Một số hệ quản trị cơ sở dữ liệu phổ biến – Phần 2: Tiếp tục với PostgreSQL

Bài trước đã giới thiệu về cách khai báo bảng, điền dữ liệu vào bảng, cập nhật và xóa hàng cũng như thực hiện các thao tác truy vấn cơ bản. Bài này chúng ta sẽ tìm hiểu sâu hơn về các cách mà PostgreSQL có thể truy vấn dữ liệu. Chúng ta sẽ xem cách nhóm các giá trị tương tự (group), thực thi mã trên server và tạo bảng dữ liệu tùy chỉnh bằng cách sử dụng view và rule.
Aggregate Functions
Truy vấn tổng hợp nhóm kết quả từ một số hàng theo một số tiêu chí chung. Nó có thể đơn giản như đếm số hàng trong một bảng hoặc tính trung bình cộng của một số cột số. Chúng là những công cụ SQL mạnh mẽ và cũng rất thú vị.
Hãy thử một số hàm tổng hợp, nhưng trước tiên, sẽ cần thêm một số dữ liệu trong cơ sở dữ liệu của bài trước. Nhập quốc gia vào bảng countries, thành phố vào bảng cities và địa chỉ của chính bạn làm địa điểm (trong bài đặt tên là My Place). Sau đó, thêm một vài bản ghi vào bảng events.
Đây là một mẹo SQL nhanh: Thay vì nhập venue_id một cách rõ ràng, bạn có thể SELECT nó. Nếu Moby đang chơi ở Crystal Ballroom, hãy nhập venue_id như thế này:
INSERT INTO events (title, starts, ends, venue_id)
VALUES ('Moby', '2018-02-06 21:00', '2018-02-06 23:00', (
SELECT venue_id
FROM venues
WHERE name = 'Crystal Ballroom'
)
);
Điền dữ liệu sau vào bảng events (để nhập Valentine Day's trong PostgreSQL, bạn có thể thay dấu nháy đơn bằng hai dấu nháy đơn, chẳng hạn như Heaven''s Gate):
title | starts | ends | venue
-----------------+---------------------+---------------------+---------------
Wedding | 2018-02-26 21:00:00 | 2018-02-26 23:00:00 | Voodoo Doughnut
Dinner with Mom | 2018-02-26 18:00:00 | 2018-02-26 20:30:00 | My Place
Valentine's Day | 2018-02-14 00:00:00 | 2018-02-14 23:59:00
Với dữ liệu đã được thiết lập, hãy thử một số truy vấn tổng hợp. Hàm tổng hợp đơn giản nhất là hàm count(), khá dễ hiểu. Đếm tất cả các tiêu đề có chứa từ Day (lưu ý: % là ký tự đại diện cho các tìm kiếm LIKE), bạn sẽ nhận được giá trị là 3
SELECT count(title) FROM events WHERE title LIKE '%Day%';
Để biết thời gian bắt đầu đầu tiên và thời gian kết thúc cuối cùng của tất cả các sự kiện tại phòng Crystal Ball, hãy sử dụng min() (trả về giá trị nhỏ nhất) và max() (trả về giá trị lớn nhất).
SELECT min(starts), max(ends)
FROM events INNER JOIN venues
ON events.venue_id = venues.venue_id
WHERE venues.name = 'Crystal Ballroom';
min | max
---------------------+---------------------
2018-02-06 21:00:00 | 2018-02-06 23:00:00
Các hàm tổng hợp rất hữu ích nhưng lại bị hạn chế. Nếu muốn đếm tất cả các sự kiện tại mỗi địa điểm,ta có thể viết như sau cho mỗi venue_id:
SELECT count(*) FROM events WHERE venue_id = 1;
SELECT count(*) FROM events WHERE venue_id = 2;
SELECT count(*) FROM events WHERE venue_id = 3;
SELECT count(*) FROM events WHERE venue_id IS NULL;
Điều này sẽ rất tẻ nhạt (thậm chí kinh khủng) khi số lượng địa điểm tăng lên. Đây là lúc lệnh GROUP BY phát huy tác dụng.
Group By
GROUP BY là lối tắt để chạy tất cả các truy vấn trước đó cùng một lúc. Với GROUP BY, bạn yêu cầu Postgres đặt các hàng thành các nhóm và sau đó thực hiện một số chức năng tổng hợp (chẳng hạn như count()) trên các nhóm đó.
SELECT venue_id, count(*)
FROM events
GROUP BY venue_id;
venue_id | count
----------+-------
1 | 1
2 | 2
3 | 1
4 | 3
Đó là một ý tưởng hay, nhưng liệu rằng ta có thể lọc theo hàm count() không? Tất nhiên là có!. Điều kiện GROUP BY có từ khóa lọc riêng: HAVING. HAVING giống như mệnh đề WHERE, ngoại trừ nó có thể lọc theo các hàm tổng hợp (trong khi WHERE thì không).
Truy vấn sau SELECT các địa điểm phổ biến nhất (những địa điểm có hai sự kiện trở lên):
SELECT venue_id
FROM events
GROUP BY venue_id
HAVING count(*) >= 2 AND venue_id IS NOT NULL;
venue_id | count
----------+-------
2 | 2
Bạn có thể sử dụng GROUP BY mà không cần bất kỳ hàm tổng hợp nào. Nếu bạn gọi SELECT... FROM...GROUP BY trên một cột, bạn chỉ nhận được các giá trị duy nhất
SELECT venue_id FROM events GROUP BY venue_id;
Kiểu group này phổ biến đến mức SQL đã bổ sung cho nó một từ khóa DISTINCT.
SELECT DISTINCT venue_id FROM events;
Kết quả của cả hai truy vấn sẽ giống hệt nhau.
Window Functions
Nếu trước đây bạn đã thực hiện bất kỳ loại công việc với cơ sở dữ liệu quan hệ, thì có thể bạn đã quen thuộc với các truy vấn tổng hợp. Chúng là một thế mạnh chủ lực của SQL. Mặt khác, window function không quá phổ biến (PostgreSQL là một trong số ít cơ sở dữ liệu nguồn mở triển khai chúng).
Các window function tương tự như các truy vấn GROUP BY ở chỗ chúng cho phép bạn chạy các hàm tổng hợp trên nhiều hàng. Sự khác biệt là chúng cho phép bạn sử dụng các hàm tổng hợp tích hợp sẵn mà không yêu cầu nhóm từng trường thành một hàng
Nếu bạn thử chọn cột tiêu đề mà không nhóm theo nó, bạn có thể gặp lỗi.
SELECT title, venue_id, count(*)
FROM events
GROUP BY venue_id;
ERROR: column "events.title" must appear in the GROUP BY clause or \
be used in an aggregate function
Chúng ta đang đếm các hàng theo venue_id và trong trường hợp Fight Club và Wedding, ta có hai tiêu đề cho một địa điểm duy nhất. Postgres không biết nên hiển thị tiêu đề nào.
Trong khi mệnh đề GROUP BY sẽ trả về một bản ghi cho mỗi giá trị nhóm phù hợp, thì window function, không thu gọn kết quả trên mỗi nhóm, có thể trả về một bản ghi riêng cho mỗi hàng. Để trực quan, xem hình dưới đây.

Hãy xem một ví dụ về sự hấp dẫn mà các window function cố gắng đạt được. Các window function trả về tất cả các kết quả phù hợp và sao chép kết quả của bất kỳ hàm tổng hợp nào.
SELECT title, count(*) OVER (PARTITION BY venue_id) FROM events;
title | count
-------------+-------
Moby | 1
Fight Club | 1
House Party | 3
House Party | 3
House Party | 3
(5 rows)
Hãy nghĩ về PARTITION BY giống như GROUP BY, nhưng thay vì nhóm các kết quả bên ngoài danh sách thuộc tính SELECT (và do đó kết hợp các kết quả thành ít hàng hơn), nó trả về các giá trị được nhóm như bất kỳ trường nào khác (tính toán trên biến được nhóm nhưng nếu không thì chỉ là một thuộc tính khác). Hay theo cách nói của SQL, nó trả về kết quả của một hàm tổng hợp OVER PARTITION của tập kết quả
Transactions
Transactions (giao dịch) đóng vai trò rất lớn trong việc đảm bảo tính nhất quán của cơ sở dữ liệu quan hệ. Tất cả hoặc không có gì, đó là phương châm của transaction. Các transaction đảm bảo rằng mọi lệnh của một tập hợp đều được thực thi. Nếu bất cứ điều gì thất bại trong quá trình thực hiện, tất cả các lệnh sẽ được khôi phục như thể chúng chưa từng xảy ra.
Các giao dịch PostgreSQL tuân theo tuân thủ ACID, viết tắt của:
- Atomic - Nguyên tử (hoặc tất cả các hoạt động thành công hoặc không hoạt động nào)
- Consistent - Nhất quán (dữ liệu sẽ luôn ở trạng thái tốt và không bao giờ ở trạng thái không nhất quán
- Isolated - Cô lập (các giao dịch không can thiệp lẫn nhau
- Durable·- Bền vững (giao dịch đã cam kết là an toàn, ngay cả sau khi máy chủ gặp sự cố)
Ở đây chúng ta nên lưu ý rằng tính nhất quán trong ACID khác với tính nhất quán trong CAP
Chúng tôi có thể bọc bất kỳ giao dịch nào trong khối BEGIN TRANSACTION. Để xác minh tính nguyên tử, bạn sẽ hủy giao dịch bằng lệnh ROLLBACK.
BEGIN TRANSACTION;
DELETE FROM events;
ROLLBACK;
SELECT * FROM events;
Sau khi thực thị đoạn lệnh trên tất cả event của bạn vẫn còn. Giao dịch rất hữu ích khi bạn đang sửa đổi hai bảng mà bạn không muốn đồng bộ hóa. Ví dụ kinh điển là hệ thống ghi nợ/tín dụng cho ngân hàng, nơi tiền được chuyển từ tài khoản này sang tài khoản khác:
BEGIN TRANSACTION;
UPDATE account SET total=total+5000.0 WHERE account_id=1337;
UPDATE account SET total=total-5000.0 WHERE account_id=45887;
END;
Nếu có điều gì đó xảy ra giữa hai câu lệnh update, ngân hàng này sẽ mất năm nghìn đồng. Nhưng khi được bao bọc trong một khối giao dịch, bản cập nhật ban đầu sẽ bị khôi phục, ngay cả khi máy chủ xảy ra sự cố
Stored Procedures
Mọi lệnh mà chúng ta đã thấy cho đến bây giờ đều mang tính khai báo theo nghĩa là chúng ta có thể nhận được tập kết quả mong muốn chỉ bằng cách sử dụng SQL (bản thân nó đã khá mạnh). Nhưng đôi khi cơ sở dữ liệu không cung cấp mọi thứ bạn cần một cách tự nhiên và chúng đòi hỏi một vài tham số cần phải khai báo. Tuy nhiên, tại thời điểm đó, bạn cần quyết định nơi code sẽ chạy. Nó nên chạy trong Postgres hay nên chạy ở phía ứng dụng
Nếu bạn quyết định muốn cơ sở dữ liệu thực hiện toàn bộ, Postgres sẽ cung cấp các thủ tục được lưu trữ - stored procedure. Các stored procedure cực kỳ mạnh mẽ và có thể được sử dụng để thực hiện rất nhiều tác vụ, từ thực hiện các phép toán phức tạp không được hỗ trợ trong SQL đến kích hoạt trigger đến xác thực và kiểm tra dữ liệu trước khi ghi vào bảng và hơn thế nữa . Một mặt, các thủ tục được lưu trữ có thể mang lại hiệu năng rất lớn. Nhưng chi phí kiến trúc có thể cao (và đôi khi không đáng). Bạn có thể tránh truyền hàng nghìn hàng tới một ứng dụng khách (điều này gây ra hiện tượng "nghẽn cổ chai"), nhưng bạn cũng đã ràng buộc ứng dụng của mình với cơ sở dữ liệu này. Và do đó, không nên đưa ra quyết định sử dụng các thủ tục được lưu trữ một cách dễ dàng
Bỏ qua một bên, hãy tạo một thủ tục - procedure (hoặc FUNCTION) giúp đơn giản hóa việc INSERT một event mới tại một địa điểm mà không cần đến venue_id. Đây là những gì procedure sẽ cần phải hoàn thành: nếu địa điểm không tồn tại, địa điểm đó sẽ được tạo trước rồi mới được tham chiếu trong sự kiện mới. Procedure này cũng sẽ trả về một giá trị Boolean cho biết liệu một địa điểm mới có được thêm vào hay không.
CREATE OR REPLACE FUNCTION add_event(
title text,
starts timestamp,
ends timestamp,
venue text,
postal varchar(9),
country char(2))
RETURNS boolean AS $$
DECLARE
did_insert boolean := false;
found_count integer;
the_venue_id integer;
BEGIN
SELECT venue_id INTO the_venue_id
FROM venues v
WHERE v.postal_code=postal AND v.country_code=country AND v.name ILIKE venue
LIMIT 1;
IF the_venue_id IS NULL THEN
INSERT INTO venues (name, postal_code, country_code)
VALUES (venue, postal, country)
RETURNING venue_id INTO the_venue_id;
did_insert := true;
END IF;
-- Note: this is a notice, not an error as in some programming languages
RAISE NOTICE 'Venue found %', the_venue_id;
INSERT INTO events (title, starts, ends, venue_id)
VALUES (title, starts, ends, the_venue_id);
RETURN did_insert;
END;
$$ LANGUAGE plpgsql;
Bạn có thể nhập tệp bên ngoài này vào lược đồ hiện tại bằng cách sử dụng dòng lệnh sau (nếu bạn không muốn nhập tất cả mã đó).
7dbs=# \i add_event.sql
Thủ tục được lưu trữ này được chạy dưới dạng câu lệnh SELECT.
SELECT add_event('House Party', '2018-05-03 23:00',
'2018-05-04 02:00', 'Run''s House', '97206', 'us');
Chạy nó sẽ trả về t (true) vì đây là lần đầu tiên sử dụng địa điểm Run's House. Điều này tránh việc hai lệnh SQL được thực hiện hai lần giữa ứng dụng máy chủ vào cơ sở dữ liệu (SELECT và sau đó là INSERT) và thay vào đó chỉ thực hiện một lệnh.
Ngôn ngữ để viết thủ tục là PL/pgSQL (viết tắt của Procedural Language/PostgreSQL). Bài viết này không giới thiệu chi tiết về toàn bộ ngôn ngữ lập trình, nhưng bạn có thể đọc thêm về nó trong tài liệu PostgreSQL trực tuyến
Ngoài PL/pgSQL, Postgres hỗ trợ thêm ba ngôn ngữ để viết thủ tục: Tcl (PL/Tcl), Perl (PL/Perl) và Python (PL/Python). Nhiều người đã viết các tiện ích mở rộng cho hơn chục tiện ích khác, bao gồm Ruby, Java, PHP, Scheme và các tiện ích khác được liệt kê trong tài liệu công khai. Hãy thử lệnh shell này:
$ createlang 7dbs --list
Nó sẽ liệt kê các ngôn ngữ được cài đặt trong cơ sở dữ liệu của bạn. Lệnh createlang cũng được sử dụng để thêm ngôn ngữ mới, bạn có thể tìm thấy trên mạng
Triggers
Trigger tự động kích hoạt các thủ tục được lưu trữ khi một số sự kiện xảy ra, chẳng hạn như chèn hoặc cập nhật. Chúng cho phép cơ sở dữ liệu thực thi một số hành vi cần thiết để đáp ứng với việc thay đổi dữ liệu
Hãy tạo một hàm PL/pgSQL mới để ghi nhật ký bất cứ khi nào một sự kiện được cập nhật (chúng ta muốn chắc chắn rằng không ai thay đổi một event và chối bỏ việc thay đổi này). Đầu tiên, tạo một bảng nhật ký để lưu trữ các thay đổi trên bảng events. Khóa chính không cần thiết ở đây vì nó chỉ là nhật ký.
CREATE TABLE logs (
event_id integer,
old_title varchar(255),
old_starts timestamp,
old_ends timestamp,
logged_at timestamp DEFAULT current_timestamp
);
Tiếp theo, xây dựng một chức năng để chèn dữ liệu cũ vào nhật ký. Biến OLD đại diện cho hàng sắp được thay đổi (NEW đại diện cho một hàng sắp tới). Xuất thông báo ra bàn điều khiển với event_id trước khi trả về kết quả
CREATE OR REPLACE FUNCTION log_event() RETURNS trigger AS $$
DECLARE
BEGIN
INSERT INTO logs (event_id, old_title, old_starts, old_ends)
VALUES (OLD.event_id, OLD.title, OLD.starts, OLD.ends);
RAISE NOTICE 'Someone just changed event #%', OLD.event_id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Cuối cùng, tạo trigger để ghi lại các thay đổi sau khi bất kỳ hàng nào được cập nhật.
CREATE TRIGGER log_events
AFTER UPDATE ON events
FOR EACH ROW EXECUTE PROCEDURE log_event();
Hãy thử thay đổi 1 sự kiện
UPDATE events
SET ends='2018-05-04 01:00:00'
WHERE title='House Party';
NOTICE: Someone just changed event #9
SELECT event_id, old_title, old_ends, logged_at
FROM logs;
event_id | old_title | old_ends | logged_at
---------+-------------+---------------------+------------------------
9 | House Party | 2018-05-04 02:00:00 | 2017-02-26 15:50:31.939
Trigger cũng có thể được tạo trước khi cập nhật và trước hoặc sau khi chèn
Views
Sẽ thật tuyệt nếu bạn có thể sử dụng kết quả của một truy vấn phức tạp giống như bất kỳ bảng nào khác phải không? Chà, đó chính xác là những gì View mang lại. Không giống như các thủ tục được lưu trữ, các hàm này không được thực thi mà là các truy vấn bí danh. Giả sử rằng chúng tôi chỉ muốn xem các ngày lễ có chứa từ Day và không có địa điểm. Chúng ta có thể tạo một View như thế này:
CREATE VIEW holidays AS
SELECT event_id AS holiday_id, title AS name, starts AS date
FROM events
WHERE title LIKE '%Day%' AND venue_id IS NULL;
Tạo một view thực sự đơn giản như viết một truy vấn và thêm tiền tố vào nó bằng CREATE VIEW some_view_name AS. Bây giờ bạn có thể truy vấn holidays giống như bất kỳ bảng nào khác. Dưới vỏ bọc, đó là bảng event. Để thử nghiệm, hãy thêm Valentine’s Day vào 2018-02-14 vào các events và truy vấn view holidays
SELECT name, to_char(date, 'Month DD, YYYY') AS date
FROM holidays
WHERE date <= '2018-04-01';
name | date
------------------+--------------------
April Fools Day | April 01, 2018
Valentine's Day | February 14, 2018
View là công cụ mạnh mẽ để truy vấn dữ liệu được truy vấn phức tạp theo cách đơn giản. Truy vấn có thể là một biển phức tạp bên dưới, nhưng tất cả những gì bạn thấy là một bảng.
Nếu bạn muốn thêm một cột mới vào view holidays, cột đó sẽ phải xuất phát từ bảng bên dưới. Hãy thay đổi bảng sự kiện để có một mảng màu liên quan.
ALTER TABLE events
ADD colors text ARRAY;
Vì các ngày lễ phải có màu liên kết với chúng, hãy cập nhật truy vấn VIEW để chứa mảng màu.
CREATE OR REPLACE VIEW holidays AS
SELECT event_id AS holiday_id, title AS name, starts AS date, colors
FROM events
WHERE title LIKE '%Day%' AND venue_id IS NULL;
Bây giờ, vấn đề là đặt một mảng hoặc chuỗi màu cho ngày lễ bạn chọn. Thật không may, bạn không thể cập nhật View trực tiếp.
UPDATE holidays SET colors = '{"red","green"}' where name = 'Christmas Day';
ERROR: cannot update a view
HINT: You need an unconditional ON UPDATE DO INSTEAD rule.
Có vẻ như chúng ta cần RULE thay vì VIEW.
RULEs
RULE là mô tả về cách thay đổi cây truy vấn đã phân tích cú pháp. Mỗi khi Postgres chạy một câu lệnh SQL, nó sẽ phân tích cú pháp câu lệnh đó thành một cây truy vấn (thường được gọi chung là cây cú pháp trừu tượng
Các toán tử và giá trị trở thành các nhánh và lá trong cây, và cây được đi lại, cắt tỉa và theo các cách khác được chỉnh sửa trước khi thực thi. Cây này được tùy chọn viết lại theo Postgres rule, trước khi được gửi tới trình lập kế hoạch truy vấn - query planner (công cụ này cũng viết lại cây để chạy một cách tối ưu) và gửi lệnh cuối cùng này để thực thi.
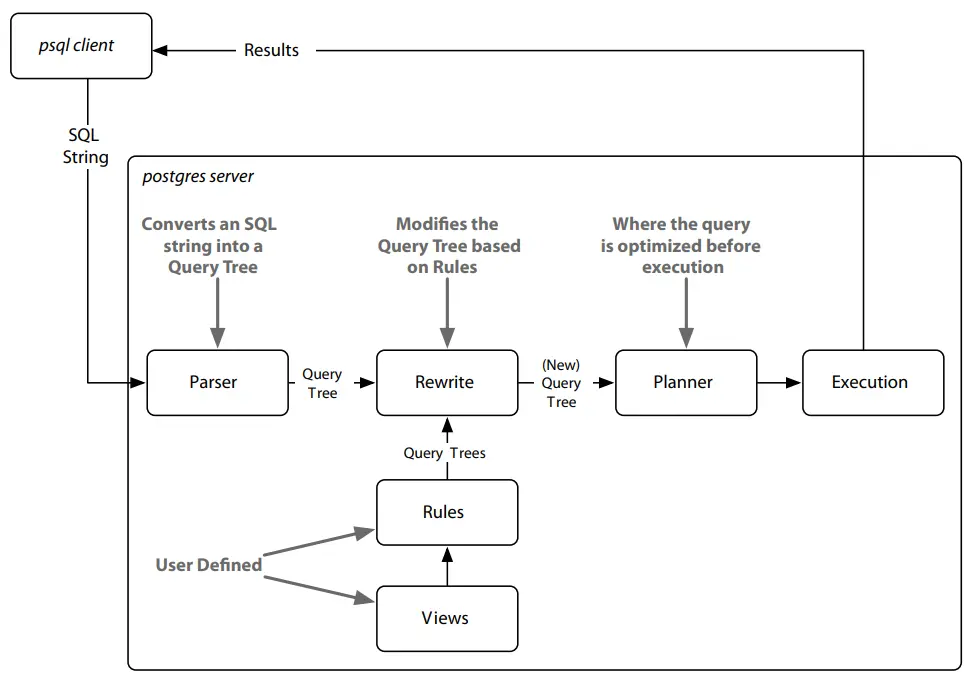
Thật ra, một VIEW chẳng hạn như holiday là một RULE. Ta thể chứng minh điều này bằng cách xem kế hoạch thực hiện của chế độ xem kỳ nghỉ bằng cách sử dụng lệnh EXPLAIN (chú ý Bộ lọc là mệnh đề WHERE và Đầu ra là danh sách cột).
EXPLAIN VERBOSE
SELECT *
FROM holidays;
QUERY PLAN
-----------------------------------------------------------------------------
Seq Scan on public.events (cost=0.00..1.01 rows=1 width=44)
Output: events.event_id, events.title, events.starts, events.colors
Filter: ((events.venue_id IS NULL) AND
((events.title)::text ~~ '%Day%'::text)
So sánh điều đó với việc chạy EXPLAIN VERBOSE trên truy vấn mà từ đó chúng tôi đã tạo View holidays. Chúng giống hệt nhau về mặt chức năng.
EXPLAIN VERBOSE
SELECT event_id AS holiday_id,
title AS name, starts AS date, colors
FROM events
WHERE title LIKE '%Day%' AND venue_id IS NULL;
QUERY PLAN
-----------------------------------------------------------------------------
Seq Scan on public.events (cost=0.00..1.04 rows=1 width=57)
Output: event_id, title, starts, colors
Filter: ((events.venue_id IS NULL) AND
((events.title)::text ~~ '%Day%'::text))
Vì vậy, để cho phép cập nhật đối với view holidays, cần tạo một RULE cho Postgres biết phải làm gì với một UPDATE. RULE sẽ nắm bắt các bản cập nhật cho view holidays và thay vào đó chạy bản cập nhật trên các events, lấy các giá trị từ các mối quan hệ giả NEW và OLD. NEW về mặt chức năng đóng vai trò là mối quan hệ chứa các giá trị đang đặt, trong khi OLD chứa các giá trị đang truy vấn.
CREATE RULE update_holidays AS ON UPDATE TO holidays DO INSTEAD
UPDATE events
SET title = NEW.name,
starts = NEW.date,
colors = NEW.colors
WHERE title = OLD.name;
Với rule, bây giờ ta có thể cập nhật các holidays trực tiếp
UPDATE holidays SET colors = '{"red","green"}' where name = 'Christmas Day';
Tiếp theo, hãy chèn New Years Day - 2013-01-01 vào holidays. Như mong đợi, cần một rule cho điều đó.
CREATE RULE insert_holidays AS ON INSERT TO holidays DO INSTEAD
INSERT INTO ...
Hãy sẽ tiếp tục từ đây, nhưng nếu bạn muốn "chơi lớn" hơn với RULE, hãy thử thêm RULE DELETE.
Crosstab
Phần cuối cùng trong bài hôm nay, hãy xây dựng lịch sự kiện hàng tháng, trong đó mỗi tháng trong năm dương lịch sẽ đếm số sự kiện trong tháng đó. Loại hoạt động này thường được thực hiện bởi một bảng tổng hợp. Các cấu trúc này “xoay trục” dữ liệu được nhóm xung quanh một số đầu ra khác, trong trường hợp này là danh sách các tháng. Ta sẽ xây dựng bảng tổng hợp bằng cách sử dụng chức năng crosstab().
Bắt đầu bằng cách tạo một truy vấn để đếm số lượng sự kiện mỗi tháng mỗi năm. PostgreSQL cung cấp một hàm extract() trả về một số trường con từ một ngày hoặc dấu thời gian, hỗ trợ cho việc nhóm của chúng ta
SELECT extract(year from starts) as year,
extract(month from starts) as month, count(*)
FROM events
GROUP BY year, month
ORDER BY year, month;
Để sử dụng crosstab(), truy vấn phải trả về ba cột: rowid, category và value. Chúng ta sẽ sử dụng năm làm ID, có nghĩa là các trường khác là danh mục (tháng) và giá trị (số lượng)
CREATE TEMPORARY TABLE month_count(month INT);
INSERT INTO month_count VALUES (1),(2),(3),(4),(5),
(6),(7),(8),(9),(10),(11),(12);
Bây giờ chúng tôi đã sẵn sàng để gọi crosstab() với hai truy vấn trên
SELECT * FROM crosstab(
'SELECT extract(year from starts) as year,
extract(month from starts) as month, count(*)
FROM events
GROUP BY year, month
ORDER BY year, month',
'SELECT * FROM month_count'
);
ERROR: a column definition list is required for functions returning "record"
Ối. Đã xảy ra lỗi. Lỗi khó hiểu này về cơ bản nói rằng hàm đang trả về một tập hợp các bản ghi (hàng) nhưng không biết cách gắn nhãn cho chúng. Trên thực tế, nó thậm chí còn không biết chúng là loại dữ liệu gì.
Hãy nhớ rằng, bảng tổng hợp đang sử dụng tháng làm danh mục, nhưng những tháng đó chỉ là số nguyên. Vì vậy, cần định nghĩa chúng như thế này:
SELECT * FROM crosstab(
'SELECT extract(year from starts) as year,
extract(month from starts) as month, count(*)
FROM events
GROUP BY year, month
ORDER BY year, month',
'SELECT * FROM month_count'
) AS (
year int,
jan int, feb int, mar int, apr int, may int, jun int,
jul int, aug int, sep int, oct int, nov int, dec int
) ORDER BY YEAR;
Chúng tôi có một cột năm (là ID hàng) và mười hai cột nữa biểu thị các tháng.
year | jan | feb | mar | apr | may | jun | jul | aug | sep | oct | nov | dec
-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----
2018 | | 5 | | 1 | 1 | | | | | | | 1
Tóm tắt
Bài này đã hoàn tất một phần những thứ cơ bản liên quan đến PostgreSQL. Chúng ta bắt đầu thấy là Postgres không chỉ là một máy chủ để lưu trữ các kiểu dữ liệu cố định và truy vấn chúng. Thay vào đó, nó là một công cụ quản lý dữ liệu mạnh mẽ có thể định dạng lại dữ liệu đầu ra, lưu trữ các kiểu dữ liệu đa dạng như mảng, thực thi logic và cung cấp đủ khả năng để viết lại các thứ tự thực thi truy vấn.
Bài viết thuộc các danh mục
Bài viết được gắn thẻ
BÌNH LUẬN (0)
Hãy là người đầu tiên để lại bình luận cho bài viết !!
Hãy đăng nhập để tham gia bình luận. Nếu bạn chưa có tài khoản hãy đăng ký để tham gia bình luận với mình
Bài viết liên quan
PostgreSQL (hay chỉ “Postgres”) là một hệ thống quản lý cơ sở dữ liệu quan hệ (viết tắt là RDBMS). Cơ sở dữ liệu quan hệ là các hệ thống dựa trên lý thuyết tập hợp, trong đó dữ liệu được lưu trữ trong các bảng hai chiều bao gồm các hàng dữ liệu và các cột với kiểu dữ liệu được quy định cụ thể, chặt chẽ
Danh Mục
Bài Viết Mới
Các phần trước đã đề cập đến kiến trúc luồng dữ liệu. Chúng ta đã tìm hiểu cách dữ liệu được sắp xếp trong kho lưu trữ dữ liệu và cách dữ liệu di chuyển trong hệ thống kho dữ liệu. Khi bạn đã chọn một kiến trúc luồng dữ liệu nhất định, thì bạn cần thiết kế kiến trúc hệ thống, đó là sự sắp xếp và kết nối vật lý giữa các máy chủ, mạng, phần mềm, hệ thống lưu trữ và clients.
RSA (Rivest-Shamir-Adleman) là một thuật toán mã hóa khóa công khai phổ biến nhất trên thế giới. Nó được đặt tên theo tên ba nhà toán học: Ronald Rivest, Adi Shamir và Leonard Adleman, người đã phát minh ra nó vào năm 1977. Thuật toán RSA là một phần quan trọng của hệ thống mật mã công khai, cho phép mã hóa và giải mã dữ liệu một cách an toàn và bảo mật.
Một hệ thống kho dữ liệu có hai kiến trúc chính: kiến trúc luồng dữ liệu và kiến trúc hệ thống. Kiến trúc luồng dữ liệu là về cách sắp xếp các kho lưu trữ dữ liệu trong kho dữ liệu và cách dữ liệu truyền từ hệ thống nguồn đến người dùng thông qua các kho lưu trữ dữ liệu này. Kiến trúc hệ thống là về cấu hình vật lý của máy chủ, mạng, phần mềm, bộ lưu trữ và máy khách. Bài này sẽ thảo luận về kiến trúc luồng dữ liệu trước và sau đó là kiến trúc hệ thống
Kho dữ liệu là một hệ thống truy xuất và hợp nhất dữ liệu định kỳ từ các hệ thống nguồn vào kho lưu trữ dữ liệu theo chiều hoặc chuẩn hóa. Nó thường lưu giữ nhiều năm và được truy vấn về thông tin kinh doanh hoặc các hoạt động phân tích khác. Nó thường được cập nhật theo đợt, không phải mỗi khi giao dịch xảy ra trong hệ thống nguồn.
Trong CouchDB, view là một cửa sổ vào các tài liệu có trong cơ sở dữ liệu. View là cách chính mà tài liệu được truy cập trong tất cả các trường hợp trừ các trường hợp đặc biệt. Trong bài này chúng ta sẽ làm quen với việc khởi tạo và truy vấn với view
About Me

Xin chào các bạn, mình là Dương Nguyễn Tấn Hòa - tác giả blog Cafe Dev Code
Blog này là nơi mình chia sẻ các nội dung xoay quanh cuộc sống của developer, nó không chỉ có nội dung về kỹ thuật, mà còn là những lời chia sẻ vể những câu chuyện và kinh nghiệm của mình đúc kết được, với hy vọng mang đến cho bạn những điều thú vị về cuộc sống của một lập trình viên