kết một bảng thực tế và các bảng thứ nguyên. Ví dụ: sử dụng các khóa thay thế, bạn có thể tìm hiểu thông tin chi tiết về khách hàng cho một đơn đặt hàng cụ thể. Trong kiến trúc NDS + DDS, các khóa thay thế được duy trì trong NDS, không phải trong DDS.
Khóa tự nhiên là mã định danh của hàng dữ liệu master trong hệ thống nguồn. Khi tải dữ liệu từ stage sang NDS, bạn cần dịch khóa tự nhiên từ hệ thống nguồn sang khóa thay thế kho dữ liệu. Bạn có thể thực hiện việc này bằng cách tra cứu khóa thay thế trong NDS cho từng giá trị khóa tự nhiên từ hệ thống nguồn. Nếu khóa tự nhiên tồn tại trong NDS, điều đó có nghĩa là bản ghi đã tồn tại trong NDS và cần được cập nhật. Nếu khóa tự nhiên không tồn tại trong NDS, điều đó có nghĩa là bản ghi không tồn tại trong NDS và cần được tạo.
Chỉ các ứng dụng quản trị nội bộ mới truy cập trực tiếp vào NDS. Đây thường là các ứng dụng xác minh dữ liệu được tải vào NDS, chẳng hạn như quy trình chất lượng dữ liệu kiểm tra dữ liệu NDS theo các quy tắc nhất định. Các ứng dụng người dùng cuối, chẳng hạn như báo cáo BI, truy cập DDS (mô hình thứ nguyên) và một số ứng dụng, chẳng hạn như ứng dụng OLAP, truy cập cơ sở dữ liệu đa chiều được tạo từ DDS. Bạn cần hiểu loại lưu trữ dữ liệu nào được yêu cầu bởi mỗi ứng dụng để có thể xác định kiến trúc luồng dữ liệu một cách chính xác.
Ưu điểm chính của kiến trúc này là bạn có thể dễ dàng xây dựng lại DDS chính; Ngoài ra, bạn có thể dễ dàng xây dựng một DDS mới, nhỏ hơn. Điều này là do NDS là kho lưu trữ dữ liệu chính, chứa một bộ dữ liệu hoàn chỉnh và vì DDS ETL được tham số hóa. Điều này cho phép bạn tạo một kho lưu trữ dữ liệu tĩnh riêng biệt cho mục đích phân tích cụ thể. Ưu điểm thứ hai là việc duy trì dữ liệu chính trong một kho lưu trữ chuẩn hóa như NDS và xuất bản từ đó sẽ dễ dàng hơn vì nó chứa ít hoặc không có dữ liệu dư thừa và vì vậy bạn chỉ cần cập nhật một nơi trong kho lưu trữ dữ liệu
Nhược điểm chính là nó đòi hỏi nhiều nỗ lực hơn so với kiến trúc DDS single vì dữ liệu từ stage cần phải được đưa vào NDS trước khi nó được tải lên DDS. Nỗ lực xây dựng ETL thực tế tăng gấp đôi vì bạn cần xây dựng hai bộ ETL, trong khi ở single DDS thì chỉ có một. Nỗ lực lập mô hình dữ liệu sẽ nhiều hơn khoảng 50% vì bạn cần thiết kế ba kho lưu trữ dữ liệu, trong khi trong single DDS, bạn có hai kho lưu trữ dữ liệu.
Kiến trúc NDS + DDS cung cấp tính linh hoạt tốt để tạo và duy trì kho lưu trữ dữ liệu, đặc biệt là khi tạo DDS. NDS là một ứng cử viên sáng giá cho kho dữ liệu doanh nghiệp. Nó chứa một bộ dữ liệu hoàn chỉnh, bao gồm tất cả các phiên bản của dữ liệu chính và được chuẩn hóa, gần như không có dữ liệu dư thừa, do đó, việc cập nhật dữ liệu dễ dàng và nhanh chóng hơn so với kho lưu trữ dữ liệu chính về chiều. Nó cũng chứa cả khóa tự nhiên của hệ thống nguồn và khóa thay thế kho dữ liệu, cho phép bạn ánh xạ và theo dõi dữ liệu giữa hệ thống nguồn và kho dữ liệu.
Bạn sẽ sử dụng kiến trúc NDS + DDS khi bạn cần tạo một số DDS cho các mục đích khác nhau có chứa một bộ dữ liệu khác và khi bạn cần tích hợp dữ liệu ở dạng chuẩn hóa và sử dụng dữ liệu tích hợp bên ngoài kho dữ liệu thứ nguyên.
ODS + DDS
Kiến trúc này tương tự như kiến trúc NDS + DDS, nhưng nó có ODS ở vị trí của NDS. Giống như NDS, ODS ở dạng chuẩn hóa bậc ba hoặc cao hơn. Không giống như NDS, ODS chỉ chứa phiên bản hiện tại của dữ liệu master; nó không có dữ liệu lịch sử của dữ liệu master. Cấu trúc của các thực thể của nó giống như một cơ sở dữ liệu OLTP. ODS không có khóa thay thế. Các khóa thay thế được duy trì trong DDS ETL. ODS tích hợp dữ liệu từ các hệ thống nguồn khác nhau. Dữ liệu trong ODS được làm sạch và tích hợp. Dữ liệu chảy vào ODS đã qua sàng lọc DQ. Hình 2-6 cho thấy kiến trúc luồng dữ liệu ODS+DDS.
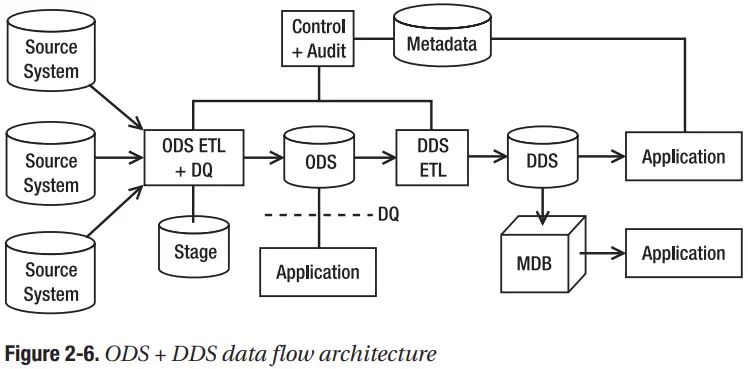
Giống như NDS, ODS chứa các bảng giao dịch và bảng master. Các bảng giao dịch chứa các sự kiện kinh doanh và các bảng chính chứa những người hoặc đối tượng tham gia vào các sự kiện kinh doanh. Các bảng thực tế trong DDS được điền từ các bảng giao dịch trong ODS. Các bảng kích thước trong DDS được điền từ các bảng chính trong ODS. Không giống như NDS, các bảng chính của ODS chỉ chứa phiên bản hiện tại của dữ liệu master. ODS không chứa các phiên bản lịch sử của dữ liệu master.
Không giống như NDS, là kho lưu trữ dữ liệu nội bộ, ODS là kho lưu trữ dữ liệu lai. Điều này có nghĩa là người dùng cuối và ứng dụng của người dùng cuối có thể truy cập ODS. Trong các ứng dụng NDS + DDS, người dùng cuối và ứng dụng của người dùng cuối không thể truy cập NDS. Không giống như NDS, ODS có thể cập nhật. Các ứng dụng của người dùng cuối có thể truy xuất dữ liệu từ ODS nhưng chúng cũng có thể cập nhật ODS. Để đảm bảo chất lượng của dữ liệu trong ODS, các quy tắc về chất lượng dữ liệu cũng được áp dụng cho các bản cập nhật này. Ứng dụng của người dùng cuối không được cập nhật dữ liệu đến từ hệ thống nguồn; nó chỉ có thể cập nhật dữ liệu do chính nó tạo ra để bổ sung cho dữ liệu của hệ thống nguồn. Nếu ODS được sử dụng để hỗ trợ ứng dụng hỗ trợ khách hàng CRM, dữ liệu như trạng thái và nhận xét có thể được ghi trực tiếp trên ODS, nhưng tất cả dữ liệu khách hàng vẫn từ hệ thống nguồn.
Trong kiến trúc ODS + DDS, DDS là kho lưu trữ dữ liệu master. Không giống như kiến trúc NDS + DDS, trong kiến trúc ODS + DDS, bạn chỉ có một DDS. DDS chứa một bộ đầy đủ các bảng thực tế và bảng thứ nguyên. DDS chứa cả phiên bản hiện tại và tất cả các phiên bản lịch sử của dữ liệu chính
Các nguyên tắc về stage, kiểm soát, audit và siêu dữ liệu được thảo luận liên quan đến kiến trúc DDS single cũng được áp dụng tại đây. Một số thực thể có thể đi trực tiếp đến ODS mà không cần phải qua stage. Tích hợp và chuyển đổi xảy ra trong bộ nhớ của máy chủ ETL. DDS ETL đơn giản hơn so với kiến trúc DDS single vì dữ liệu trong ODS đã được tích hợp và làm sạch. Trong nhiều trường hợp, theo đúng nghĩa đen, nó đang cung cấp DDS dần dần mà không có bất kỳ sự chuyển đổi nào. Hầu hết, nếu không muốn nói là tất cả, tính toán bảng thực tế đã được thực hiện trong ODS
Trong kiến trúc ODS + DDS, các ứng dụng có thể truy cập kho dữ liệu ở ba vị trí ở ba định dạng khác nhau: những ứng dụng cần dữ liệu ở dạng chuẩn hóa có thể truy cập ODS, những ứng dụng cần dữ liệu ở định dạng chiều quan hệ có thể truy cập DDS và những ứng dụng đó cần dữ liệu ở định dạng đa chiều có thể truy cập MDB
Kiến trúc này có những ưu điểm sau:
- Dạng chuẩn thứ ba mỏng hơn NDS vì nó chỉ chứa các giá trị hiện tại. Điều này làm cho hiệu suất của cả ODS ETL và DDS ETL tốt hơn so với hiệu suất trong kiến trúc NDS + DDS.
- Giống như kiến trúc NDS + DDS, trong kiến trúc ODS + DDS, bạn có một vị trí trung tâm để tích hợp, duy trì và xuất bản dữ liệu master
- Dữ liệu quan hệ được chuẩn hóa có thể cập nhật bởi ứng dụng của người dùng cuối, làm cho nó có khả năng hỗ trợ các ứng dụng hoạt động ở cấp độ giao dịch.
Nhược điểm của kiến trúc này là để xây dựng một DDS mới, nhỏ (ví dụ, dữ liệu bán hàng quý 4 năm 2007), bạn cần lấy nó từ DDS chính và không thể sử dụng DDS ETL hiện có để làm điều đó. Bạn cần viết các truy vấn tùy chỉnh (create table from select....), điều này không được ưu tiên vì lý do tiêu chuẩn hóa và tính nhất quán hoặc để xây dựng một ETL mới, điều này cũng không được ưa thích vì nỗ lực, đặc biệt nếu đó là một thứ chỉ dùng một lần, vứt đi.
Bạn sẽ sử dụng kiến trúc ODS + DDS khi bạn chỉ cần kho lưu trữ dữ liệu một chiều và bạn cần kho lưu trữ dữ liệu chuẩn hóa, tập trung để sử dụng cho các mục đích vận hành như CRM. ODS chứa dữ liệu tích hợp chi tiết, có giá trị hiện tại, hữu ích cho các truy vấn giao dịch.
Kho dữ liệu liên kết
kho dữ liệu được liên kết bao gồm một số kho dữ liệu với lớp truy xuất dữ liệu ở trên cùng. kho dữ liệu được liên kết truy xuất dữ liệu từ kho dữ liệu hiện có bằng cách sử dụng ETL và tải dữ liệu vào kho lưu trữ dữ liệu thứ nguyên mới. Ví dụ: do hoạt động sáp nhập và mua lại, bạn có thể có ba kho dữ liệu. Có lẽ cái đầu tiên là kho dữ liệu thứ nguyên, cái thứ hai là kho dữ liệu chuẩn hóa dạng chuẩn hóa bậc 3 và cái thứ ba là kho dữ liệu quan hệ với một vài bảng giao dịch lớn tham chiếu nhiều bảng tham chiếu. Hình 2-7 cho thấy một kho dữ liệu liên kết.
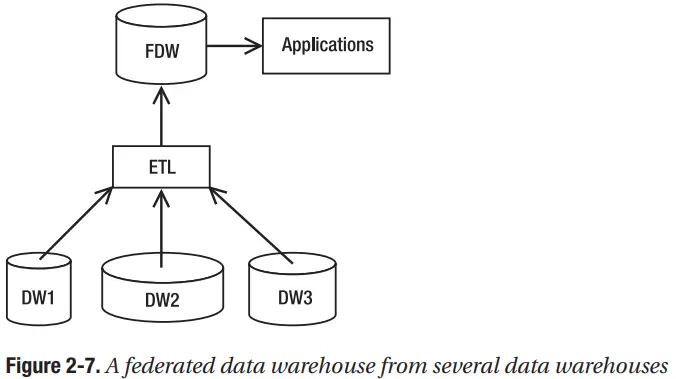
FDW ETL cần tích hợp dữ liệu từ các DW nguồn dựa trên các quy tắc kinh doanh. ETL cần xác định xem các bản ghi từ một kho dữ liệu nguồn có phải là bản sao của các bản ghi từ các kho dữ liệu nguồn khác hay không. Bản ghi trùng lặp cần được hợp nhất. Các quy tắc kinh doanh cần được áp dụng để xác định bản ghi nào sẽ tồn tại và thuộc tính nào cần được cập nhật. Ngoài ra, FDW ETL cần chuyển đổi dữ liệu từ các DW nguồn khác nhau thành một cấu trúc chung và định dạng chung.
Bạn cũng cần lưu ý rằng số lĩnh vực chủ đề trong FDW có thể hẹp hơn số lĩnh vực chủ đề trong DW nguồn. Điều này là do FDW ở mức cao hơn DW nguồn và ở mức này, không phải tất cả các lĩnh vực chủ đề đều có thể áp dụng và hữu ích cho người dùng doanh nghiệp. Ví dụ: trong kho dữ liệu toàn cầu, bạn có thể quan tâm đến doanh số bán hàng và nhân viên và để khoảng không quảng cáo cũng như chiến dịch trong kho dữ liệu khu vực.
Khi bạn có một vài kho dữ liệu như thế này, có thể triển khai tích hợp thông tin doanh nghiệp (EII) thay vì ETL, như được mô tả trong Hình 2-8, đặc biệt nếu các kho dữ liệu nguồn tương tự nhau. EII là một phương pháp để tích hợp dữ liệu bằng cách truy cập trực tuyến các hệ thống nguồn khác nhau và tổng hợp các đầu ra một cách nhanh chóng trước khi mang lại kết quả cuối cùng cho người dùng. Mọi thứ được thực hiện ngay khi người dùng yêu cầu thông tin. Không có kho lưu trữ dưới bất kỳ hình thức nào lưu trữ dữ liệu tổng hợp hoặc tích hợp. Ưu điểm chính của việc sử dụng EII là độ mới của dữ liệu; nói cách khác, kết quả thực sự là thời gian thực. Trong Hình 2-8, ngay cả khi nhà kho dữ liệu DW3 đã được thay đổi một giây trước, kết quả cuối cùng sẽ vẫn bao gồm thay đổi ở giây cuối cùng đó. Mặc dù không có kho dữ liệu tích hợp, đôi khi kiến trúc này còn được gọi là kho dữ liệu liên kết. Ví dụ: nếu tổ chức bao gồm ba khu vực địa lý, chẳng hạn như Châu Á Thái Bình Dương, Châu Mỹ và EMEA, thì mỗi khu vực có một hệ thống ERP khác nhau và các tổ chức CNTT khác nhau; do đó, họ có ba dự án kho dữ liệu. Nhưng tất cả đều đồng ý tiêu chuẩn hóa trên cùng một cấu trúc: kho dữ liệu thứ nguyên với các bảng thực tế và thứ nguyên
Thay vì tích hợp một số kho dữ liệu, kho dữ liệu liên kết cũng có thể được triển khai khi có một số kho dữ liệu không tích hợp trong tổ chức, như trong Hình 2-9.
.webp)
Các kho dữ liệu nguồn trong Hình 2-9 có thể ở nhiều dạng khác nhau. Chúng có thể là thứ nguyên, chuẩn hóa hoặc không. Các mart này có thể là hai bảng thực tế phù hợp được bao quanh bởi bốn đến tám kích thước phù hợp ở định dạng giản đồ sao, được thiết kế phù hợp bằng cách sử dụng phương pháp lập mô hình chiều Kimball. Chúng có thể ở định dạng snowflake trong đó kích thước được chuẩn hóa. Chúng có thể ở dạng chuẩn hóa bậc 3 (hoặc cao hơn). Và trong nhiều trường hợp, chúng có thể không phải là dữ liệu marts; nói cách khác, chúng không tuân theo bất kỳ phương pháp thiết kế kho dữ liệu chính thức nào và thay vào đó chỉ là một tập hợp các bảng có dữ liệu tốt bên trong chúng và người dùng gọi các bảng này là dữ liệu marts. Bạn có thể sử dụng FDW để tích hợp các kho dữ liệu này.
Các nguyên tắc tương tự được mô tả trước đây khi tích hợp kho dữ liệu vẫn được áp dụng, cụ thể là mức độ chi tiết, khớp/khử trùng lặp, định dạng lại, xử lý các vấn đề về thời gian và tính đa dạng của nền tảng. Trong một số trường hợp, bạn có thể cân nhắc việc bỏ qua một số mart và truy cập trực tiếp vào hệ thống nguồn, đặc biệt nếu cùng một hệ thống nguồn đang cung cấp cùng một dữ liệu cho các mart dữ liệu khác nhau.
Bạn vẫn có thể sử dụng phương pháp EII tại đây khi tích hợp các mart dữ liệu. Nghĩa là, bạn không có kho lưu trữ dữ liệu cố định ở cấp độ liên kết nhưng có thể truy cập nhanh vào kho dữ liệu nguồn khi người dùng đưa ra yêu cầu của họ.
Ưu điểm chính của kiến trúc này là bạn có thể chứa các kho dữ liệu hiện có và do đó thời gian phát triển sẽ ngắn hơn. Nhược điểm chính là, trên thực tế, rất khó để xây dựng một kho hàng chất lượng tốt từ các gian hàng đa dạng như vậy được tìm thấy trong siêu thị dữ liệu nguồn hoặc kho dữ liệu.
Bạn sẽ sử dụng kiến trúc kho dữ liệu được liên kết khi bạn muốn sử dụng các kho dữ liệu hiện có hoặc nơi bạn muốn tích hợp dữ liệu từ một số siêu thị dữ liệu.
Tổng kết
Trong phần này chúng ta đã tìm hiểu về kiến trúc luồng dữ liệu trong kho dữ liệu. Trong bài biết theo chúng ta sẽ tiếp tục với kiến trúc hạ tầng như phần cứng, mạng, server và phần mềm, hệ thống lưu trữ. Cảm ơn bạn đọc
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên