Chương 5: Mô hình dữ liệu quan hệ và cơ sở dữ liệu quan hệ

Nội dung bài viết
Mô hình dữ liệu quan hệ lần đầu tiên được giới thiệu bởi Ted Codd của IBM Research vào năm 1970 trong một bài báo kinh điển (Codd, 1970), và nó đã thu hút sự chú ý ngay lập tức do tính đơn giản và nền tảng toán học của nó. Mô hình sử dụng khái niệm quan hệ toán học - trông giống như một bảng giá trị - làm khối xây dựng cơ bản của nó và có cơ sở lý thuyết trong lý thuyết tập hợp và logic vị từ bậc nhất. Trong chương này, chúng ta thảo luận về các đặc điểm cơ bản của mô hình và các ràng buộc của nó
Các triển khai thương mại đầu tiên của mô hình quan hệ đã có sẵn vào đầu những năm 1980, chẳng hạn như hệ thống SQL / DS trên hệ điều hành MVS của IBM và Oracle DBMS. Kể từ đó, mô hình đã được thực hiện trong một số lượng lớn các hệ thống thương mại, cũng như một số hệ thống mã nguồn mở. Các DBMS quan hệ thương mại (RDBMS) phổ biến hiện nay bao gồm DB2 (của IBM), Oracle (của Oracle), Sybase DBMS (hiện tại của SAP), SQLServer và Microsoft Access (của Microsoft). Ngoài ra, một số hệ thống mã nguồn mở, chẳng hạn như MySQL và PostgreSQL, có sẵn ..
Vì tầm quan trọng của mô hình quan hệ, toàn bộ Phần 2 được dành cho mô hình này và một số ngôn ngữ liên quan đến nó. Trong Chương 6 và 7, chúng tôi mô tả một số khía cạnh của SQL, đây là một mô hình và ngôn ngữ toàn diện là tiêu chuẩn cho các DBMS quan hệ thương mại. (Các khía cạnh bổ sung của SQL sẽ được đề cập trong các chương khác.) Chương 8 bao gồm các hoạt động của đại số quan hệ và giới thiệu phép tính quan hệ — đây là hai ngôn ngữ chính thức được liên kết với mô hình quan hệ. Phép tính quan hệ được coi là cơ sở cho ngôn ngữ SQL và đại số quan hệ được sử dụng trong nội bộ của nhiều triển khai cơ sở dữ liệu để xử lý và tối ưu hóa truy vấn
Các đặc điểm khác của mô hình quan hệ được trình bày trong các phần tiếp theo của cuốn sách. Chương 9 liên hệ các cấu trúc dữ liệu mô hình quan hệ với các cấu trúc của mô hình ER và EER (được trình bày trong Chương 3 và 4), và trình bày các thuật toán để thiết kế một lược đồ cơ sở dữ liệu quan hệ bằng cách ánh xạ một lược đồ khái niệm trong mô hình ER hoặc EER thành một biểu diễn quan hệ . Các ánh xạ này được kết hợp vào nhiều công cụ thiết kế cơ sở dữ liệu và CASE. Chương 10 và 11 trong Phần 4 thảo luận về các kỹ thuật lập trình được sử dụng để truy cập hệ thống cơ sở dữ liệu và khái niệm kết nối với cơ sở dữ liệu quan hệ thông qua các giao thức chuẩn ODBC và JDBC. Chúng tôi cũng giới thiệu chủ đề lập trình cơ sở dữ liệu Web trong Chương 11. Chương 14 và 15 trong Phần 6 trình bày một khía cạnh khác của mô hình quan hệ, đó là các ràng buộc chính thức của các phụ thuộc hàm và đa giá trị; những phụ thuộc này được sử dụng để phát triển lý thuyết thiết kế cơ sở dữ liệu quan hệ dựa trên khái niệm được gọi là chuẩn hóa.
Trong chương này, chúng tôi tập trung mô tả các nguyên tắc cơ bản của mô hình quan hệ của dữ liệu. Chúng ta bắt đầu bằng cách xác định các khái niệm mô hình hóa và ký hiệu của mô hình quan hệ trong Phần 5.1. Phần 5.2 dành cho thảo luận về các ràng buộc quan hệ được coi là một phần quan trọng của mô hình quan hệ và được thực thi tự động trong hầu hết các DBMS quan hệ. Phần 5.3 xác định các hoạt động cập nhật của mô hình quan hệ, thảo luận về cách xử lý vi phạm các ràng buộc toàn vẹn và giới thiệu khái niệm về một giao dịch.
1 . Các khái niệm mô hình quan hệ
Mô hình quan hệ biểu diễn cơ sở dữ liệu như một tập hợp các quan hệ. Về mặt không chính thức, mỗi quan hệ giống như một bảng giá trị hoặc ở một mức độ nào đó, là một tệp hồ sơ phẳng. Nó được gọi là tệp phẳng vì mỗi bản ghi có cấu trúc tuyến tính hoặc phẳng đơn giản. Ví dụ, cơ sở dữ liệu của các tệp được thể hiện trong Hình 1.2 tương tự như biểu diễn mô hình quan hệ cơ bản. Tuy nhiên, có những khác biệt quan trọng giữa quan hệ và tệp, như chúng ta sẽ sớm thấy.
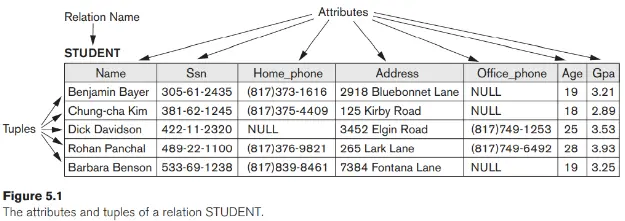
Khi một quan hệ được coi là một bảng giá trị, mỗi hàng trong bảng biểu thị một tập hợp các giá trị dữ liệu có liên quan. Một hàng đại diện cho một thực tế thường tương ứng với một thực thể hoặc mối quan hệ trong thế giới thực. Tên bảng và tên cột được sử dụng để giúp giải thích ý nghĩa của các giá trị trong mỗi hàng. Ví dụ, bảng đầu tiên của Hình 1.2 được gọi là STUDENT vì mỗi hàng đại diện cho các dữ kiện về một thực thể sinh viên cụ thể. Tên cột — Tên, Số sinh viên, Lớp và Chuyên ngành — chỉ định cách diễn giải các giá trị dữ liệu trong mỗi hàng, dựa trên cột mà mỗi giá trị có trong đó. Tất cả các giá trị trong một cột đều thuộc cùng một kiểu dữ liệu.
Trong thuật ngữ mô hình quan hệ chính thức, một hàng được gọi là bộ, tiêu đề cột được gọi là thuộc tính và bảng được gọi là quan hệ. Kiểu dữ liệu mô tả các loại giá trị có thể xuất hiện trong mỗi cột được biểu diễn bằng miền giá trị có thể có. Bây giờ chúng tôi xác định các thuật ngữ này — miền, tuple, thuộc tính và quan hệ — một cách chính thức.
1.1 Miền, thuộc tính, miền giá trị và mối quan hệ
Miền D là tập hợp các giá trị nguyên tử. Theo nguyên tử, chúng tôi muốn nói rằng mỗi giá trị trong miền là không thể phân chia được khi có liên quan đến mô hình quan hệ chính thức. Phương pháp phổ biến để chỉ định miền là chỉ định kiểu dữ liệu mà từ đó các giá trị dữ liệu tạo thành miền được rút ra. Nó cũng hữu ích khi chỉ định tên cho miền, để giúp giải thích các giá trị của nó. Một số ví dụ về miền sau:
-
Usa_phone_numbers. Tập hợp các số điện thoại gồm mười chữ số hợp lệ ở Hoa Kỳ.
-
Local_phone_numbers. Bộ số điện thoại gồm bảy chữ số hợp lệ trong một mã vùng cụ thể ở Hoa Kỳ. Việc sử dụng các số điện thoại địa phương đang nhanh chóng trở nên lỗi thời, được thay thế bằng các số có mười chữ số tiêu chuẩn
-
Social_security_numbers. Bộ số An sinh Xã hội gồm chín chữ số hợp lệ. (Đây là số nhận dạng duy nhất được chỉ định cho mỗi người ở Hoa Kỳ cho các mục đích quản lý việc làm, thuế và các lợi ích khác.)
-
Names: Tập hợp các chuỗi ký tự đại diện cho tên của người
-
Grade_point_averages.. Các giá trị có thể có của điểm trung bình được tính toán; mỗi số phải là một số thực (dấu phẩy động) từ 0 đến 4.
-
Employee_ages. Độ tuổi có thể có của nhân viên trong một công ty; mỗi giá trị phải là một giá trị nguyên từ 15 đến 80.
-
Academic_department_names. Tập hợp các tên khoa trong trường đại học, chẳng hạn như Khoa học Máy tính, Kinh tế và Vật lý.
-
Academic_department_codes. Tập hợp các mã khoa trong trường đại học, chẳng hạn như ‘CS’, ‘ECON’ và ‘PHYS’
Phần trên chúng ta đã định nghĩa lôgic của các miền. Một kiểu hoặc định dạng dữ liệu cũng được chỉ định cho mỗi miền. Ví dụ: kiểu dữ liệu cho miền Usa_phone_numbers có thể được khai báo dưới dạng chuỗi ký tự có dạng (ddd) ddd-dddd, trong đó mỗi d là một chữ số (thập phân) và ba chữ số đầu tiên tạo thành một mã vùng điện thoại hợp lệ. Kiểu dữ liệu cho Employee_ages là một số nguyên từ 15 đến 80. Đối với Academic_department_names, kiểu dữ liệu là tập hợp tất cả các chuỗi ký tự đại diện cho tên phòng ban hợp lệ. Do đó, một miền được cung cấp một tên, kiểu dữ liệu và định dạng. Thông tin bổ sung để giải thích các giá trị của một miền cũng có thể được cung cấp; ví dụ, một miền số như Person_weights phải có các đơn vị đo lường, chẳng hạn như pound hoặc kilôgam.
Một lược đồ quan hệ R, được ký hiệu là R (A1, A2,…, An), được tạo thành từ tên quan hệ R và danh sách các thuộc tính, A1, A2,…, An. Mỗi thuộc tính Ai là tên của một vai trò được thực hiện bởi một miền D nào đó trong lược đồ quan hệ R. D được gọi là miền của Ai và được ký hiệu là dom (Ai). Một lược đồ quan hệ được sử dụng để mô tả một quan hệ; R được gọi là tên của quan hệ này. Mức độ (hoặc độ hiếm) của một quan hệ là số thuộc tính n của lược đồ quan hệ của nó
Một quan hệ bậc bảy, lưu trữ thông tin về sinh viên đại học, sẽ chứa bảy thuộc tính mô tả mỗi sinh viên như sau:
STUDENT(Name, Ssn, Home_phone, Address, Office_phone, Age, Gpa)
Sử dụng kiểu dữ liệu của mỗi thuộc tính, định nghĩa đôi khi được viết là:
STUDENT(Name: string, Ssn: string, Home_phone: string, Address: string, Office_phone: string, Age: integer, Gpa: real)
Đối với lược đồ quan hệ này, STUDENT là tên của quan hệ, có bảy thuộc tính. Trong định nghĩa trước, chúng tôi đã chỉ định các kiểu chung như chuỗi hoặc số nguyên cho các thuộc tính. Chính xác hơn, chúng ta có thể chỉ định các miền được xác định trước đó sau đây cho một số thuộc tính của quan hệ STUDENT: dom (Name) = Names; dom (Ssn) = Social_security_numbers; dom (HomePhone) = USA_phone_numbers3, dom (Office_phone) = USA_phone_numbers và dom (Gpa) = Grade_point_a Average. Cũng có thể tham chiếu đến các thuộc tính của một lược đồ quan hệ theo vị trí của chúng trong quan hệ; do đó, thuộc tính thứ hai của quan hệ STUDENT là Ssn, trong khi thuộc tính thứ tư là Address
Một quan hệ (hoặc trạng thái quan hệ) r của lược đồ quan hệ R (A1, A2,…, An), cũng được ký hiệu là r (R), là một tập n bộ giá trị r = {t1, t2,…, tm}. Mỗi n-tuple t là một danh sách có thứ tự gồm n giá trị t = <v1, v2,…, vn>, trong đó mỗi giá trị vi, 1 ≤ i ≤ n, là một phần tử của dom (Ai) hoặc là một giá trị NULL đặc biệt. Giá trị thứ i trong tuple t, tương ứng với thuộc tính Ai, được gọi là t [Ai] hoặc t.Ai (hoặc t [i] nếu chúng ta sử dụng ký hiệu vị trí). Số nguyên quan hệ thuật ngữ cho lược đồ R và phần mở rộng quan hệ cho trạng thái quan hệ r (R) cũng thường được sử dụng.
Hình 5.1 cho thấy một ví dụ về quan hệ STUDENT, tương ứng với lược đồ STUDENT vừa được chỉ định. Mỗi bộ trong mối quan hệ đại diện cho một thực thể sinh viên (hoặc đối tượng) cụ thể. Chúng tôi hiển thị mối quan hệ dưới dạng bảng, trong đó mỗi bộ được hiển thị dưới dạng một hàng và mỗi thuộc tính tương ứng với một tiêu đề cột cho biết vai trò hoặc diễn giải của các giá trị trong cột đó. Giá trị NULL đại diện cho các thuộc tính có giá trị không xác định hoặc không tồn tại đối với một số bộ mã STUDENT cá nhân.
Định nghĩa trước đó của một quan hệ có thể được trình bày lại một cách chính thức hơn bằng cách sử dụng các khái niệm lý thuyết tập hợp như sau. Một quan hệ (hoặc trạng thái quan hệ) r (R) là một quan hệ toán học bậc n trên các miền dom (A1), dom (A2),…, dom (An), là một tập con của tích Descartes (ký hiệu là × ) của các miền xác định R:
r(R) ⊆ (dom(A1) × dom(A2) × . . . × (dom(An))
Sản phẩm Descartes chỉ định tất cả các kết hợp giá trị có thể có từ các miền cơ bản. Do đó, nếu chúng ta biểu thị tổng số giá trị, hoặc bản số, trong miền D bằng | D | (giả sử rằng tất cả các miền đều hữu hạn), tổng số bộ giá trị trong tích Descartes là
|dom(A1)| × |dom(A2)| × . . . × |dom(An)|
Tích số của tất cả các miền này đại diện cho tổng số các trường hợp hoặc bộ giá trị có thể tồn tại trong bất kỳ trạng thái quan hệ nào r (R). Trong tất cả các kết hợp có thể có này, một trạng thái quan hệ tại một thời điểm nhất định - trạng thái quan hệ hiện tại - chỉ phản ánh các bộ giá trị hợp lệ đại diện cho một trạng thái cụ thể của thế giới thực. Nói chung, khi trạng thái của thế giới thực thay đổi, trạng thái quan hệ cũng vậy, bằng cách chuyển thành trạng thái quan hệ khác. Tuy nhiên, lược đồ R tương đối tĩnh và thay đổi rất thường xuyên — ví dụ, do thêm một thuộc tính để biểu diễn thông tin mới mà ban đầu không được lưu trữ trong mối quan hệ.
Có thể một số thuộc tính có cùng một miền. Các tên thuộc tính thể hiện các vai trò hoặc cách diễn giải khác nhau cho miền. Ví dụ: trong quan hệ STUDENT, cùng một miền USA_phone_numbers đóng vai trò Home_phone, đề cập đến điện thoại nhà của học sinh và vai trò của Office_phone, đề cập đến điện thoại văn phòng của học sinh. Thuộc tính thứ ba có thể có (không hiển thị) với cùng một miền có thể là Mobile_phone
1.2 Đặc điểm của mối quan hệ
Định nghĩa trước đó của các quan hệ ngụ ý một số đặc điểm nhất định làm cho một quan hệ khác với một tệp hoặc một bảng. Bây giờ chúng ta thảo luận về một số đặc điểm này.
Thứ tự các Tuples trong một mối quan hệ. Một quan hệ được định nghĩa là một tập hợp các bộ giá trị. Toán học giả lập, các phần tử của một tập hợp không có thứ tự nào trong số chúng; do đó, các bộ giá trị trong một mối quan hệ không có bất kỳ thứ tự cụ thể nào. Nói cách khác, một quan hệ không liên quan với thứ tự của các bộ giá trị. Tuy nhiên, trong một tệp, các bản ghi được lưu trữ vật lý trên đĩa (hoặc trong bộ nhớ), vì vậy luôn có thứ tự giữa các bản ghi. Thứ tự này cho biết các bản ghi đầu tiên, thứ hai, thứ i và cuối cùng trong tệp. Tương tự, khi chúng tôi hiển thị một quan hệ dưới dạng bảng, các hàng được hiển thị theo một thứ tự nhất định. Thứ tự Tuple không phải là một phần của định nghĩa quan hệ vì một quan hệ cố gắng phản hồi lại các dữ kiện ở cấp độ logic hoặc trừu tượng. Nhiều đơn đặt hàng có thể được chỉ định trên cùng một quan hệ. Ví dụ, các bộ giá trị trong quan hệ STUDENT trong Hình 5.1 có thể được sắp xếp theo các giá trị Tên, Ssn, Tuổi hoặc một số thuộc tính khác. Định nghĩa của một quan hệ không xác định bất kỳ thứ tự nào: Không có ưu tiên cho thứ tự này hơn thứ tự khác. Do đó, quan hệ được hiển thị trong Hình 5.2 được coi là giống với quan hệ trong Hình 5.1. Khi một quan hệ được triển khai dưới dạng tệp hoặc được hiển thị dưới dạng bảng, một thứ tự cụ thể có thể được chỉ định trên các bản ghi của tệp hoặc các hàng của bảng.
Thứ tự các giá trị trong một Tuple và một định nghĩa thay thế của một mối quan hệ. Theo định nghĩa trước về một quan hệ, n-tuple là một danh sách có thứ tự gồm n giá trị, vì vậy thứ tự của các giá trị trong một bộ - và do đó của các thuộc tính trong một lược đồ quan hệ - là quan trọng. Tuy nhiên, ở cấp độ trừu tượng hơn, thứ tự của các thuộc tính và giá trị của chúng không quan trọng miễn là sự tương ứng giữa các thuộc tính và giá trị được duy trì.
Có thể đưa ra một định nghĩa khác về một quan hệ, làm cho thứ tự của các giá trị trong một bộ giá trị không cần thiết. Theo định nghĩa này, lược đồ quan hệ R = {A1, A2,…, An} là một tập hợp các thuộc tính (thay vì một danh sách các thuộc tính có thứ tự) và một trạng thái quan hệ r (R) là một tập hợp hữu hạn các ánh xạ r = { t1, t2,…, tm}, trong đó mỗi tuple ti là một ánh xạ từ R đến D, và D là liên hợp (ký hiệu là ∪) của các miền thuộc tính; nghĩa là, D = dom (A1) ∪ dom (A2) ∪… ∪ dom (An). Theo định nghĩa này, t [Ai] phải nằm trong dom (Ai) với 1 ≤ i ≤ n đối với mỗi ánh xạ t trong r. Mỗi ti ánh xạ được gọi là một bộ.
Theo định nghĩa này về tuple như một ánh xạ, một tuple có thể được coi là một tập hợp các cặp (<attribute>,<value>), trong đó mỗi cặp cho giá trị của ánh xạ từ một thuộc tính Ai đến một giá trị vi từ dom (Ai). Thứ tự của các thuộc tính không quan trọng, vì tên thuộc tính xuất hiện cùng với giá trị của nó. Theo định nghĩa này, hai bộ giá trị trong Hình 5.3 là giống hệt nhau. Điều này có ý nghĩa ở cấp độ trừu tượng, vì thực sự không có lý do gì để thích có một giá trị thuộc tính xuất hiện trước một giá trị thuộc tính khác trong một bộ giá trị. Khi tên thuộc tính và giá trị được bao gồm cùng nhau trong một bộ, nó được gọi là dữ liệu tự mô tả, vì mô tả của mỗi giá trị (tên thuộc tính) được bao gồm trong bộ.

Chúng tôi chủ yếu sẽ sử dụng định nghĩa đầu tiên của quan hệ, trong đó các thuộc tính được sắp xếp thứ tự trong lược đồ quan hệ và các giá trị trong các bộ giá trị được sắp xếp tương tự, bởi vì nó đơn giản hóa phần lớn ký hiệu. Tuy nhiên, định nghĩa thay thế được đưa ra ở đây là tổng quát hơn.
Giá trị và NULL trong Tuples. Mỗi giá trị trong một tuple là một giá trị nguyên tử; nghĩa là nó không thể chia thành các thành phần trong khuôn khổ của mô hình quan hệ cơ bản. Do đó, các thuộc tính tổng hợp và nhiều giá trị (xem Chương 3) không được phép. Mô hình này đôi khi được gọi là mô hình quan hệ phẳng. Phần lớn lý thuyết đằng sau mô hình quan hệ được phát triển với giả định này, được gọi là giả định dạng chuẩn đầu tiên. Do đó, các thuộc tính đa giá trị phải được biểu diễn bằng các quan hệ riêng biệt và các thuộc tính tổng hợp chỉ được biểu diễn bằng các thuộc tính thành phần đơn giản của chúng trong mô hình quan hệ cơ bản.
Một khái niệm quan trọng là giá trị NULL, được sử dụng để đại diện cho giá trị của các thuộc tính có thể không xác định hoặc có thể không áp dụng cho một bộ giá trị. Một giá trị đặc biệt, được gọi là NULL, được sử dụng trong những trường hợp này. Ví dụ, trong Hình 5.1, một số bộ giá trị SINH VIÊN có NULL cho điện thoại văn phòng của họ vì họ không có văn phòng (nghĩa là điện thoại văn phòng không áp dụng cho những sinh viên này). Một học sinh khác có NULL cho điện thoại nhà, có lẽ là do anh ta không có điện thoại ở nhà hoặc anh ta có nhưng chúng tôi không biết nó (giá trị không xác định). Nói chung, chúng ta có thể có một số ý nghĩa cho các giá trị NULL, chẳng hạn như giá trị không xác định, giá trị tồn tại nhưng không có sẵn hoặc thuộc tính không áp dụng cho bộ giá trị này (còn được gọi là giá trị không xác định). Ví dụ về kiểu NULL cuối cùng sẽ xảy ra nếu chúng ta thêm thuộc tính Visa_status vào quan hệ STUDENT chỉ áp dụng cho các bộ giá trị đại diện cho sinh viên nước ngoài. Có thể tạo ra các mã khác nhau cho các ý nghĩa khác nhau của các giá trị NULL. Việc kết hợp các loại giá trị NULL khác nhau vào các hoạt động mô hình quan hệ đã được chứng minh là khó khăn và nằm ngoài phạm vi của phần trước của chúng tôi
Ý nghĩa chính xác của giá trị NULL chi phối cách giá trị của nó trong quá trình tổng hợp số học hoặc so sánh với các giá trị khác. Ví dụ: so sánh hai giá trị NULL dẫn đến sự không rõ ràng — nếu cả Khách hàng A và B đều có địa chỉ NULL, điều đó không có nghĩa là họ có cùng địa chỉ. Trong quá trình thiết kế cơ sở dữ liệu, tốt nhất là tránh các giá trị NULL càng nhiều càng tốt. Chúng ta sẽ thảo luận thêm về vấn đề này trong bối cảnh thiết kế và chuẩn hóa cơ sở dữ liệu.
Diễn giải (Ý nghĩa) của một mối quan hệ. Lược đồ quan hệ có thể được hiểu là một khai báo hoặc một kiểu khẳng định. Ví dụ, lược đồ quan hệ STUDENT của Hình 5.1 khẳng định rằng, nói chung, một thực thể sinh viên có Name, Ssn, Home_phone, Address, Office_phone, Age và Gpa. Mỗi bộ trong mối quan hệ sau đó có thể được hiểu là một dữ kiện hoặc một trường hợp cụ thể của khẳng định. Ví dụ, bộ đầu tiên trong Hình 5.1 khẳng định thực tế rằng có một STUDENT có Tên là Benjamin Bayer, Ssn là 305-61-2435, Tuổi là 19, v.v.
Lưu ý rằng một số quan hệ có thể đại diện cho các dữ kiện về các thực thể, trong khi các quan hệ khác có thể đại diện cho các dữ kiện về các mối quan hệ. Ví dụ, một lược đồ quan hệ MAJORS (Student_ssn, Department_code) khẳng định rằng sinh viên chuyên về các ngành học. Một bộ trong mối quan hệ này liên quan đến một sinh viên với ngành học chính của họ. Do đó, mô hình quan hệ biểu diễn các dữ kiện về cả thực thể và các mối quan hệ một cách thống nhất dưới dạng quan hệ. Điều này đôi khi làm ảnh hưởng đến tính dễ hiểu bởi vì người ta phải đoán xem một quan hệ đại diện cho một loại thực thể hay một loại quan hệ. Chúng tôi đã giới thiệu chi tiết mô hình mối quan hệ-thực thể (ER) trong Chương 3, nơi các khái niệm thực thể và mối quan hệ được mô tả chi tiết. Các thủ tục ánh xạ trong Chương 9 cho thấy cách các cấu trúc khác nhau của các mô hình dữ liệu khái niệm ER / EER (xem Phần 2) được chuyển đổi thành các quan hệ.
Một giải thích thay thế của một lược đồ quan hệ là như một vị từ; trong trường hợp này, các giá trị trong mỗi bộ được hiểu là các giá trị thỏa mãn vị từ. Ví dụ, vị từ STUDENT (Name, Ssn,…) đúng với năm bộ giá trị trong quan hệ STUDENT của Hình 5.1. Những bộ giá trị này đại diện cho năm mệnh đề hoặc sự kiện khác nhau trong thế giới thực. Cách diễn giải này khá hữu ích trong ngữ cảnh của các ngôn ngữ lập trình lôgic, chẳng hạn như Prolog, vì nó cho phép mô hình quan hệ được sử dụng trong các ngôn ngữ này (xem Phần 26.5). Một giả định được gọi là giả định thế giới đóng nói rằng những sự thật duy nhất trong vũ trụ là những sự kiện hiện diện trong phần mở rộng (trạng thái) của (các) mối quan hệ. Bất kỳ sự kết hợp giá trị nào khác đều làm cho vị từ sai. Cách diễn giải này rất hữu ích khi chúng ta xem xét các truy vấn về quan hệ dựa trên phép tính quan hệ trong phần sau
1.3 Ký hiệu mô hình quan hệ
Chúng tôi sẽ sử dụng ký hiệu sau trong bản trình bày của mình:
-
Một lược đồ quan hệ R bậc n được ký hiệu là R (A1, A2,…, An)
-
Các chữ cái in hoa Q, R, S biểu thị tên quan hệ.
-
Các chữ cái thường q, r, s biểu thị các trạng thái quan hệ
-
Các chữ cái t, u, v biểu thị các bộ giá trị.
-
Nói chung, tên của một lược đồ quan hệ chẳng hạn như STUDENT cũng chỉ ra tập hợp các bộ giá trị hiện tại trong mối quan hệ đó — trạng thái quan hệ hiện tại — trong khi STUDENT (Name, Ssn,…) chỉ đề cập đến lược đồ quan hệ.
-
Thuộc tính A có thể đủ điều kiện với tên quan hệ R mà nó thuộc về bằng cách sử dụng ký hiệu dấu chấm R.A — ví dụ, STUDENT.Name hoặc STUDENT.Age. Điều này là do cùng một tên có thể được sử dụng cho hai phụ tùng trong các quan hệ khác nhau. Tuy nhiên, tất cả các tên thuộc tính trong một quan hệ cụ thể phải khác biệt (tên các thuộc tính không được phép đặt trùng nhau)
-
Một n-tuple t trong quan hệ r (R) được ký hiệu là t =, trong đó vi là giá trị tương ứng với thuộc tính Ai. Ký hiệu sau đề cập đến các giá trị thành phần của các bộ giá trị:
-
Cả t [Ai] và t.Ai (và đôi khi t [i]) đề cập đến giá trị vi trong t đối với attribute Ai
-
Cả t [Au, Aw,…, Az] và t. (Au, Aw,…, Az), trong đó Au, Aw,…, Az là danh sách các thuộc tính từ R, tham chiếu đến nhóm con của các giá trị <vu, vw ,…, Vz> từ t tương ứng với các thuộc tính được chỉ định trong danh sách
Ví dụ, hãy xem xét tuple t = <'Barbara Benson', '533-69-1238', '(817) 839-8461', '7384 Fontana Lane', NULL, 19, 3,25> từ quan hệ STUDENT trong Hình urê 5,1; chúng ta có t [Name] = <‘Barbara Benson’> và t [Ssn, Gpa, Age] = <‘533-69-1238’, 3,25, 19>.
2. Ràng buộc mô hình quan hệ và lược đồ cơ sở dữ liệu quan hệ
Cho đến nay, chúng ta đã thảo luận về các đặc điểm của quan hệ đơn lẻ. Trong cơ sở dữ liệu quan hệ, thường sẽ có nhiều quan hệ và các bộ giá trị trong các quan hệ đó thường liên quan theo nhiều cách khác nhau. Trạng thái của toàn bộ cơ sở dữ liệu sẽ tương ứng với trạng thái của tất cả các quan hệ của nó tại một thời điểm cụ thể. Nói chung có nhiều hạn chế hoặc ràng buộc đối với các giá trị thực trong trạng thái cơ sở dữ liệu. Những ràng buộc này có nguồn gốc từ các quy tắc trong thế giới nhỏ mà cơ sở dữ liệu đại diện, như chúng ta đã đề cập trong phần trước
Trong phần này, chúng ta thảo luận về các hạn chế khác nhau đối với dữ liệu có thể được chỉ định trên cơ sở dữ liệu quan hệ ở dạng ràng buộc. Các ràng buộc trên cơ sở dữ liệu có thể được chia thành ba loại chính
-
Các ràng buộc vốn có trong mô hình dữ liệu. Chúng tôi gọi đây là những ràng buộc dựa trên mô hình cố hữu hoặc những ràng buộc ngầm định.
-
Các ràng buộc có thể được thể hiện trực tiếp trong các lược đồ của mô hình dữ liệu, đánh máy bằng cách chỉ định chúng trong DDL (ngôn ngữ định nghĩa dữ liệu). Chúng tôi gọi đây là những ràng buộc dựa trên lược đồ hoặc những ràng buộc rõ ràng
-
Các ràng buộc không thể được thể hiện trực tiếp trong các lược đồ của mô hình dữ liệu và do đó phải được trình bày và thực thi bởi ứng dụng chuyên nghiệp hoặc theo một số cách khác. Chúng tôi gọi đây là các ràng buộc dựa trên ứng dụng hoặc ngữ nghĩa hoặc các ràng buộc liên quan đến nghiệp vụ sản xuất hoặc kinh doanh
Các đặc điểm của quan hệ mà chúng ta đã thảo luận trong phần trước là những ràng buộc cố hữu của mô hình quan hệ và thuộc loại đầu tiên. Ví dụ, ràng buộc mà một quan hệ không thể có các bộ giá trị trùng lặp là một ràng buộc cố hữu. Các ràng buộc mà chúng ta thảo luận trong phần này thuộc loại thứ hai, cụ thể là, các ràng buộc có thể được thể hiện trong lược đồ của mô hình quan hệ thông qua DDL. Các ràng buộc trong loại thứ ba thường tổng quát hơn, liên quan đến ý nghĩa cũng như hành vi của các thuộc tính và khó thể hiện và thực thi trong mô hình dữ liệu, vì vậy chúng thường được kiểm tra trong các chương trình ứng dụng thực hiện cập nhật cơ sở dữ liệu. Trong một số trường hợp, những ràng buộc này có thể được chỉ định dưới dạng xác nhận trong SQL
Một loại ràng buộc quan trọng khác là phụ thuộc dữ liệu, bao gồm phụ thuộc hàm và phụ thuộc đa giá trị. Chúng được sử dụng chủ yếu để kiểm tra "tính tốt" của thiết kế cơ sở dữ liệu quan hệ và được sử dụng trong một quá trình gọi là chuẩn hóa, sẽ được thảo luận sau
Các ràng buộc dựa trên lược đồ bao gồm các ràng buộc miền, các ràng buộc khóa, các ràng buộc về NULL, các ràng buộc toàn vẹn thực thể và các ràng buộc toàn vẹn tham chiếu
2.1 Ràng buộc miền
Các ràng buộc miền chỉ định rằng trong mỗi bộ giá trị, giá trị của mỗi thuộc tính A phải là một giá trị nguyên tử từ miền dom (A). Chúng ta đã thảo luận về các cách mà các miền có thể được chỉ định trong phần trước. Các kiểu dữ liệu được liên kết với miền thường bao gồm các kiểu dữ liệu số chuẩn cho số nguyên (chẳng hạn như số nguyên ngắn, số nguyên và số nguyên dài) và số thực (float và double). Các ký tự, Boolean, chuỗi có độ dài cố định và chuỗi có độ dài thay đổi cũng có thể sử dụng được, cũng như ngày, giờ, dấu thời gian và các kiểu dữ liệu đặc biệt khác. Miền cũng có thể được mô tả bằng một dải con các giá trị từ một kiểu dữ liệu hoặc dưới dạng một kiểu dữ liệu liệt kê trong đó tất cả các giá trị có thể được liệt kê một cách rõ ràng. Thay vì mô tả chi tiết những điều này ở đây, chúng tôi thảo luận về các kiểu dữ liệu được cung cấp bởi tiêu chuẩn quan hệ SQL trong phần sau
2.2 Các ràng buộc về khóa và ràng buộc đối với các giá trị NULL
Trong mô hình quan hệ chính thức, một quan hệ được định nghĩa là một tập hợp các bộ giá trị. Theo định nghĩa, tất cả các phần tử của một tập hợp là khác biệt; do đó, tất cả các bộ giá trị trong một mối quan hệ cũng phải khác biệt. Điều này có nghĩa là không có hai bộ giá trị nào có thể có cùng một tổ hợp giá trị cho tất cả các thuộc tính của chúng. Thông thường, có các tập con khác của các thuộc tính của một lược đồ quan hệ R với thuộc tính mà không có hai bộ giá trị nào trong bất kỳ trạng thái quan hệ nào của R phải có cùng một tổ hợp giá trị cho các thuộc tính này. Giả sử rằng chúng ta biểu thị một tập con các thuộc tính như vậy bằng SK; thì đối với bất kỳ hai bộ giá trị phân biệt t1 và t2 nào trong một trạng thái quan hệ r của R, chúng ta có ràng buộc rằng:
t1[SK] ≠ t2[SK]
Bất kỳ tập hợp thuộc tính nào SK như vậy được gọi là siêu khóa của lược đồ quan hệ R. Một siêu khóa SK xác định ràng buộc tính duy nhất mà không có hai bộ giá trị phân biệt nào ở bất kỳ trạng thái r nào của R có thể có cùng giá trị cho SK. Mọi quan hệ đều có ít nhất một siêu khóa mặc định— tập hợp tất cả các thuộc tính của nó. Tuy nhiên, một siêu khóa có thể có các thuộc tính dư thừa, do đó, một khái niệm hữu ích hơn là một khóa không có dư thừa. Khóa k của lược đồ quan hệ R là siêu khóa của R với thuộc tính bổ sung là loại bỏ bất kỳ phần tử nào A khỏi K sẽ để lại tập hợp các thuộc tính K ′ không phải là siêu khóa của R nữa. Do đó, một khóa thỏa mãn hai thuộc tính:
-
Hai bộ giá trị riêng biệt trong bất kỳ trạng thái nào của mối quan hệ không thể có các giá trị giống nhau cho (tất cả) các thuộc tính trong khóa. Thuộc tính duy nhất này cũng áp dụng cho superkey
-
Nó là một superkey tối thiểu — nghĩa là, một superkey mà từ đó chúng ta không thể loại bỏ bất kỳ thuộc tính nào và vẫn có giới hạn về tính duy nhất. Thuộc tính tối thiểu này là bắt buộc đối với khóa nhưng là tùy chọn đối với siêu khóa.
Do đó, một khóa là một siêu khóa nhưng không có phát biểu ngược lại. Một superkey có thể là một khóa (nếu nó là tối thiểu) hoặc có thể không phải là một chìa khóa (nếu nó không phải là tối thiểu). Xem xét mối quan hệ STUDENT của Hình 5.1. Tập thuộc tính {Ssn} là một khóa của STUDENT vì không có hai bộ giá trị sinh viên nào có thể có cùng giá trị đối với Ssn. Bất kỳ tập hợp thuộc tính nào bao gồm Ssn — ví dụ: {Ssn, Name, Age} —là siêu khóa. Tuy nhiên, siêu khóa {Ssn, Name, Age} không phải là khóa của STUDENT vì xóa Tên hoặc Tuổi hoặc cả hai khỏi tập hợp vẫn để lại cho chúng ta một siêu khóa. Nói chung, bất kỳ siêu khóa nào được hình thành từ một thuộc tính duy nhất cũng là một khóa. Một khóa có nhiều thuộc tính phải yêu cầu tất cả các thuộc tính của nó cùng nhau để có thuộc tính duy nhất.
Giá trị của một thuộc tính khóa có thể được sử dụng để xác định duy nhất từng bộ giá trị trong một quan hệ. Ví dụ, giá trị Ssn 305-61-2435 xác định duy nhất bộ giá trị tương ứng với Benjamin Bayer trong quan hệ STUDENT. Lưu ý rằng một tập hợp các thuộc tính cấu thành một khóa là một thuộc tính của lược đồ quan hệ; nó là một ràng buộc nên giữ mọi trạng thái quan hệ hợp lệ của lược đồ. Một khóa được xác định từ ý nghĩa của các thuộc tính và thuộc tính bất biến theo thời gian: Nó phải tiếp tục giữ khi chúng ta chèn các bộ giá trị mới vào quan hệ. Ví dụ, chúng ta không thể và không nên chỉ định thuộc tính Name của quan hệ STUDENT trong Hình 5.1 làm khóa vì có thể hai sinh viên trùng tên sẽ tồn tại tại một thời điểm nào đó ở trạng thái hợp lệ.
Nói chung, một lược đồ quan hệ có thể có nhiều hơn một khóa. Trong trường hợp này, mỗi khóa được gọi là khóa dự bị. Ví dụ, quan hệ CAR trong Hình 5.4 có hai khóa dự bị: License_number và Engine_serial_number. Người ta thường chỉ định một trong các khóa ứng viên làm khóa chính của quan hệ. Đây là khóa ứng viên có các giá trị được sử dụng để xác định các bộ giá trị trong mối quan hệ. Chúng tôi sử dụng quy ước rằng các thuộc tính tạo thành khóa chính của một lược đồ quan hệ được gạch dưới, như thể hiện trong Hình 5.4. Lưu ý rằng khi một lược đồ quan hệ có một số khóa ứng viên, việc lựa chọn một khóa để trở thành khóa chính hơi tùy ý; tuy nhiên, thường tốt hơn nếu chọn khóa chính có một thuộc tính đơn lẻ hoặc một số ít thuộc tính. Các khóa dự phòng khác được chỉ định là khóa duy nhất và không được gạch chân
Một ràng buộc khác về các thuộc tính là các giá trị NULL có hay không được phép. Ví dụ: nếu mọi bộ giá trị STUDENT phải có giá trị hợp lệ, không phải NULL cho thuộc tính Name, thì Name of STUDENT bị ràng buộc là NOT NULL.
2.3 Cơ sở dữ liệu quan hệ và lược đồ cơ sở dữ liệu quan hệ
Các định nghĩa và ràng buộc mà chúng ta đã thảo luận cho đến nay áp dụng cho các quan hệ đơn lẻ và các thuộc tính của chúng. Một cơ sở dữ liệu quan hệ thường chứa nhiều quan hệ, với các bộ giá trị trong quan hệ có liên quan theo nhiều cách khác nhau. Trong phần này, chúng tôi xác định một cơ sở dữ liệu quan hệ và một lược đồ cơ sở dữ liệu quan hệ
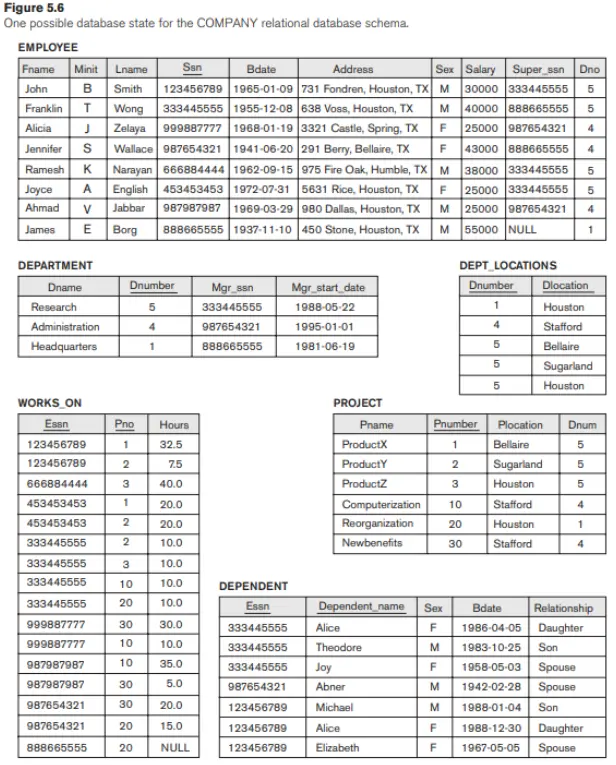
Một lược đồ cơ sở dữ liệu quan hệ S là một tập hợp các lược đồ quan hệ S = {R1, R2,…, Rm} và một tập hợp các ràng buộc toàn vẹn IC. Trạng thái cơ sở dữ liệu quan hệ DB của S là một tập hợp các trạng thái quan hệ DB = {r1, r2,…, rm} sao cho mỗi ri là một trạng thái của Ri và sao cho các trạng thái quan hệ ri thỏa mãn các ràng buộc toàn vẹn được chỉ định trong IC. Hình 5.5 cho thấy một lược đồ cơ sở dữ liệu quan hệ mà chúng ta gọi là COMPANY = {EMPLOYEE, DEPARTMENT, DEPT_LOCATIONS, PROJECT, WORKS_ON, DEPENDENT}. Trong mỗi lược đồ quan hệ, thuộc tính được gạch dưới đại diện cho khóa chính. Hình 5.6 cho thấy một trạng thái cơ sở dữ liệu quan hệ tương ứng với lược đồ COMPANY. Chúng tôi sẽ sử dụng lược đồ và trạng thái cơ sở dữ liệu này trong chương này và trong các phần sau để phát triển các truy vấn mẫu bằng các ngôn ngữ quan hệ khác nhau. (Dữ liệu hiển thị ở đây được mở rộng và có sẵn để tải dưới dạng cơ sở dữ liệu phổ biến từ internet và có thể được sử dụng cho các bài tập dự án thực hành.)
Khi chúng ta tham chiếu đến cơ sở dữ liệu quan hệ, chúng ta hoàn toàn bao gồm cả lược đồ và trạng thái hiện tại của nó. Trạng thái cơ sở dữ liệu không tuân theo tất cả các ràng buộc toàn vẹn được gọi là không hợp lệ và trạng thái thỏa mãn tất cả các ràng buộc trong tập hợp các ràng buộc toàn vẹn đã xác định IC được gọi là trạng thái hợp lệ

Trong Hình 5.5, thuộc tính Dnumber trong cả DEPARTMENT và DEPT_LOCATIONS là viết tắt của cùng một khái niệm trong thế giới thực — số được cấp cho một bộ phận. Khái niệm tương tự đó được gọi là Dno trong EMPLOYEE và Dnum trong PROJECT. Các thuộc tính đại diện cho cùng một khái niệm trong thế giới thực có thể có hoặc không có tên giống nhau trong các quan hệ khác nhau. Ngoài ra, các thuộc tính đại diện cho các khái niệm khác nhau có thể có cùng tên trong các quan hệ khác nhau. Ví dụ, chúng ta có thể sử dụng tên thuộc tính Name cho cả Name của PROJECT và Name của DEPARTMENT; trong trường hợp này, chúng ta sẽ có hai thuộc tính có cùng tên nhưng đại diện cho các khái niệm thế giới thực khác nhau — tên dự án và tên bộ phận.
Trong một số phiên bản đầu tiên của mô hình quan hệ, một giả định đã được đặt ra rằng cùng một khái niệm trong thế giới thực, khi được biểu diễn bằng một thuộc tính, sẽ có tên thuộc tính giống nhau trong tất cả các quan hệ. Điều này tạo ra vấn đề khi cùng một khái niệm thế giới thực được sử dụng với các vai trò (ý nghĩa) khác nhau trong cùng một mối quan hệ. Ví dụ: khái niệm số An sinh xã hội xuất hiện hai lần trong quan hệ NHÂN VIÊN của Hình 5.5: một lần trong vai trò SSN của nhân viên và một lần trong vai trò SSN của người giám sát. Chúng tôi bắt buộc phải đặt cho chúng các tên thuộc tính riêng biệt — tương ứng là Ssn và Super_ssn — vì chúng xuất hiện trong cùng một mối quan hệ và để phân biệt ý nghĩa của chúng.
Mỗi DBMS quan hệ phải có một ngôn ngữ định nghĩa dữ liệu (DDL) để xác định một lược đồ cơ sở dữ liệu quan hệ. Các DBMS quan hệ hiện tại chủ yếu sử dụng SQL cho mục đích này. Chúng tôi trình bày SQL DDL trong phần sau
Các ràng buộc về tính toàn vẹn được chỉ định trên một lược đồ cơ sở dữ liệu và dự kiến sẽ giữ trên mọi trạng thái cơ sở dữ liệu hợp lệ của lược đồ đó. Ngoài các ràng buộc miền, khóa và NOT NULL, hai loại ràng buộc khác được coi là một phần của mô hình quan hệ: toàn vẹn thực thể và toàn vẹn tham chiếu.
2.4 Tính toàn vẹn của thực thể, tính toàn vẹn tham chiếu và khóa ngoại
Ràng buộc toàn vẹn thực thể tuyên bố rằng không có giá trị khóa chính nào có thể là NULL. Điều này là do giá trị khóa chính được sử dụng để xác định các bộ giá trị riêng lẻ trong một mối quan hệ. Việc nhập các giá trị NULL cho khóa chính ngụ ý rằng chúng tôi không thể xác định một số bộ giá trị. Ví dụ: nếu hai hoặc nhiều bộ dữ liệu có NULL cho khóa chính của chúng, chúng tôi có thể không phân biệt được chúng nếu chúng tôi cố gắng tham chiếu chúng từ các quan hệ khác.
Các ràng buộc chính và ràng buộc toàn vẹn thực thể được chỉ định trên các quan hệ riêng lẻ. Ràng buộc toàn vẹn tham chiếu được chỉ định giữa hai quan hệ và được sử dụng để duy trì tính nhất quán giữa các bộ giá trị trong hai quan hệ. Về mặt không chính thức, ràng buộc toàn vẹn tham chiếu nói rằng một bộ trong một quan hệ tham chiếu đến một quan hệ khác phải tham chiếu đến một bộ hiện có trong quan hệ đó. Ví dụ, trong Hình 5.6, thuộc tính Dno của EMPLOYEE cho biết số bộ phận mà mỗi nhân viên làm việc; do đó, giá trị của nó trong mọi bộ EMPLOYEE phải khớp với giá trị Dnumber của một số bộ trong quan hệ DEPARTMENT.
Để định nghĩa tính toàn vẹn tham chiếu một cách chính thức hơn, trước tiên chúng ta định nghĩa khái niệm khóa ngoại. Các điều kiện cho khóa ngoại, được đưa ra dưới đây, chỉ định ràng buộc toàn vẹn tham chiếu giữa hai lược đồ quan hệ R1 và R2. Tập hợp các thuộc tính FK trong lược đồ quan hệ R1 là một khóa ngoại của R1 tham chiếu đến quan hệ R2 nếu nó thỏa mãn các quy tắc sau:
-
Các thuộc tính trong FK có cùng (các) miền với các thuộc tính khóa chính PK của R2; các thuộc tính FK được cho là tham chiếu hoặc tham chiếu đến quan hệ R2.
-
Giá trị FK trong bộ t1 của trạng thái hiện tại r1 (R1) hoặc xảy ra dưới dạng giá trị của PK đối với một số bộ t2 ở trạng thái hiện tại r2 (R2) hoặc là NULL. Trong trường hợp trước, chúng ta có t1 [FK] = t2 [PK], và chúng ta nói rằng tuple t1 tham chiếu hoặc tham chiếu đến tuple t2.
Trong định nghĩa này, R1 được gọi là quan hệ tham chiếu và R2 là quan hệ được tham chiếu. Nếu hai điều kiện này giữ nguyên, một ràng buộc toàn vẹn tham chiếu từ R1 đến R2 được cho là giữ nguyên. Trong cơ sở dữ liệu gồm nhiều quan hệ, thường có nhiều ràng buộc toàn vẹn tham chiếu.
Để xác định các ràng buộc này, trước tiên chúng ta phải hiểu rõ ràng về vai trò hoặc giá trị trung bình mà mỗi thuộc tính hoặc tập hợp các thuộc tính đóng trong các lược đồ quan hệ khác nhau của cơ sở dữ liệu. Các ràng buộc toàn vẹn tham chiếu thường phát sinh từ các mối quan hệ giữa các thực thể được biểu diễn bằng các lược đồ quan hệ. Ví dụ, hãy xem xét cơ sở dữ liệu được hiển thị trong Hình 5.6. Trong quan hệ EMPLOYEE, thuộc tính Dno đề cập đến bộ phận mà nhân viên làm việc; do đó, chúng tôi chỉ định Dno là khóa ngoại của EMPLOYEE tham chiếu đến quan hệ DEPARTMENT. Điều này có nghĩa là giá trị của Dno trong bất kỳ tuple t1 nào của quan hệ EMPLOYEE phải khớp với giá trị của khóa chính của DEPARTMENT — thuộc tính Dnumber — trong một số tuple t2 của quan hệ DEPARTMENT hoặc giá trị của Dno có thể là NULL nếu nhân viên không thuộc sở hoặc sau này sẽ được phân công về phòng. Ví dụ, trong Hình 5.6, bộ tuple cho nhân viên ‘John Smith’ tham chiếu đến bộ tuple cho bộ phận ‘Nghiên cứu’, cho biết rằng bộ phận ‘John Smith’ làm việc cho bộ phận này.
Lưu ý rằng một khóa ngoại có thể tham chiếu đến quan hệ của chính nó. Ví dụ, thuộc tính Super_ssn trong EMPLOYEE đề cập đến người giám sát của một nhân viên; đây là một nhân viên khác, được đại diện bởi một bộ trong quan hệ NHÂN VIÊN. Do đó, Super_ssn là một khóa ngoại tham chiếu đến chính quan hệ EMPLOYEE. Trong Hình 5.6, tuple cho nhân viên ‘John Smith’ tham chiếu đến tuple cho nhân viên ‘Franklin Wong’, chỉ ra rằng ‘Franklin Wong’ là người giám sát của ‘John Smith’.
Chúng ta có thể hiển thị theo sơ đồ các ràng buộc toàn vẹn tham chiếu bằng cách vẽ một vòng cung có hướng từ mỗi khóa ngoại đến mối quan hệ mà nó tham chiếu. Để rõ ràng, đầu mũi tên có thể trỏ đến khóa chính của quan hệ được tham chiếu. Hình 5.7 cho thấy lược đồ trong Hình 5.5 với các ràng buộc toàn vẹn tham chiếu được hiển thị theo cách này
.webp)
Tất cả các ràng buộc toàn vẹn nên được chỉ định trên lược đồ cơ sở dữ liệu quan hệ (nghĩa là, được chỉ định như một phần của định nghĩa của nó) nếu chúng ta muốn DBMS thực thi các ràng buộc này trên các trạng thái cơ sở dữ liệu. Do đó, DDL bao gồm các điều khoản để chỉ định các loại ràng buộc khác nhau để DBMS có thể tự động thực thi chúng. Trong SQL, câu lệnh CREATE TABLE của SQL DDL cho phép định nghĩa khóa chính, khóa duy nhất, NOT NULL, toàn vẹn thực thể và các ràng buộc toàn vẹn tham chiếu, trong số các ràng buộc khác
2.5 Các loại ràng buộc khác
Các ràng buộc toàn vẹn trước đó được đưa vào ngôn ngữ định nghĩa dữ liệu vì chúng xuất hiện trong hầu hết các ứng dụng cơ sở dữ liệu. Một lớp khác của các ràng buộc chung, đôi khi được gọi là ràng buộc toàn vẹn ngữ nghĩa, không phải là một phần của DDL và phải được chỉ định và thực thi theo một cách khác. Ví dụ về những ràng buộc như vậy là tiền lương của một nhân viên không được vượt quá mức lương của người giám sát nhân viên và số giờ tối đa mà một nhân viên có thể làm việc cho tất cả các dự án mỗi tuần là 56. Những ràng buộc như vậy có thể được quy định và thực thi trong các chương trình ứng dụng cập nhật cơ sở dữ liệu hoặc bằng cách sử dụng ngôn ngữ đặc tả ràng buộc có mục đích chung. Các cơ chế được gọi là trình kích hoạt và xác nhận có thể được sử dụng trong SQL, thông qua các câu lệnh CREATE ASSERTION và CREATE TRIGGER, để chỉ định một số ràng buộc này. Thông thường, việc kiểm tra các loại ràng buộc này trong các chương trình ứng dụng hơn là sử dụng các ngôn ngữ cation đặc tả ràng buộc vì ngôn ngữ này đôi khi khó sử dụng và phức tạp, như chúng ta sẽ thảo luận ở phần sau
Các loại ràng buộc mà chúng ta đã thảo luận cho đến nay có thể được gọi là ràng buộc trạng thái bởi vì chúng xác định các ràng buộc mà trạng thái hợp lệ của cơ sở dữ liệu phải thỏa mãn. Một loại ràng buộc khác, được gọi là ràng buộc chuyển tiếp, có thể được định nghĩa để đối phó với những thay đổi trạng thái trong cơ sở dữ liệu. Một ví dụ về ràng buộc chuyển đổi là: “lương của một nhân viên chỉ có thể tăng lên”. Những ràng buộc như vậy thường được thực thi bởi các chương trình ứng dụng hoặc được chỉ định bằng cách sử dụng các quy tắc và trình kích hoạt đang hoạt động, như chúng ta sẽ thảo luận ở phần sau
3. Các hoạt động cập nhật dữ liệu, xử lý giao dịch và xử lý vi phạm ràng buộc
Các hoạt động của mô hình quan hệ có thể được phân loại thành các truy xuất và cập nhật. Các phép toán đại số quan hệ, có thể được sử dụng để chỉ định các truy xuất, được thảo luận chi tiết trong phần sau liên quan đến SQL. Một biểu thức đại số quan hệ tạo thành một quan hệ mới sau khi áp dụng một số toán tử đại số vào một tập hợp các quan hệ hiện có; công dụng chính của nó là truy vấn cơ sở dữ liệu để lấy thông tin. Người dùng để mô phỏng một truy vấn chỉ định dữ liệu quan tâm và một quan hệ mới được hình thành bằng cách áp dụng các toán tử quan hệ để truy xuất dữ liệu này. Quan hệ kết quả trở thành câu trả lời cho (hoặc kết quả của) truy vấn của người dùng. Nội dung bài SQL cũng giới thiệu ngôn ngữ được gọi là phép tính quan hệ, được sử dụng để định nghĩa một truy vấn một cách khai báo mà không đưa ra một thứ tự hoạt động cụ thể
Trong phần này, chúng tôi tập trung vào các hoạt động sửa đổi hoặc cập nhật cơ sở dữ liệu. Có ba thao tác cơ bản có thể thay đổi trạng thái của các quan hệ trong cơ sở dữ liệu: Insert, Delete và Update (hoặc Modify). Chúng chèn dữ liệu mới, xóa dữ liệu cũ hoặc sửa đổi các bản ghi dữ liệu hiện có, tương ứng. Insert được sử dụng để chèn một hoặc nhiều bộ giá trị mới trong một quan hệ, Delete được sử dụng để xóa các bộ giá trị và Update (hoặc Modify) được sử dụng để thay đổi giá trị của một số thuộc tính trong các bộ giá trị hiện có. Bất cứ khi nào các hoạt động này được áp dụng, các ràng buộc toàn vẹn được chỉ định trên lược đồ cơ sở dữ liệu quan hệ sẽ không bị vi phạm. Trong phần này, chúng tôi thảo luận về các loại ràng buộc có thể bị vi phạm bởi mỗi hoạt động này và các loại hành động có thể được thực hiện nếu một hoạt động gây ra vi phạm. Chúng tôi sử dụng cơ sở dữ liệu được hiển thị trong Hình 5.6 để làm ví dụ và chỉ thảo luận về các ràng buộc miền, các ràng buộc khóa, các ràng buộc toàn vẹn thực thể và các ràng buộc toàn vẹn tham chiếu được hiển thị trong Hình 5.7. Đối với mỗi loại hoạt động, chúng tôi đưa ra một số ví dụ và thảo luận về bất kỳ ràng buộc nào mà mỗi hoạt động có thể vi phạm.
3.1 Thao tác insert
Thao tác Insert cung cấp danh sách các giá trị thuộc tính cho một tuple t mới sẽ được chèn vào một quan hệ R. Chèn có thể vi phạm bất kỳ loại ràng buộc nào trong bốn loại ràng buộc. Ràng buộc miền có thể bị vi phạm nếu một giá trị thuộc tính được cung cấp không xuất hiện trong miền tương ứng hoặc không thuộc kiểu dữ liệu thích hợp. Các ràng buộc khóa có thể bị vi phạm nếu một giá trị khóa trong bộ mới t đã tồn tại trong bộ khác trong quan hệ r (R). Tính toàn vẹn của thực thể có thể bị vi phạm nếu bất kỳ phần nào của khóa chính của bộ t mới là NULL. Tính toàn vẹn tham chiếu có thể bị vi phạm nếu giá trị của bất kỳ khóa ngoại nào trong t tham chiếu đến một bộ giá trị không tồn tại trong quan hệ được tham chiếu. Dưới đây là một số ví dụ để minh họa cho cuộc thảo luận này.
-
Operation: Insert into EMPLOYEE <‘Cecilia’, ‘F’, ‘Kolonsky’, NULL, ‘1960-04-05’, ‘6357 Windy Lane, Katy, TX’, F, 28000, NULL, 4> Kết quả: This insertion violates the entity integrity constraint (NULL for the primary key Ssn), trường hợp này khóa chính của bạn đặt giá trị NULL câu lệnh khi thực thi sẽ báo lỗi
-
Operation: Insert into EMPLOYEE <‘Alicia’, ‘J’, ‘Zelaya’, ‘999887777’, ‘1960-04-05’, ‘6357 Windy Lane, Katy, TX’, F, 28000, ‘987654321’, 4>. Result: This insertion violates the key constraint because another tuple with the same Ssn value already exists in the EMPLOYEE relation. Trường hợp này ràng về tính duy nhất của khóa chính không được đáp ứng vì thế khi thực thi câu lệnh báo lỗi và bị loại bỏ.
-
Operation: Insert into EMPLOYEE <‘Cecilia’, ‘F’, ‘Kolonsky’, ‘677678989’, ‘1960-04-05’, ‘6357 Windswept, Katy, TX’, F, 28000, ‘987654321’, 7>. Kết quả: Việc chèn này vi phạm ràng buộc toàn vẹn tham chiếu được chỉ định trên Dno trong EMPLOYEE vì không có bộ tham chiếu tương ứng nào tồn tại trong DEPARTMENT với Dnumber = 7.
-
Operation: Insert into EMPLOYEE <‘Cecilia’, ‘F’, ‘Kolonsky’, ‘677678989’, ‘1960-04-05’, ‘6357 Windy Lane, Katy, TX’, F, 28000, NULL, 4> . Kết quả: Việc chèn này thỏa mãn tất cả các ràng buộc nên có thể chấp nhận được.
Nếu một thao tác insert vi phạm một hoặc nhiều ràng buộc, hệ quản trị cơ sở dữ liệu tùy chọn mặc định là từ chối phần chèn. Trong trường hợp này, sẽ hữu ích nếu DBMS có thể cung cấp lý do cho người dùng về lý do tại sao việc insert bị từ chối. Một tùy chọn khác là cố gắng sửa lý do từ chối việc insert, nhưng điều này thường không được sử dụng cho các vi phạm do Insert gây ra; thay vào đó, nó được sử dụng thường xuyên hơn trong việc sửa chữa các vi phạm đối với Delete và Update. Trong hoạt động đầu tiên, DBMS có thể yêu cầu người dùng cung cấp một giá trị cho Ssn và sau đó có thể chấp nhận việc chèn nếu một giá trị Ssn hợp lệ được cung cấp. Trong operation 3 theo ví dụ trên, DBMS có thể yêu cầu người dùng thay đổi giá trị của Dno thành một giá trị hợp lệ nào đó (hoặc đặt nó thành NULL) hoặc nó có thể yêu cầu người dùng chèn một bộ mã DEPARTMENT với Dnumber = 7 và có thể chấp nhận việc chèn ban đầu chỉ sau khi một hoạt động như vậy được chấp nhận. Lưu ý rằng trong trường hợp thứ hai, vi phạm chèn có thể chuyển ngược trở lại quan hệ EMPLOYEE nếu người dùng cố gắng chèn một bộ tuple cho bộ phận 7 với giá trị cho Mgr_ssn không tồn tại trong quan hệ EMPLOYEE
3.2 Thao tác Delete
Thao tác Delete chỉ có thể vi phạm tính toàn vẹn tham chiếu. Điều này xảy ra nếu bộ đang bị xóa được tham chiếu bởi các khóa ngoại từ các bộ khác trong cơ sở dữ liệu. Để chỉ định xóa, một điều kiện trên các thuộc tính của quan hệ chọn bộ (hoặc bộ) để xóa. Dưới đây là một số ví dụ.
-
Thao tác: Xóa bộ WORKS_ON với Essn = ‘999887777’ và Pno = 10. Kết quả: Việc xóa này có thể chấp nhận được và xóa đúng một bộ.
-
Thao tác: Xóa tuple EMPLOYEE với Ssn = ‘999887777’. Kết quả: Việc xóa này không được chấp nhận vì có các bộ giá trị trong WORKS_ON tham chiếu đến bộ giá trị này. Do đó, nếu bộ tuple trong EMPLOYEE bị xóa, vi phạm tính toàn vẹn tham chiếu
-
Thao tác: Xóa tuple EMPLOYEE với Ssn = ‘333445555’. Kết quả: Việc xóa này sẽ dẫn đến vi phạm tính toàn vẹn tham chiếu thậm chí còn tồi tệ hơn, bởi vì bộ liên quan được tham chiếu bởi các bộ từ quan hệ EMPLOYEE, DEPARTMENT, WORKS_ON và DEPENDENT
Một số tùy chọn có sẵn nếu thao tác xóa gây ra vi phạm. Tùy chọn đầu tiên, được gọi là hạn chế, là từ chối việc xóa. Tùy chọn thứ hai, được gọi là cascade, là cố gắng phân tầng (hoặc truyền bá) việc xóa bằng cách xóa các bộ tham chiếu đến bộ đang bị xóa. Ví dụ, trong operation ở hoạt động 2, DBMS có thể tự động xóa các bộ vi phạm khỏi WORKS_ON với Essn = ‘999887777’. Tùy chọn thứ ba, được gọi là đặt null hoặc đặt mặc định, là sửa đổi các giá trị thuộc tính tham chiếu gây ra vi phạm; mỗi giá trị như vậy được đặt thành NULL hoặc được thay đổi để tham chiếu đến một bộ giá trị hợp lệ mặc định khác. Lưu ý rằng nếu một thuộc tính tham chiếu gây ra vi phạm là một phần của khóa chính, nó không thể được đặt thành NULL; nếu không, nó sẽ vi phạm tính toàn vẹn của thực thể.
Cũng có thể kết hợp ba tùy chọn này. Ví dụ: để tránh hoạt động 3 gây ra vi phạm, DBMS có thể tự động xóa tất cả các bộ giá trị khỏi WORKS_ON và DEPENDENT với Essn = ‘333445555’. Các bộ trong EMPLOYEE với Super_ssn = ‘333445555’ và bộ trong DEPARTMENT với Mgr_ssn = ‘333445555’ có thể thay đổi giá trị Super_ssn và Mgr_ssn thành các giá trị hợp lệ khác hoặc thành NULL. Mặc dù việc tự động xóa các bộ WORKS_ON và DEPENDENT tham chiếu đến bộ EMPLOYEE có thể có ý nghĩa, nhưng việc xóa các bộ EMPLOYEE khác hoặc bộ DEPARTMENT có thể không hợp lý.
Nói chung, khi một ràng buộc toàn vẹn tham chiếu được chỉ định trong DDL, DBMS sẽ cho phép người thiết kế cơ sở dữ liệu chỉ định tùy chọn nào được áp dụng trong trường hợp vi phạm ràng buộc. Chúng tôi thảo luận về cách chỉ định các tùy chọn này trong SQL DDL
3.3 Thao tác Update (Modify)
Thao tác Cập nhật (hoặc Sửa đổi) được sử dụng để thay đổi giá trị của một hoặc nhiều thuộc tính trong một bộ (hoặc các bộ) của một số quan hệ R. Cần phải chỉ định một điều kiện trên các thuộc tính của quan hệ để chọn bộ (hoặc bộ ) được sửa đổi. Dưới đây là một số ví dụ.
-
Thao tác: Cập nhật lương của EMPLOYEE với Ssn = ‘999887777’ thành 28000. Kết quả: Chấp nhận được.
-
Thao tác: Cập nhật Dno của EMPLOYEE với Ssn = ‘999887777’ thành 1. Kết quả: Chấp nhận được.
-
Thao tác: Cập nhật Dno của tuple EMPLOYEE với Ssn = ‘999887777’ thành 7. Kết quả: Không thể chấp nhận được, vì nó vi phạm tính toàn vẹn tham chiếu.
-
Thao tác: Cập nhật Ssn của bộ tuple EMPLOYEE với Ssn = ‘999887777’ thành ‘987654321’. Kết quả: Không thể chấp nhận được, vì nó vi phạm ràng buộc khóa chính bằng cách lặp lại một giá trị đã tồn tại làm khóa chính trong một bộ giá trị khác; nó vi phạm các ràng buộc toàn vẹn tham chiếu bởi vì có các quan hệ khác tham chiếu đến giá trị hiện có của Ssn.
Cập nhật một thuộc tính không phải là một phần của khóa chính hoặc một phần của khóa ngoại thường không gây ra vấn đề gì; DBMS chỉ cần kiểm tra để xác nhận rằng giá trị mới thuộc kiểu dữ liệu và miền trị chính xác hay không. Việc sửa đổi giá trị khóa chính giống như việc xóa một bộ giá trị và chèn một bộ khác vào vị trí của nó vì chúng tôi sử dụng khóa ngoại để xác định các bộ giá trị. Do đó, các vấn đề được thảo luận trước đó trong cả Phần 3.1 (Insert) và 3.2 (Delete) sẽ phát huy tác dụng. Nếu một thuộc tính khóa ngoại được sửa đổi, DBMS phải đảm bảo rằng giá trị mới tham chiếu đến một bộ giá trị hiện có trong quan hệ tham chiếu (hoặc được đặt thành NULL). Các tùy chọn tương tự tồn tại để đối phó với các vi phạm tích phân tham chiếu do Cập nhật gây ra khi các tùy chọn đó được thảo luận cho hoạt động Delete. Trên thực tế, khi một ràng buộc toàn vẹn tham chiếu được chỉ định trong DDL, DBMS sẽ cho phép người dùng chọn các tùy chọn riêng biệt để đối phó với vi phạm do Delete và vi phạm do Cập nhật gây ra.
3.4 Khái niệm về giao dịch
Một chương trình ứng dụng cơ sở dữ liệu chạy trên cơ sở dữ liệu quan hệ thường thực hiện một hoặc nhiều giao dịch. Giao dịch là một chương trình thực thi bao gồm một số hoạt động cơ sở dữ liệu, chẳng hạn như đọc từ cơ sở dữ liệu hoặc áp dụng các thao tác thêm, xóa, sửa dữ liệu cho cơ sở dữ liệu. Khi kết thúc giao dịch, nó phải để cơ sở dữ liệu ở trạng thái hợp lệ hoặc nhất quán thỏa mãn tất cả các ràng buộc được chỉ định trên lược đồ cơ sở dữ liệu. Một giao dịch đơn lẻ có thể liên quan đến bất kỳ số lượng hoạt động truy xuất nào và bất kỳ số lượng hoạt động cập nhật nào. Các truy xuất và cập nhật này sẽ cùng nhau tạo thành một đơn vị công việc nguyên tử dựa trên cơ sở dữ liệu. Ví dụ: một giao dịch áp dụng rút tiền qua ngân hàng thường sẽ đọc hồ sơ tài khoản người dùng, kiểm tra xem có đủ số dư hay không, sau đó cập nhật hồ sơ theo số tiền rút.
Một số lượng lớn các ứng dụng thương mại chạy dựa trên cơ sở dữ liệu quan hệ trong hệ thống xử lý giao dịch trực tuyến (OLTP) đang thực hiện các giao dịch với tốc độ lên tới vài trăm mỗi giây. Các khái niệm xử lý giao dịch, thực hiện đồng thời các giao dịch và khôi phục sau khi phát sinh lỗi sẽ được thảo luận sau
4. Tóm tắt
Trong bài này các nội dung lớn mình nghĩ cần lưu ý như sau:
- Mô hình quan hệ về dữ liệu dựa trên lý thuyết tập hợp và quan hệ trong toán học được E.F.Codd của IBM giới thiệu vào năm 1970 trong bài báo "A Relational Model for Large Shared Data Banks"
- Quan hệ là bảng (table) 2 chiều chứa dữ liệu bên trong có thể được hiểu như là một tập hợp các hàng (row) mỗi hàng thể hiện một thực thể hoặc mối liên kết trong thế giới thực, mỗi hàng sẽ có một hoặc nhiều giá trj thành phần
- Một lược đồ quan hệ bao gồm tên quan hệ và danh sách các thuộc tính của quan hệ đó, mỗi thuộc tính sẽ có một miền giá trị (domain), lượng số của miền trị D là số lượng các giá trị của miền trị đó và bậc của lược đồ là số lượng thuộc tính của lược đồ quan hệ đó
- Tuple là tập hợp có thứ tự các giá trị. Mỗi giá trị thuộc miền giá trị của thuộc tính tương ứng trong lược đồ quan hệ
Chúc bạn đọc vui vẻ
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Cơ sở dữ liệu và hệ quản trị cơ sở dữ liệu là một thành phần thiết yếu của cuộc sống trong xã hội hiện đại: hầu hết chúng ta đều gặp các hoạt động liên quan đến hoạt động với cơ sở dữ liệu trong cuộc sống hằng ngày. Trong bài viết này chúng ta sẽ tìm hiểu khái niệm đầu tiên về hệ quản trị cơ sở dữ liệu và nhóm người dùng
Kiến trúc của các gói DBMS đã phát triển từ các hệ thống nguyên khối ban đầu, trong đó toàn bộ gói phần mềm DBMS là một hệ thống tích hợp chặt chẽ, đến các gói DBMS hiện đại được thiết kế theo dạng mô-đun, với kiến trúc client / server trong bài hôm nay mình cùng tìm hiểu về khái niệm và kiến trúc hệ quản trị cơ sở dữ liệu
Mô hình hóa khái niệm là một giai đoạn rất quan trọng trong việc thiết kế một ứng dụng cơ sở dữ liệu thành công. Thông thường, thuật ngữ ứng dụng cơ sở dữ liệu đề cập đến một cơ sở dữ liệu cụ thể và các chương trình liên quan thực hiện các truy vấn và cập nhật cơ sở dữ liệu. Trong bài này chúng ta sẽ tìm hiểu mô hình hóa dữ liệu với sơ đồ ER
Các khái niệm mô hình ER được thảo luận trong Chương 3 là đủ để biểu diễn nhiều lược đồ cơ sở dữ liệu cho các ứng dụng cơ sở dữ liệu truyền thống, bao gồm nhiều ứng dụng xử lý dữ liệu trong kinh doanh và công nghiệp. Tuy nhiên, kể từ cuối những năm 1970, các nhà thiết kế ứng dụng cơ sở dữ liệu đã cố gắng thiết kế các lược đồ cơ sở dữ liệu chính xác hơn phản ánh các thuộc tính và ràng buộc dữ liệu một cách chính xác hơn từ đó chúng ta có mô hình thực thể mối quan hệ mở rộng - EER
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên