Một số hệ quản trị cở sở dữ liệu phổ biến – Phần 1: Tổng quan về PostgreSQL

PostgreSQL (hay “Postgres”) là một hệ thống quản lý cơ sở dữ liệu quan hệ (viết tắt là RDBMS). Cơ sở dữ liệu quan hệ là các hệ thống dựa trên lý thuyết tập hợp, trong đó dữ liệu được lưu trữ trong các bảng hai chiều bao gồm các hàng dữ liệu và các cột với kiểu dữ liệu được quy định cụ thể, chặt chẽ. Bất chấp sự quan tâm ngày càng tăng đối với các xu hướng cơ sở dữ liệu mới hơn, cơ sở dữ liệu quan hệ vẫn đang khác phổ biến và có thể sẽ tồn tại trong một thời gian khá dài. Ngay cả trong các hệ thống “NoSQL”, nền tảng vững chắc về RDBMS vẫn rất cần thiết. Trong bài này mình sẽ giới thiệu đến các bạn một trong những hệ thống cơ sở dữ liệu quan hệ tốt nhất hiện nay - PostgreSQL.
Mặc dù sự phổ biến của cơ sở dữ liệu quan hệ một phần có thể dựa trên bộ công cụ rộng lớn của chúng (triggers, stored procedures, views, indexes), sự an toàn dữ liệu của chúng (theo chuẩn ACID) hoặc việc chia sẻ về mặt "ý tưởng" (nhiều lập trình viên nói và suy nghĩ theo mô hình quan hệ), tính linh hoạt của truy vấn cũng đóng vai trò trung tâm. Không giống như một số cơ sở dữ liệu khác, đối với cơ sở dữ liệu quan hệ bạn không cần biết trước cách bạn dự định sử dụng dữ liệu. Nếu một lược đồ quan hệ được chuẩn hóa, các truy vấn sẽ linh hoạt. Bạn có thể bắt đầu lưu trữ dữ liệu và không cần năm rõ về cách mà bạn sẽ sử dụng dữ liệu sau này, thậm chí bạn có thể thay đổi toàn bộ các truy vấn của bạn theo thời gian khi nhu cầu của bạn thay đổi
Tổng quan
PostgreSQL cho đến nay là cơ sở dữ liệu lâu đời và được thử nghiệm rất nhiều. Nó hỗ trợ một số plug-in dành riêng cho các nhu cầu đặc biệt như phân tích cú pháp ngôn ngữ tự nhiên, lập chỉ mục đa chiều, truy vấn địa lý (cở sở dữ liệu địa lý, không gian), kiểu dữ liệu tùy chỉnh, v.v. Nó cũng hỗ trợ xử lý giao dịch phức tạp và các thủ tục được lưu trữ (stored procedure). PostgreSQL tích hợp sẵn Unicode, sequence, bảng kế thừa và các tiện ích khác, và đây là một trong những cơ sở dữ liệu quan hệ tuân thủ SQL ANSI tốt nhất trên thị trường. Nó nhanh và đáng tin cậy, có thể xử lý hàng terabyte dữ liệu và đã được chứng minh là có thể chạy trong các dự án cao cấp như Skype, Yahoo!, Caisse Nationale d'Allocations Familiales (CNAF) của Pháp, Ngân hàng Caixa của Brazil và Cục Hàng không Liên bang (FAA)
Bạn có thể cài đặt PostgreSQL theo nhiều cách, tùy thuộc vào hệ điều hành của bạn. Khi bạn đã cài đặt Postgres, hãy tạo một lược đồ có tên 7dbs bằng lệnh sau:
$ createdb 7dbs
Relations, CRUD, và Joins
Ở đây bạn có thể không là một chuyên gia về cơ sở dữ liệu quan hệ, nhưng mình cho rằng bạn đã từng đối mặt với một hoặc hai cơ sở dữ liệu trong quá khứ. Chúng ta sẽ bắt đầu với việc tạo các lược đồ của riêng mình và khởi tạo dữ liệu tương ứng. Sau đó, hãy xem xét truy vấn các giá trị và cuối cùng khám phá điều gì làm cho cơ sở dữ liệu quan hệ trở nên đặc biệt: phép nối bảng (table join)
Giống như hầu hết các cơ sở dữ liệu mà bạn sẽ đọc, Postgres cung cấp một máy chủ back-end thực hiện tất cả công việc và tập hợp các câu lệnh để kết nối với máy chủ đang chạy. Theo mặc định, máy chủ giao tiếp qua cổng 5432, cổng này bạn có thể kết nối bằng lệnh psql. Bây giờ hãy kết nối với lược đồ 7dbs:
$ psql 7dbs
PostgreSQL nhận tham số tên cơ sở dữ liệu theo sau là dấu thăng (#) nếu bạn chạy với tư cách quản trị viên và dấu đô la ($) với tư cách người dùng thông thường. Shell cũng được trang bị tài liệu tích hợp hướng dẫn dành cho người dùng. Nhập \h liệt kê thông tin về các lệnh SQL và \? nếu cần trợ giúp với các lệnh dành riêng cho psql, cụ thể là các lệnh bắt đầu bằng dấu gạch chéo ngược. Bạn có thể tìm thấy tài liệu chi tiết sử dụng về từng lệnh SQL theo cách sau (một số chỗ đã bị cắt bớt):
7dbs=# \h CREATE INDEX
Command: CREATE INDEX
Description: define a new index
Syntax:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ name ] ON table [ USING method ]
( { column | ( expression ) } [ opclass ] [ ASC | DESC ] [ NULLS ...
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace ]
[ WHERE predicate ]
Trước khi bắt đầu phần tiếp theo về Postgres, bạn nên làm quen với công cụ hữu ích này. Bạn nên xem qua (hoặc tìm hiểu thêm) một số lệnh phổ biến, chẳng hạn như SELECT và CREATE TABLE.
Bắt đầu với SQL
PostgreSQL tuân theo quy ước SQL gọi các BẢNG thay cho quan hệ, các CỘT thay cho thuộc tính và các ROW thay cho các bộ. Để thống nhất, bài viết sẽ sử dụng thuật ngữ này, mặc dù đôi khi bạn có thể gặp các thuật ngữ toán học như quan hệ, thuộc tính và bộ. Chi tiết hơn cho phần này bạn có thể tham khảo bài viết đại số quan hệ
Làm việc với table
PostgreSQL, thuộc kiểu quan hệ, là cơ sở dữ liệu ưu tiên thiết kế. Trước tiên, bạn thiết kế lược đồ; sau đó bạn nhập dữ liệu phù hợp với định nghĩa của lược đồ đó
Tạo một bảng liên quan đến việc đặt tên cho bảng và một danh sách các cột với các loại và thông tin ràng buộc (tùy chọn). Mỗi bảng cũng nên chỉ định một cột định danh duy nhất để xác định các hàng cụ thể. Mã định danh đó được gọi là PRIMARY KEY. Câu lệnh SQL để tạo bảng countries như sau:
CREATE TABLE countries (
country_code char(2) PRIMARY KEY,
country_name text UNIQUE
);
Bảng mới này sẽ lưu trữ một tập hợp các hàng, trong đó mỗi hàng được xác định bằng mã quốc gia hai ký tự và tên là duy nhất. Cả hai cột này đều có các ràng buộc. PRIMARY KEY ràng buộc cột country_code không cho phép mã quốc gia trùng lặp. Chỉ có một us và một gb có thể tồn tại. Ở đây đoạn mã DML đã cung cấp rõ ràng country_name một ràng buộc duy nhất tương tự, mặc dù nó không phải là khóa chính. Ta có thể điền vào bảng quốc gia bằng cách chèn một vài hàng.
INSERT INTO countries (country_code, country_name)
VALUES ('us','United States'), ('mx','Mexico'), ('au','Australia'),
('gb','United Kingdom'), ('de','Germany'), ('ll','Loompaland');
Hãy kiểm tra ràng buộc duy nhất. Cố gắng thêm một country_name trùng lặp sẽ khiến ràng buộc duy nhất không thành công, do đó không cho phép chèn. Các ràng buộc là cách các cơ sở dữ liệu quan hệ như PostgreSQL đảm bảo dữ liệu nhất quán.
INSERT INTO countries
VALUES ('uk','United Kingdom');
Thao tác này sẽ trả về lỗi cho biết Khóa (country_name) = ('United Kingdom') đã tồn tại.
Chúng ta có thể xác thực rằng các hàng thích hợp đã được chèn vào bằng cách đọc chúng bằng lệnh SELECT...FROM table.
SELECT *
FROM countries;
Theo bất kỳ bản đồ đáng tin cậy nào, Loompaland không phải là một địa điểm có thật, vì vậy hãy loại bỏ nó khỏi bảng. Hãy chỉ định hàng nào cần xóa bằng mệnh đề WHERE. Hàng có country_code bằng ll sẽ bị xóa.
DELETE FROM countries
WHERE country_code = 'll';
Chỉ còn lại các quốc gia thực trong bảng quốc gia, hãy thêm một bảng thành phố. Để đảm bảo mọi country_code được chèn cũng tồn tại trong bảng countries bằng cách sử dụng từ khóa REFERENCES. Vì cột country_code tham chiếu đến khóa của một bảng khác nên nó được gọi là ràng buộc khóa ngoại (foreign key).
CREATE TABLE cities (
name text NOT NULL,
postal_code varchar(9) CHECK (postal_code <> ''),
country_code char(2) REFERENCES countries,
PRIMARY KEY (country_code, postal_code)
);
Ở đây đã hạn chế tên ở các thành phố bằng cách không cho phép các giá trị NULL. Hơn nữa hạn chế mã bưu chính bằng cách kiểm tra để đảm bảo rằng không có giá trị nào là chuỗi trống (<> có nghĩa là không bằng nhau). Ngoài ra, do PRIMARY KEY xác định duy nhất một hàng nên đã tạo một khóa phức hợp: country_code + Postal_code. Hai thuộc này xác định duy nhất một hàng.
Postgres cũng có một tập hợp phong phú các kiểu dữ liệu. Bạn vừa thấy ba cách biểu diễn chuỗi khác nhau: text (chuỗi có độ dài bất kỳ), varchar(9) (chuỗi có độ dài thay đổi lên đến chín ký tự) và char(2) (chuỗi có đúng hai ký tự). Với lược đồ hiện tại, hãy chèn Toronto, CA.
INSERT INTO cities
VALUES ('Toronto','M4C1B5','ca');
ERROR: insert or update on table "cities" violates foreign key constraint
"cities_country_code_fkey"
DETAIL: Key (country_code)=(ca) is not present in table "countries".
Báo lỗi! Vì country_code THAM CHIẾU các quốc gia nên country_code phải tồn tại trong bảng countries. Như minh họa, từ khóa REFERENCES ràng buộc các trường vào khóa chính của bảng khác. Điều này được gọi là duy trì tính toàn vẹn tham chiếu và nó đảm bảo dữ liệu luôn chính xác.
Cần lưu ý rằng NULL hợp lệ cho thuộc tính country_code vì NULL đại diện cho việc thiếu giá trị. Nếu bạn muốn không cho phép tham chiếu mã quốc gia NULL, bạn sẽ xác định cột thành phố trong bảng như sau: country_code char(2) REFERENCES countries NOT NULL.
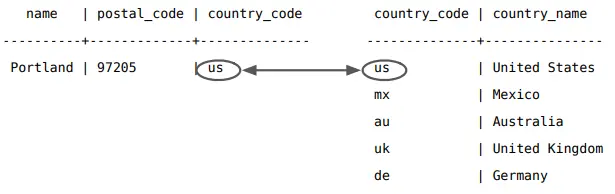
Bây giờ, hãy thử một insert khác, lần này với một thành phố của Hoa Kỳ (rất có thể là thành phố lớn nhất của Hoa Kỳ).
INSERT INTO cities
VALUES ('Portland','87200','us');
INSERT 0 1
Đây là một câu lệnh insert thành công, để chắc chắn. Nhưng ở đây đã nhập nhầm mã bưu điện không thực sự tồn tại ở Portland. Một mã bưu chính tồn tại là 97206. Thay vì xóa và chèn lại giá trị, bạn có thể cập nhật mã bưu chính đó bằng câu lệnh update.
UPDATE cities
SET postal_code = '97206'
WHERE name = 'Portland';
Tới phần này thì bạn đã thực hiện qua các câu lện insert, delete, update các hàng của table
Câu lệnh truy vấn với Join
Hầu hết các cơ sở dữ liệu điều thực hiện các thao tác CRUD. Điều làm nên sự khác biệt của các cơ sở dữ liệu quan hệ như PostgreSQL là khả năng nối các bảng lại với nhau khi query. Về bản chất, join là một thao tác lấy hai bảng riêng biệt và kết hợp chúng theo một cách nào đó để trả về một bảng duy nhất. Nó giống như ghép các mảnh ghép lại với nhau để tạo nên một bức tranh lớn hơn, hoàn chỉnh hơn.
Dạng cơ bản của phép nối là phép inner join. Ở dạng đơn giản nhất, bạn chỉ định hai cột (một từ mỗi bảng) để đối sánh bằng cách sử dụng từ khóa ON.
SELECT cities.*, country_name
FROM cities INNER JOIN countries /* or just FROM cities JOIN countries */
ON cities.country_code = countries.country_code;
Phép nối trả về một bảng duy nhất, chia sẻ giá trị của tất cả các cột của bảng cities cộng với giá trị country_name phù hợp từ bảng countries.
Bạn cũng có thể join một bảng như cities có khóa chính phức hợp. Để kiểm tra phép nối phức hợp, hãy tạo một bảng mới lưu trữ danh sách các địa điểm.
Địa điểm tồn tại ở cả mã bưu chính và quốc gia cụ thể. Khóa ngoại phải là hai cột tham chiếu cả hai cột khóa chính của cities. (MATCH FULL là một ràng buộc đảm bảo cả hai giá trị đều tồn tại hoặc cả hai đều là NULL.)
CREATE TABLE venues (
venue_id SERIAL PRIMARY KEY,
name varchar(255),
street_address text,
type char(7) CHECK ( type in ('public','private') ) DEFAULT 'public',
postal_code varchar(9),
country_code char(2),
FOREIGN KEY (country_code, postal_code)
REFERENCES cities (country_code, postal_code) MATCH FULL
);
Cột venue_id này là một thiết lập khóa chính phổ biến: các số nguyên tăng dần tự động (1, 2, 3, 4, v.v.). Bạn tạo mã định danh này bằng từ khóa SERIAL. (MySQL có cấu trúc tương tự được gọi là AUTO_INCREMENT hoặc IDENTITY với SQL Server)
INSERT INTO venues (name, postal_code, country_code)
VALUES ('Crystal Ballroom', '97206', 'us');
Mặc dù chúng tôi không đặt giá trị venue_id, nhưng khi tạo hàng PostgreSQL đã điền giá trị đó.
Quay lại với câu lệnh join. Khi join bản bảng venue với bảng cities yêu cầu cả hai cột khóa ngoại. Để tiết kiệm thời gian gõ lệnh, bạn có thể đặt bí danh cho tên bảng bằng cách đặt bí danh trực tiếp theo tên bảng thực, với AS tùy chọn ở giữa (ví dụ: địa điểm v hoặc địa điểm AS v).
SELECT v.venue_id, v.name, c.name
FROM venues v INNER JOIN cities c
ON v.postal_code=c.postal_code AND v.country_code=c.country_code;
Bạn có thể tùy ý yêu cầu PostgreSQL trả về các cột sau khi chèn bằng cách kết thúc truy vấn
bằng câu lệnh RETURNING.
INSERT INTO venues (name, postal_code, country_code) VALUES ('Voodoo Doughnut', '97206', 'us') RETURNING venue_id;
Outer Join
Ngoài inner join, PostgreSQL cũng có thể thực hiện các phép outer join. Outer join là một cách hợp nhất hai bảng khi kết quả của một bảng phải luôn được trả về, cho dù có bất kỳ giá trị cột so sánh khớp nào tồn tại trên bảng kia hay không.
Cách dễ nhất là đưa ra một ví dụ, nhưng để làm điều đó, chúng ta sẽ tạo một bảng mới có tên là events. Điều này là tùy thuộc vào bạn. Bảng events của bạn phải có các cột sau: số nguyên SERIAL event_id, title, starts và ends (kiểu dữ liệu timestamp) và venue_id (khóa ngoại tham chiếu địa điểm). Sơ đồ định nghĩa lược đồ bao gồm tất cả các bảng đã tạo hiển thị trong hình dưới đây.
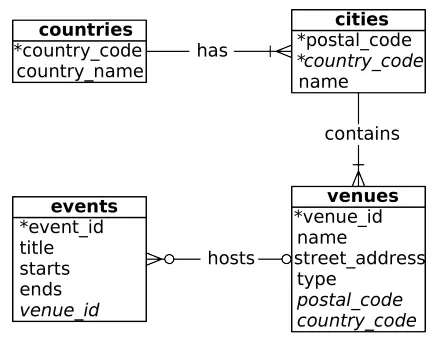
Sau khi tạo bảng sự kiện, CHÈN các giá trị sau (dấu thời gian được chèn dưới dạng chuỗi như 2018-02-15 17:30) cho hai ngày lễ

Trước tiên, hãy tạo một truy vấn trả về event_title và venue_name với inner join (không bắt buộc phải có từ INNER từ INNER JOIN).
SELECT e.title, v.name
FROM events e JOIN venues v
ON e.venue_id = v.venue_id;
INNER JOIN sẽ chỉ trả về một hàng nếu các giá trị cột khớp nhau. Bởi vì NULL không đề cập đến điều gì. Truy xuất tất cả các sự kiện, cho dù chúng có địa điểm hay không, yêu cầu LEFT OUTER JOIN (rút gọn thành LEFT JOIN).
SELECT e.title, v.name
FROM events e LEFT JOIN venues v
ON e.venue_id = v.venue_id;
Nếu bạn yêu cầu ngược lại, tất cả các địa điểm và chỉ các sự kiện phù hợp, hãy sử dụng RIGHT JOIN. Cuối cùng, có FULL OUTER JOIN, là sự kết hợp của LEFT và RIGHT; bạn được đảm bảo tất cả các giá trị từ mỗi bảng, được nối với nhau ở bất kỳ nơi nào các cột khớp với nhau.
Lập chỉ mục (index)
Tốc độ của PostgreSQL (và bất kỳ RDBMS nào khác) nằm ở khả năng quản lý hiệu quả các khối dữ liệu, giảm số lần đọc đĩa, tối ưu hóa truy vấn và các kỹ thuật khác. Nhưng những điều đó chỉ tiến xa trong việc tìm nạp kết quả một cách nhanh chóng. Nếu chúng ta chọn tiêu đề Christmas Day từ bảng events, thuật toán phải quét mọi hàng để tìm kết quả khớp. Không có chỉ mục, mỗi hàng phải được đọc từ đĩa để biết liệu truy vấn có trả về nó hay không. Xem phần sau.
Chỉ mục là một cấu trúc dữ liệu đặc biệt được xây dựng để tránh quét toàn bộ bảng khi thực hiện truy vấn. Khi chạy các lệnh CREATE TABLE, bạn có thể thấy thông báo như sau:
CREATE TABLE / PRIMARY KEY will create implicit index "events_pkey" \
for table "events"
PostgreSQL tự động tạo chỉ mục trên khóa chính—cụ thể là chỉ mục cây B—trong đó khóa là giá trị khóa chính và giá trị trỏ đến một hàng trên đĩa
Bạn có thể thêm hash index bằng cách sử dụng lệnh CREATE INDEX, trong đó mỗi giá trị phải là duy nhất (như bảng băm hoặc map).
CREATE INDEX events_title
ON events USING hash (title);
Đối với các kết quả khớp nhỏ hơn/lớn hơn/bằng, có thể sử dụng một chỉ mục linh hoạt hơn một hàm băm đơn giản, chẳng hạn như B-tree, có thể khớp với các truy vấn có phạm vi.
Tóm tắt
Bài viết đã giới thiệu tổng quan về Postgres với các thao tác đơn giản như CRUD và tạo index. Chúc bạn đọc vui vẻ
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
Cơ sở dữ liệu và hệ quản trị cơ sở dữ liệu là một thành phần thiết yếu của cuộc sống trong xã hội hiện đại: hầu hết chúng ta đều gặp các hoạt động liên quan đến hoạt động với cơ sở dữ liệu trong cuộc sống hằng ngày. Trong bài viết này chúng ta sẽ tìm hiểu khái niệm đầu tiên về hệ quản trị cơ sở dữ liệu và nhóm người dùng
Kiến trúc của các gói DBMS đã phát triển từ các hệ thống nguyên khối ban đầu, trong đó toàn bộ gói phần mềm DBMS là một hệ thống tích hợp chặt chẽ, đến các gói DBMS hiện đại được thiết kế theo dạng mô-đun, với kiến trúc client / server trong bài hôm nay mình cùng tìm hiểu về khái niệm và kiến trúc hệ quản trị cơ sở dữ liệu
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên