Một số hệ quản trị cơ sở dữ liệu phổ biến – Phần 3: FullText và Multidimensions

Bài này dành để nghiên cứu các công cụ để xây dựng một hệ thống cơ sở dữ liệu quản lý các bộ phim với PostgreSQL FullText và Multidimensions. Chúng ta sẽ bắt đầu với cách PostgreSQL hỗ trợ tìm kiếm tên diễn viên/phim bằng cách sử dụng so sánh chuỗi mờ (fuzzy searching). Sau đó, chúng ta sẽ tìm hiểu multidimension bằng cách tạo tính năng gợi ý phim dựa trên các thể loại phim tương tự mà người dùng đã thích. Đây là các gói hỗ trợ được phát triển dành riêng đặc biệt với PostgreSQL và không phải là một phần của tiêu chuẩn SQL.
Thông thường, khi thiết kế một lược đồ cơ sở dữ liệu quan hệ, bạn sẽ bắt đầu với một sơ đồ thực thể. Chúng tôi sẽ viết một hệ thống đề xuất phim cá nhân để theo dõi các bộ phim, thể loại và diễn viên của chúng, như được mô hình hóa dưới đây
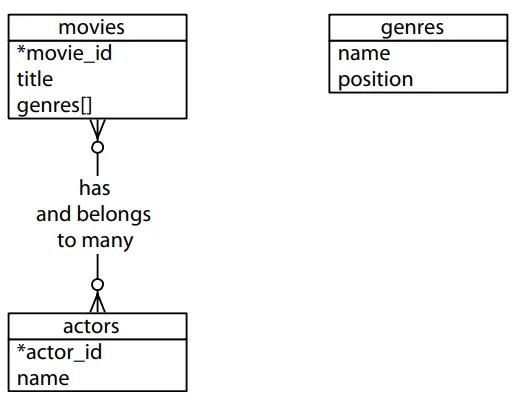
Trước khi bắt đầu bài này, chúng ta cần mở rộng Postgres bằng cách cài đặt các gói bổ sung sau: tablefunc, dict_xsyn,uzzystrmatch, pg_trgm và cube. Bạn có thể tham khảo trang web để được hướng dẫn cài đặt.
Chạy lệnh sau và kiểm tra xem nó có khớp với kết quả bên dưới không để đảm bảo các gói của bạn đã được cài đặt chính xác:
$ psql 7dbs -c "SELECT '1'::cube;"
cube
------
(1)
(1 row)
Tìm tài liệu để biết thêm thông tin nếu bạn nhận được thông báo lỗi.
Trước tiên hãy xây dựng cơ sở dữ liệu. Cách tốt nhất là tạo các index trên các khóa ngoại để tăng tốc độ tra cứu ngược (chẳng hạn như những bộ phim mà diễn viên này tham gia). Bạn cũng nên đặt ràng buộc UNIQUE trên các bảng tham gia như movies_actors để tránh các giá trị tham gia trùng lặp.
CREATE TABLE genres (
name text UNIQUE,
position integer
);
CREATE TABLE movies (
movie_id SERIAL PRIMARY KEY,
title text,
genre cube
);
CREATE TABLE actors (
actor_id SERIAL PRIMARY KEY,
name text
);
CREATE TABLE movies_actors (
movie_id integer REFERENCES movies NOT NULL,
actor_id integer REFERENCES actors NOT NULL,
UNIQUE (movie_id, actor_id)
);
CREATE INDEX movies_actors_movie_id ON movies_actors (movie_id);
CREATE INDEX movies_actors_actor_id ON movies_actors (actor_id);
CREATE INDEX movies_genres_cube ON movies USING gist (genre);
Bạn có thể tải file movies_data.sql để seed dữ liệu cho phần thực hành của bài viết này tại đây
Fuzzy Searching
Tìm kiếm văn bản là một trong những tính năng thường thấy với hầu hết các hệ thống và thường là người dùng nhập dữ liệu không chính xác. Bạn thường phải gặp những lỗi chính tả như “Brid of Frankstein.” Đôi khi, người dùng không thể nhớ tên đầy đủ của “J. Roberts.” Trong các trường hợp khác, đơn giản là họ không biết cách đánh vần “Benn Aflek”. Hãy sẽ xem xét cách mà PostgreSQL giúp tìm kiếm văn bản dễ dàng.
Điều đáng chú ý là khi công nghệ phát triển, kiểu so sánh khớp chuỗi này bị làm mờ ranh giới giữa các truy vấn quan hệ và các nền tảng hỗ trợ tìm kiếm như Lucene và Elaticsearch. Mặc dù một số người có thể cảm thấy rằng các tính năng như tìm kiếm nên được đặt trong phần code của ứng dụng, nhưng có thể có các lợi ích về hiệu suất và quản trị khi đẩy các gói này vào cơ sở dữ liệu, nơi lưu trữ dữ liệu.
SQL Standard String Matches
PostgreSQL có nhiều cách để tìm kiếm so sánh chuỗi khớp nhau nhưng hai phương thức mặc định chính là LIKE và regular expressions (biểu thức chính quy)
LIKE và ILIKE
LIKE và ILIKE là các hình thức tìm kiếm văn bản đơn giản nhất (ILIKE là phiên bản không phân biệt chữ hoa chữ thường của LIKE). Chúng khá phổ biến trong cơ sở dữ liệu quan hệ. LIKE so sánh các giá trị cột với một chuỗi mẫu nhất định. Các ký tự % và _ là các ký tự đại diện: % khớp với bất kỳ số lượng ký tự nào trong khi _ khớp với chính xác một ký tự.
SELECT title FROM movies WHERE title ILIKE 'stardust%';
title
-------------------
Stardust
Stardust Memories
Nếu chúng ta muốn chắc chắn chuỗi con stardust không ở cuối chuỗi, chúng ta có thể sử dụng ký tự gạch dưới (_) như một mẹo.
SELECT title FROM movies WHERE title ILIKE 'stardust_%';
title
-------------------
Stardust Memories
Điều này hữu ích trong các trường hợp cơ bản, nhưng LIKE chỉ giới hạn ở các ký tự đại diện đơn giản.
Regex
Một cú pháp khớp chuỗi mạnh mẽ hơn là một biểu thức chính quy (regex). Các biểu thức chính quy dần xuất hiện thường xuyên vì nhiều cơ sở dữ liệu hỗ trợ chúng. Có toàn bộ sách dành riêng cho việc viết các cách diễn đạt theo biểu thức regex — chủ đề quá rộng và phức tạp để trình bày sâu ở đây. Postgres phù hợp (hầu hết) với POSIX.
Trong Postgres, một biểu thức chính quy được quy ước bởi toán tử ~, với tùy chọn ! (có nghĩa là không khớp) và * (có nghĩa là không phân biệt chữ hoa chữ thường). Để đếm tất cả các phim không bắt đầu bằng 'the', truy vấn phân biệt chữ hoa chữ thường sau đây sẽ hoạt động. Các ký tự bên trong chuỗi là biểu thức chính quy.
SELECT COUNT(*) FROM movies WHERE title !~* '^the.*';
Bạn có thể lập chỉ mục các chuỗi cho mẫu khớp với các truy vấn trước đó bằng cách tạo chỉ mục text_pattern_ops, miễn là các giá trị được lập chỉ mục bằng chữ thường
CREATE INDEX movies_title_pattern ON movies (lower(title) text_pattern_ops);
Ở đây đã sử dụng text_pattern_ops vì tiêu đề có kiểu dữ liệu text. Nếu bạn cần lập chỉ mục varchars, char hoặc names, hãy sử dụng các thao tác liên quan: varchar_pattern_ops, bpchar_pattern_ops và name_pattern_
Khoảng cách Levenshtein
Levenshtein là một thuật toán so sánh chuỗi, so sánh mức độ giống nhau của hai chuỗi bằng bao nhiêu bước cần thiết để thay đổi chuỗi này thành chuỗi khác. Mỗi ký tự được thay thế, thiếu hoặc thêm được tính là một bước. Khoảng cách là tổng số bước đi. Trong PostgreSQL, hàm levenshtein() được cung cấp bởi gói fuzzystrmatch. Giả sử chúng ta có chuỗi "bat" và "fads"
SELECT levenshtein('bat', 'fads');
Khoảng cách Levenshtein là 3 vì để đi từ bat đến fats, ta đã thay thế hai chữ cái (b=>f, t=>d) và thêm một chữ cái (+s). Mỗi thay đổi làm tăng khoảng cách. Hãy xem ví dụ cho kết quả khoảng cách giảm dần khi hai chuỗi càng giống nhau. Tổng số giảm dần cho đến khi chúng bằng 0 (hai chuỗi bằng nhau)
SELECT levenshtein('bat', 'fad') fad,
levenshtein('bat', 'fat') fat,
levenshtein('bat', 'bat') bat;
fad | fat | bat
-----+-----+-----
2 | 1 | 0
Các thay đổi về kiểu chữ cũng tốn một điểm, vì vậy bạn có thể thấy tốt nhất là chuyển đổi tất cả các chuỗi thành cùng một kiểu chữ khi truy vấn. Điều này đảm bảo những khác biệt nhỏ sẽ không làm tăng khoảng cách quá mức.
SELECT movie_id, title FROM movies
WHERE levenshtein(lower(title), lower('a hard day nght')) <= 3;
movie_id | title
----------+--------------------
245 | A Hard Day's Night
Trigram
Trigram là một tập hợp gồm 3 ký tự liên tiếp được lấy ra từ một chuỗi. Chúng ta có thể đo mức độ giống nhau của 2 chuỗi bằng cách đếm số lượng trigram mà chúng dùng chung. Ý tưởng đơn giản này rất có hiệu quả để đo mức độ giống nhau của các từ trong nhiều ngôn ngữ tự nhiên. Muốn sử dụng Trigram trong Postgres, trước hết chúng ta cần cài extension pg_trgm
SELECT show_trgm('Avatar');
show_trgm
-------------------------------------
{" a"," av","ar ",ata,ava,tar,vat}
Tìm một chuỗi phù hợp cũng đơn giản như đếm số trigram phù hợp. Các chuỗi có nhiều cặp mactch nhau là giống nhau nhất. Nó hữu ích khi thực hiện tìm kiếm mà bạn thấy ổn với lỗi chính tả nhỏ hoặc thậm chí thiếu các từ nhỏ. Chuỗi càng dài, càng có nhiều trigram và càng có nhiều khả năng trùng khớp—chúng rất phù hợp với những thứ như tiêu đề phim vì chúng có độ dài tương đối giống nhau. Để bắt đầu, chúng ta sẽ tạo một chỉ mục trigram đối với tên phim, bằng cách sử dụng Generalized Index Search Tree (GIST), một API chỉ mục chung do công cụ PostgreSQL cung cấp.
CREATE INDEX movies_title_trigram ON movies
USING gist (title gist_trgm_ops);
Bây giờ bạn có thể truy vấn với một vài lỗi chính tả mà vẫn nhận được kết quả tốt.
SELECT title
FROM movies
WHERE title % 'Avatre';
title
---------
Avatar
Trigrams là một lựa chọn tuyệt vời để chấp nhận đầu vào của người dùng mà không làm giảm các truy vấn với độ phức tạp của ký tự đại diện.
Full-Text
Tiếp theo, chúng ta cũng muốn cho phép người dùng thực hiện các tìm kiếm dạng full-text dựa trên các từ phù hợp, ngay cả khi những từ khóa đó là đa dạng. Nếu người dùng muốn tìm kiếm một số từ nhất định trong tiêu đề phim nhưng chỉ có thể nhớ một số trong số chúng, Postgres hỗ trợ xử lý ngôn ngữ tự nhiên đơn giản.
TSVector và TSQuery
Hãy cùng tìm kiếm một bộ phim chứa các từ 'night & day'. Đây là một công việc hoàn hảo để tìm kiếm văn bản bằng cách sử dụng @@ - truy vấn full-text
SELECT title
FROM movies
WHERE title @@ 'night & day';
title
-------------------------------
A Hard Day's Night
Six Days Seven Nights
Long Day's Journey Into Night
Truy vấn trả về các tiêu đề như A Hard Day’s Night, mặc dù ở đây là từ Day's và thực tế là hai từ không đúng thứ tự trong truy vấn. Toán tư @@ chuyển đổi trường title thành TSVector và chuyển đổi truy vấn thành một tsquery.
Tsvector là một kiểu dữ liệu phân tách một chuỗi thành một mảng (hoặc một vectơ) được tìm kiếm theo truy vấn đã cho, trong khi tsquery đại diện cho một truy vấn bằng một số ngôn ngữ, như tiếng Anh hoặc tiếng Pháp. Ngôn ngữ tương ứng với một từ điển (mà chúng ta sẽ thấy nhiều hơn trong một vài đoạn văn). Truy vấn trước tương đương với truy vấn sau (nếu ngôn ngữ hệ thống của bạn được đặt thành tiếng Anh):
SELECT title
FROM movies
WHERE to_tsvector(title) @@ to_tsquery('english', 'night & day');
Bạn có thể xem cách vectơ và truy vấn phân tách các giá trị bằng cách chạy các hàm chuyển đổi trên các chuỗi.
SELECT to_tsvector('A Hard Day''s Night'),
to_tsquery('english', 'night & day');
to_tsvector | to_tsquery
---------------------------+-----------------
'day':3 'hard':2 'night':5 | 'night' & 'day'
Các giá trị trên tsvector được gọi là từ vựng và được kết hợp với vị trí của chúng trong cụm từ đã cho. Bạn có thể nhận thấy tsvector cho A Hard Day’s Night không chứa từ vựng a. Hơn nữa, những từ tiếng Anh đơn giản như a sẽ bị thiếu nếu bạn cố truy vấn như sau
SELECT *
FROM movies
WHERE title @@ to_tsquery('english', 'a');
Các từ phổ biến như a được gọi là stop word và thường không hữu ích để thực hiện các truy vấn. Từ điển tiếng Anh đã được trình phân tích cú pháp sử dụng để chuẩn hóa chuỗi thành các thành phần tiếng Anh hữu ích. Trong cửa sổ console của mình, bạn có thể xem đầu ra của các từ dừng trong thư mục tsearch_data tiếng Anh.
$ cat `pg_config --sharedir`/tsearch_data/english.stop
Chúng ta có thể xóa a khỏi danh sách hoặc có thể sử dụng một từ điển khác, chẳng hạn như từ điển đơn giản chỉ chia chuỗi theo các ký tự không phải từ và biến chúng thành chữ thường. So sánh hai vectơ này:
SELECT to_tsvector('english', 'A Hard Day''s Night');
to_tsvector
----------------------------
'day':3 'hard':2 'night':5
SELECT to_tsvector('simple', 'A Hard Day''s Night');
to_tsvector
----------------------------------------
'a':1 'day':3 'hard':2 'night':5 's':4
Rất đơn giản, bạn có thể truy xuất bất kỳ phim nào chứa từ vựng a
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
PostgreSQL (hay chỉ “Postgres”) là một hệ thống quản lý cơ sở dữ liệu quan hệ (viết tắt là RDBMS). Cơ sở dữ liệu quan hệ là các hệ thống dựa trên lý thuyết tập hợp, trong đó dữ liệu được lưu trữ trong các bảng hai chiều bao gồm các hàng dữ liệu và các cột với kiểu dữ liệu được quy định cụ thể, chặt chẽ
Bài trước chúng đã giới thiệu về cách khai báo bảng, điền dữ liệu vào bảng, cập nhật và xóa hàng cũng như thực hiện các thao tác truy vấn cơ bản. Bài này chúng ta sẽ tìm hiểu sâu hơn về các cách mà PostgreSQL có thể truy vấn dữ liệu.
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên