Kiến trúc hệ thống data warehouse - Phần tiếp theo
Tổng quan
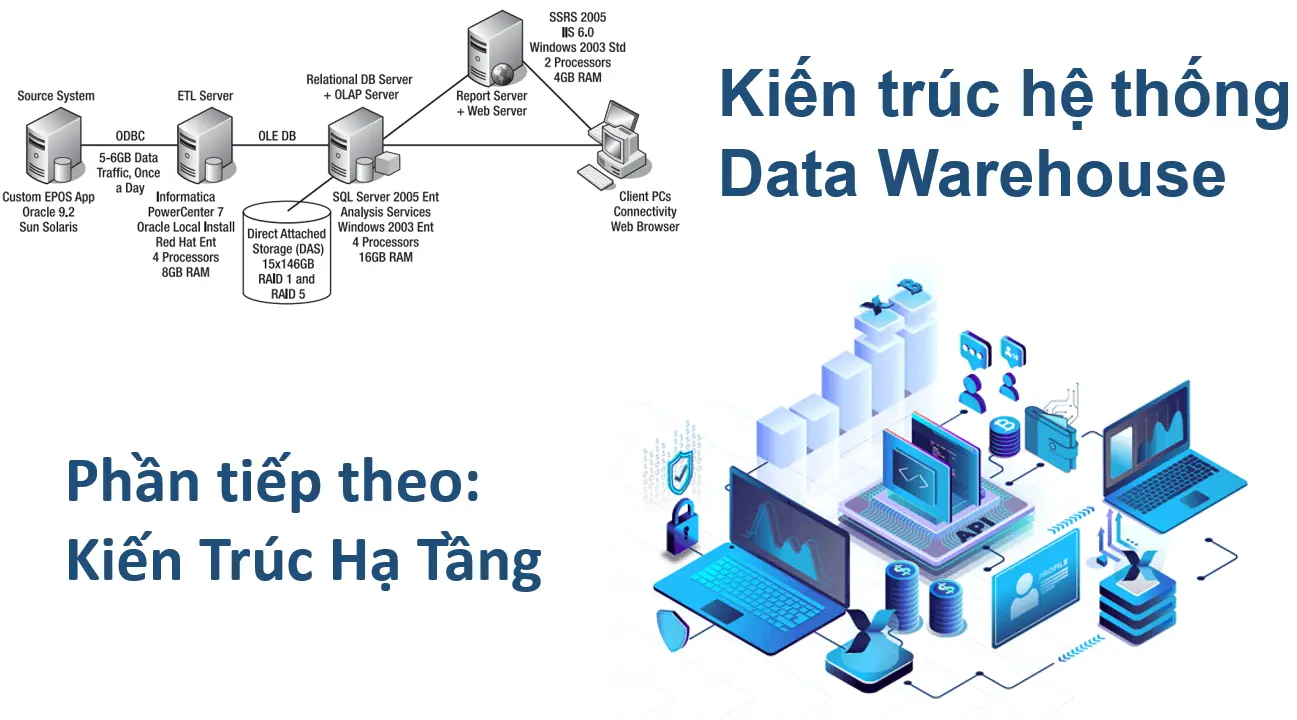
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients. Thiết kế kiến trúc hệ thống yêu cầu kiến thức về phần cứng (đặc biệt là máy chủ), mạng (đặc biệt là về bảo mật và hiệu suất và trong vài năm gần đây còn có cả mạng cáp quang) và lưu trữ (đặc biệt là storage area networks [SAN], dự phòng về ổ cứng [ RAID] và các giải pháp sao lưu tự động). Hình 2-10 cho thấy một ví dụ về kiến trúc hệ thống.
Trong ví dụ này, kiến trúc hệ thống bao gồm ba máy chủ: một máy chủ ETL, một máy chủ cơ sở dữ liệu và một máy chủ báo cáo. Hệ thống nguồn là một hệ thống điểm bán hàng điện tử ghi lại doanh số bán lẻ tại các cửa hàng chạy trên Oracle 9.2 trên Sun Solaris. Máy chủ ETL là Informatica PowerCenter 7 được cài đặt trên Red Hat Enterprise Linux. Kho lưu trữ dữ liệu kho dữ liệu (giai đoạn, DDS và MDB) được lưu trữ trong công cụ cơ sở dữ liệu quan hệ SQL Server và Dịch vụ phân tích, chạy trên Windows Server 2003. Dữ liệu được lưu trữ vật lý trong DAS bao gồm mười lăm đĩa 146GB, tạo nên dung lượng thô 2TB. Các đĩa được cấu hình trong RAID 1 và RAID 5 để phục hồi dữ liệu.
Đây là một ví dụ đại diện cho một kiến trúc điển hình cho một hệ thống trung bình. Chúng ta có một máy chủ ETL chuyên dụng, tách biệt với máy chủ cơ sở dữ liệu. Đó là kích thước dữ liệu trung bình; dung lượng thô của 2TB là khoảng 400GB đến 500GB không gian cơ sở dữ liệu có thể sử dụng, giả sử chúng ta có cả môi trường developement và production. Nền tảng này có một chút hỗn hợp, như thường thấy trong các tổ chức: hệ thống nguồn và ETL không phải của Microsoft. Informatica có lẽ đã ở đó khi dự án kho dữ liệu bắt đầu, vì vậy họ phải sử dụng những gì họ đã có. Do đó, bạn có thể tạo kiến trúc hệ thống với các nền tảng khác nhau.
Những nhà thiết kế kho dữ liệu thường không thiết kế kiến trúc hệ thống của cơ sở hạ tầng kho dữ liệu, nhưng theo ý kiến của tôi, sẽ rất hữu ích nếu bạn biết những chủ đề này—có thể không phải ở mức rất chi tiết, nhưng bạn cần biết ở mức tổng quan. Ví dụ: bạn không cần hiểu cách xây dựng cụm bốn cluster bằng cách sử dụng máy chủ Windows 2003, nhưng bạn cần biết loại tính sẵn sàng cao nào có thể đạt được bằng cách sử dụng công nghệ phân cluster.
Để thiết kế kiến trúc hệ thống kho dữ liệu, trước tiên bạn thiết lập các công nghệ mà bạn muốn sử dụng cho ETL, cơ sở dữ liệu và BI, chẳng hạn như Microsoft SQL Server (SSIS, SSAS), Informatica + Oracle 9i + Cognos, v.v. . Điều này được xác định dựa trên khả năng của sản phẩm và dựa trên tiêu chuẩn của công ty. Sau khi bạn xác định các công nghệ, bạn thực hiện thiết kế ở lớp cao trên máy chủ, cấu hình mạng và cấu hình lưu trữ hỗ trợ công nghệ đã chọn, bao gồm thiết kế có tính sẵn sàng cao. Sau đó, bạn xác định thông số kỹ thuật chi tiết của máy chủ, mạng và bộ lưu trữ. Điều này được thực hiện dựa trên các yêu cầu về năng lực và hiệu suất hệ thống. Sau đó, bạn đặt hàng phần cứng và phần mềm và xây dựng hệ thống trong trung tâm dữ liệu cùng với nhà cung cấp phần cứng và mạng. Sau đó, bạn cài đặt và cấu hình phần mềm. Thiết kế và xây dựng môi trường là cơ bản và quan trọng đối với hiệu suất và tính ổn định của hệ thống kho dữ liệu mà bạn sẽ xây dựng trên đó.
Yếu tố khác ảnh hưởng lớn đến kiến trúc hệ thống là việc lựa chọn phần mềm trong việc xây dựng kho dữ liệu, chẳng hạn như các phiên bản cụ thể của SQL Server, Oracle hoặc Teradata. Kiến trúc hệ thống cần thiết để chạy phần mềm này là khác nhau. Ví dụ, Teradata chạy trên phần cứng xử lý song song ồ ạt. Nó không chia sẻ bộ nhớ giữa các nút. Mặt khác, cụm Máy chủ SQL sử dụng bộ lưu trữ trung tâm. Nó chia sẻ bộ nhớ giữa các nút.
Về mặt phần mềm, có hai loại phần mềm cơ sở dữ liệu khác nhau: đa xử lý đối xứng (SMP) và xử lý song song lớn (MPP). Hệ thống cơ sở dữ liệu SMP là một hệ thống cơ sở dữ liệu chạy trên một hoặc nhiều máy có một số bộ xử lý giống hệt nhau chia sẻ cùng một bộ lưu trữ đĩa. Khi một hệ thống cơ sở dữ liệu SMP chạy trên nhiều máy, nó được gọi là cấu hình cụm. Cơ sở dữ liệu được định vị vật lý trong một hệ thống lưu trữ đĩa đơn. Ví dụ về các hệ thống cơ sở dữ liệu SMP là SQL Server, Oracle, DB/2, Informix và Sybase. Hệ thống cơ sở dữ liệu MPP là hệ thống cơ sở dữ liệu chạy trên nhiều máy trong đó mỗi máy có bộ lưu trữ đĩa riêng. Cơ sở dữ liệu được đặt trên thực tế trong một số hệ thống lưu trữ đĩa được kết nối với nhau. Hệ thống cơ sở dữ liệu MPP còn được gọi là hệ thống cơ sở dữ liệu song song. Ví dụ về các hệ thống cơ sở dữ liệu MPP là Teradata, Neoview, Netezza và DATAllegro
Các máy trong hệ thống cơ sở dữ liệu SMP và MPP được gọi là các nút. Hệ thống cơ sở dữ liệu MPP nhanh hơn và có khả năng mở rộng hơn hệ thống cơ sở dữ liệu SMP. Trong hệ thống cơ sở dữ liệu MPP, một bảng được định vị vật lý trong một số cluster, mỗi cluster có bộ lưu trữ riêng. Khi bạn truy xuất dữ liệu từ bảng này, tất cả các nút đồng thời đọc dữ liệu từ bộ nhớ riêng của chúng, do đó, quá trình đọc dữ liệu từ đĩa sẽ nhanh hơn. Tương tự, khi bạn tải dữ liệu vào bảng này, tất cả các cluster đồng thời tải một chút dữ liệu vào đĩa của chúng. Trong các hệ thống cơ sở dữ liệu SMP, có một cluster cổ chai trên đĩa lưu trữ. Mặt khác, các hệ thống cơ sở dữ liệu SMP đơn giản hơn, dễ bảo trì hơn và có chi phí thấp hơn.
Case Study
Trường hợp điển hình này cần bao gồm tất cả các khía cạnh mà bạn muốn tìm hiểu: kiến trúc, phương pháp, yêu cầu, mô hình hóa dữ liệu, thiết kế cơ sở dữ liệu, ETL, chất lượng dữ liệu, siêu dữ liệu, lưu trữ dữ liệu, báo cáo, cơ sở dữ liệu đa chiều, BI, CRM, thử nghiệm, và quản trị kho dữ liệu. Lý tưởng nhất ở đây mong muốn ví dụ điển hình đủ đơn giản để hiểu và thực hiện như một dự án, nhưng tôi không muốn nó quá đơn giản vì nó sẽ không đề cập đến một số lĩnh vực đã đề cập trước đây. Vì vậy, nó cần đơn giản nhưng không quá đơn giản.
Một số ngành “thân thiện với kho dữ liệu”, nghĩa là bản chất của dữ liệu là lý tưởng cho việc lưu trữ dữ liệu. Bán lẻ, tiện ích, viễn thông, chăm sóc sức khỏe và dịch vụ tài chính là một số trong số đó. Trong nghiên cứu điển hình này, tôi chọn lĩnh vực bán lẻ vì các hoạt động kinh doanh dễ hiểu hơn khi chúng ta trải nghiệm chúng trong cuộc sống hàng ngày.
Amadeus Entertainment là công ty giải trí chuyên về âm nhạc, phim ảnh và sách nói. Nó có tám cửa hàng trực tuyến hoạt động tại Hoa Kỳ, Đức, Pháp, Vương quốc Anh, Tây Ban Nha, Úc, Nhật Bản và Ấn Độ. Nó cũng có 96 cửa hàng ngoại tuyến hoạt động ở các quốc gia đó.
Khách hàng có thể mua các sản phẩm riêng lẻ như bài hát, sách nói hoặc phim hoặc họ có thể đăng ký một gói nhất định để họ có thể tải xuống một số lượng sản phẩm nhất định trong một khoảng thời gian nhất định. Ví dụ: với gói Primer, bạn có thể tải xuống 100 bài hát, 50 cuốn sách và 50 bộ phim mỗi tháng với giá 50 USD. Khách hàng cũng có thể nghe hoặc xem một lần một bài hát, một cuốn sách hoặc một bộ phim với giá 1 ⁄10 chi phí mua nó. Vì vậy, nếu một bộ phim là 5 đô la, để xem nó một lần thì chỉ có 50 xu. Khách hàng sử dụng tính năng phát trực tuyến cho việc này, vì vậy cần có kết nối Internet tốt.
Amadeus Entertainment có bốn kênh phân phối chính: Internet, mobile, truyền hình cáp và bưu điện. Có một số mô hình thanh toán chokhách hàng, chẳng hạn như ghi nợ trực tiếp hàng năm, trả trước và hàng tháng. Công ty mua sản phẩm với số lượng lớn, chẳng hạn như bất kỳ 10.000 bài hát nào từ một công ty thu âm, với bất kỳ tiêu đề nào, với một mức chi phí nhất định. Đối với phát trực tuyến, công ty trả tiền cho nhà cung cấp trung tâm (Geo Broadcasting Ltd.) dựa trên việc sử dụng (hóa đơn hàng tháng).
Công ty sử dụng WebTower9, một hệ thống dựa trên .NET được phát triển tùy chỉnh cho các trang web động, giao dịch đa phương tiện, truyền phát, xử lý đơn đặt hàng và quản lý đăng ký, tất cả đều chạy trên cơ sở dữ liệu Oracle. Hệ thống hoạch định nguồn lực doanh nghiệp (ERP) phía sau là Jupiter, một hệ thống kinh doanh dựa trên AS/400 có sẵn chạy trên DB2. Đây là nơi quản lý hàng tồn kho, sản phẩm và tài chính. Kích thước cơ sở dữ liệu của Jupiter là khoảng 800GB với khoảng 250 bảng và dạng xem.
Các hoạt động kinh doanh tại các cửa hàng ngoại tuyến được quản lý trong Jade, đây là một hệ thống tùy chỉnh phát triển dựa trên ngôn ngữ lập trình Java chạy trên Informix. Hệ thống này bao gồm bán hàng, dịch vụ khách hàng và đăng ký. WebTower9 và Jade truy cập các sản phẩm và tài chính của Jupiter hàng ngày, nhưng dữ liệu về doanh số và khách hàng (bao gồm cả đăng ký) được lưu giữ trên WebTower9 và Jade.
Công ty sử dụng hệ thống SupplyNet để giao tiếp với các nhà cung cấp. Đây là mạng lưới nhà cung cấp tiêu chuẩn công nghiệp dựa trên dịch vụ web trong ngành giải trí trực tuyến bao gồm âm nhạc và phim ảnh. WebTower9 và Jupiter được lưu trữ tại trụ sở chính của Amadeus Entertainment. Jade được lưu trữ trong một công ty thuê ngoài ở Bangalore, Ấn Độ. Thao tác xử lý batch của Jupiter bắt đầu lúc 11h đêm. Giờ chuẩn miền Đông (EST) vào khoảng ba đến bốn giờ. Công việc sao lưu ngoại tuyến bắt đầu ngay sau đợt batch và chạy trong một đến hai giờ. Sao lưu bắt đầu lúc 3 giờ sáng EST trong hai đến ba giờ
Nhóm kiến trúc CNTT đã quyết định chuẩn hóa nền tảng cơ sở dữ liệu trên Microsoft SQL Server và sử dụng các dịch vụ dựa trên web cho nền tảng ứng dụng của nó. Ở đây trong ví dụ này sẽ trình bày cách xây dựng hệ thống kho dữ liệu cho Amadeus Entertainment bằng Microsoft SQL Server 2005. Bạn cũng có thể sử dụng SQL Server 2008 để xây dựng hệ thống này. VÍ dụ sẽ sử dụng kiến trúc kho dữ liệu NDS + DDS đã nêu trước đó trong chương này. Hình 2-11 cho thấy kiến trúc hệ thống cho môi trường production.
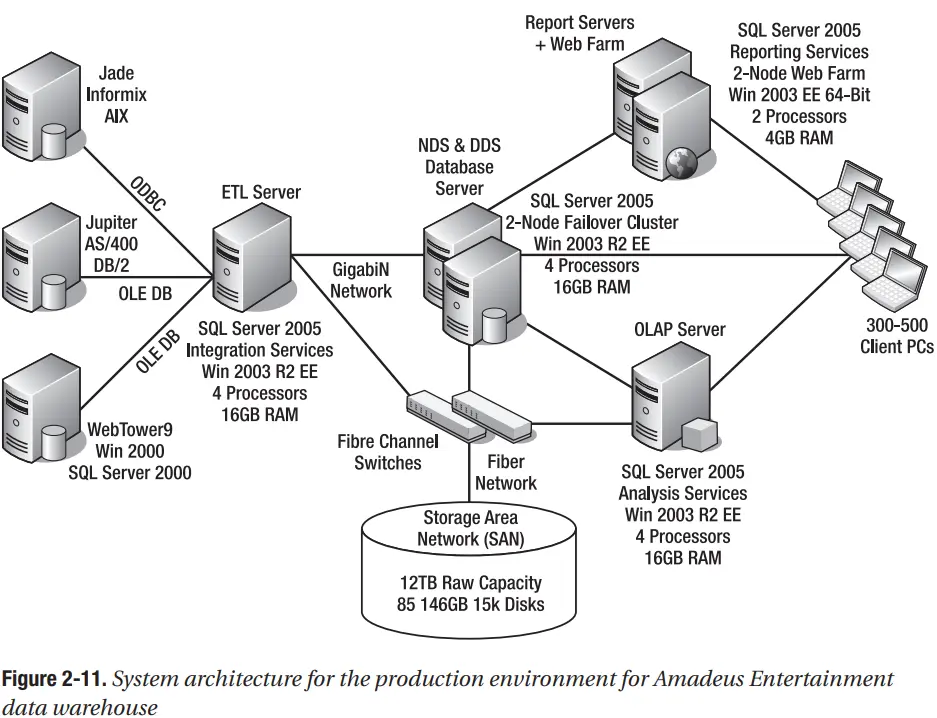
Trong Hình 2-11, Integration Service, Reporting Service và Analysis Service sẽ được cài đặt trên các máy riêng biệt. Ở đây sử dụng SAN với dung lượng thô là 12TB. Dung lượng lưu trữ cuối cùng có thể ít hơn nhiều so với dung lượng thô
Đây chỉ là một kiến trúc dự kiến như một minh họa về cách nó có thể được thực hiện. Thông số kỹ thuật của máy chủ trong Hình 2-11 là cao, có thể là quá cao đối với dự án này. Khi nhận được các yêu cầu, bạn có thể thiết kế chi tiết hơn. Ví dụ:
- Các yêu cầu về tính sẵn sàng cao (chúng có thể chịu đựng kho dữ liệu ngừng hoạt động trong bao nhiêu giờ) ảnh hưởng đến quyết định phân cụm của các máy chủ cơ sở dữ liệu.
- Khối lượng dữ liệu từ các hệ thống nguồn ảnh hưởng đến số lượng bộ xử lý và bộ nhớ của máy chủ ETL và liệu có cần đặt SSIS trên một máy riêng hay không.
- Khối lượng dữ liệu trong kho dữ liệu ảnh hưởng đến kích thước lưu trữ và yêu cầu sao lưu. Kích thước đĩa thô SAN có thể nhỏ hơn hoặc lớn hơn 12TB tùy theo yêu cầu thực tế
- Số lượng và kích thước của các khối OLAP ảnh hưởng đến bộ nhớ và bộ xử lý của máy chủ OLAP và liệu có cần đặt Analytis Service trên một máy chủ riêng biệt hay không
Bạn cần lưu ý, đặc biệt khi lập ngân sách cho cơ sở hạ tầng (phần cứng và phần mềm), bạn cần tạo một bộ thứ hai cho môi trường thử nghiệm (được biết đến rộng rãi là đảm bảo chất lượng [QA]) và một bộ khác cho môi trường phát triển (hoặc nhà phát triển). , viết tắt). Không giống như trong OLTP, trong kho dữ liệu, điều cần thiết là QA phải có khả năng giống như khả năng của môi trường production. Điều này là do trong kho dữ liệu, bạn cần thực hiện kiểm tra hiệu suất và khối lượng. Nếu QA của bạn chỉ bằng một nửa năng lực production, phép đo của bạn trong kiểm tra hiệu suất sẽ không chính xác. Một ETL batch trong môi trường production chạy trong ba giờ trong QA có thể chạy trong bảy giờ
Môi trường developement có thể có thông số kỹ thuật thấp hơn môi trường production. Ví dụ, trong nghiên cứu tình huống của Amadeus Entertainment, môi trường developement có thể chỉ là một máy chủ; nói cách khác, công cụ cơ sở dữ liệu, Integration Service, Analytis Service và Reporting Service đều được cài đặt trong một máy chủ. Điều này là do mục đích chính của dev là phát triển chức năng. Kiểm thử hiệu suất được tiến hành trong QA
Những câu hỏi khó trả lời nhất khi thiết kế kiến trúc hệ thống là về quy mô và/hoặc dung lượng. Đặc biệt, các nhà cung cấp cơ sở hạ tầng thường hỏi hai câu hỏi sau:
- Bạn cần bao nhiêu dung lượng đĩa (dữ liệu của bạn lớn đến mức nào)?
- Bạn cần bao nhiêu sức mạnh xử lý (về bộ xử lý và bộ nhớ)?
Chúng ta sẽ xem xét chi tiết về thiết kế trong bài cụ thể
Tổng kết
Bài này chúng ta đã thảo luận về kiến trúc phần cứng để triển khai hệ thống kho dữ liệu, cảm ơn bạn đọc đã theo dõi
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên